BentoML
v1.3.14

? Crie APIs de inferência de modelo e sistemas de atendimento multimodelo com qualquer modelo de IA personalizado ou de código aberto. Junte-se à nossa comunidade no Slack!

BentoML é uma biblioteca Python para construção de sistemas de atendimento online otimizados para aplicativos de IA e inferência de modelos.
Instale o BentoML:
# Requires Python≥3.9
pip install -U bentoml
Defina APIs em um arquivo service.py .
from __future__ import annotations
import bentoml
@ bentoml . service (
resources = { "cpu" : "4" }
)
class Summarization :
def __init__ ( self ) -> None :
import torch
from transformers import pipeline
device = "cuda" if torch . cuda . is_available () else "cpu"
self . pipeline = pipeline ( 'summarization' , device = device )
@ bentoml . api ( batchable = True )
def summarize ( self , texts : list [ str ]) -> list [ str ]:
results = self . pipeline ( texts )
return [ item [ 'summary_text' ] for item in results ]Execute o código de serviço localmente (servindo em http://localhost:3000 por padrão):
pip install torch transformers # additional dependencies for local run
bentoml serve service.py:SummarizationAgora você pode executar inferência no seu navegador em http://localhost:3000 ou com um script Python:
import bentoml
with bentoml . SyncHTTPClient ( 'http://localhost:3000' ) as client :
summarized_text : str = client . summarize ([ bentoml . __doc__ ])[ 0 ]
print ( f"Result: { summarized_text } " ) Para implantar seu código do serviço BentoML, primeiro crie um arquivo bentofile.yaml para definir suas dependências e ambientes. Encontre a lista completa de opções de bentofile aqui.
service : ' service:Summarization ' # Entry service import path
include :
- ' *.py ' # Include all .py files in current directory
python :
packages : # Python dependencies to include
- torch
- transformers
docker :
python_version : " 3.11 "Em seguida, escolha uma das seguintes formas de implantação:
Execute bentoml build para empacotar o código, os modelos e as configurações de dependência necessários em um Bento - o artefato implantável padronizado no BentoML:
bentoml buildCertifique-se de que o Docker esteja em execução. Gere uma imagem de contêiner Docker para implantação:
bentoml containerize summarization:latestExecute a imagem gerada:
docker run --rm -p 3000:3000 summarization:latestBentoCloud fornece infraestrutura de computação para adoção rápida e confiável de GenAI. Ele ajuda a acelerar o processo de desenvolvimento do BentoML, aproveitando os recursos de computação em nuvem, e simplifica a forma como você implanta, dimensiona e opera o BentoML na produção.
Cadastre-se no BentoCloud para acesso pessoal; para casos de uso corporativo, entre em contato com nossa equipe.
# After signup, run the following command to create an API token:
bentoml cloud login
# Deploy from current directory:
bentoml deploy . 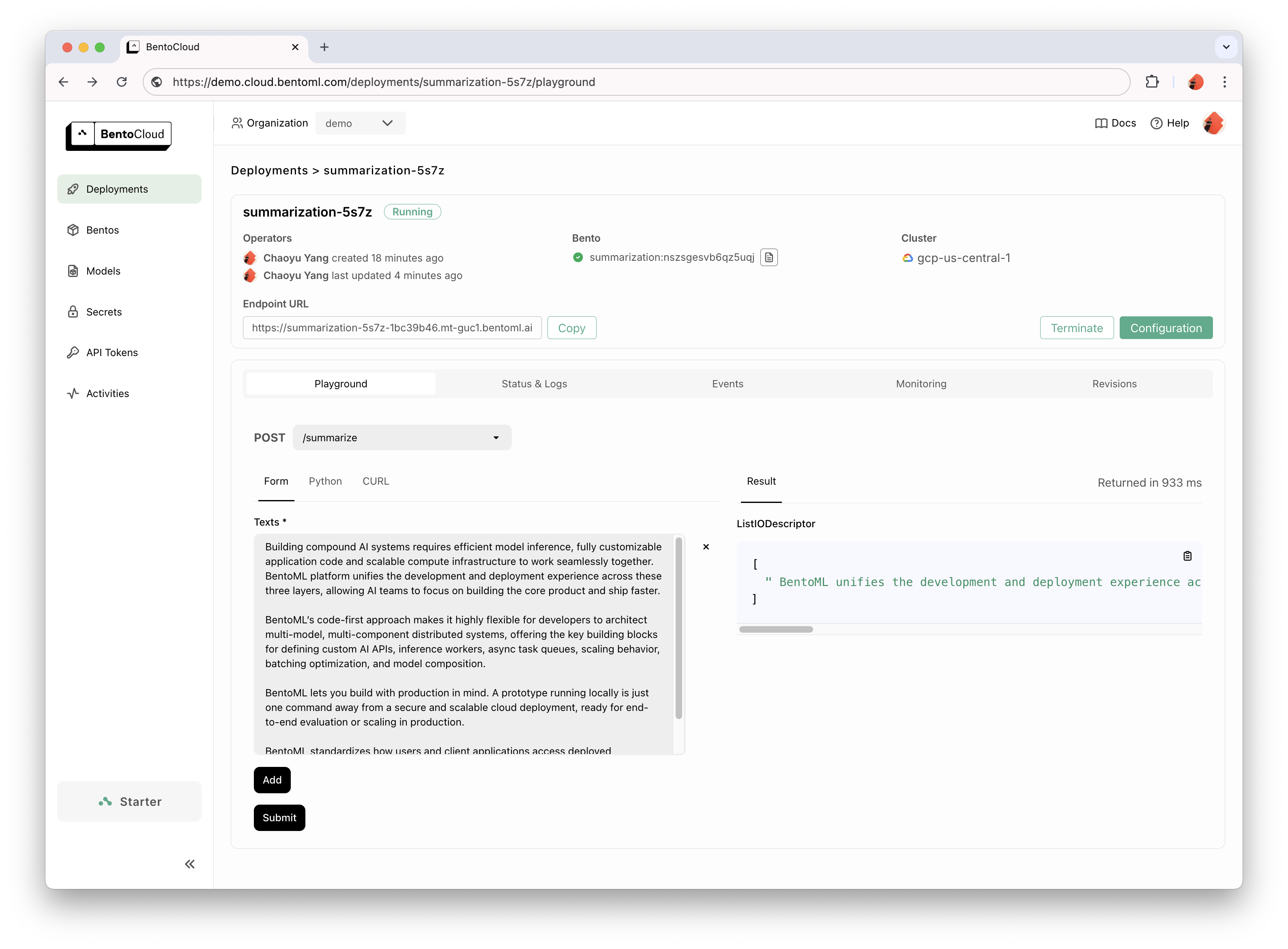
Para explicações detalhadas, leia o exemplo Hello World.
Confira a lista completa para mais exemplos de código e uso.
Consulte a documentação para obter mais tutoriais e guias.
Participe e junte-se ao nosso Community Slack, onde milhares de engenheiros de IA/ML ajudam uns aos outros, contribuem com o projeto e falam sobre a construção de produtos de IA.
Para relatar um bug ou sugerir uma solicitação de recurso, use GitHub Issues.
Existem muitas maneiras de contribuir com o projeto:
#bentoml-contributors aqui.Obrigado a todos os nossos incríveis colaboradores!
A estrutura BentoML coleta dados de uso anônimos que ajudam nossa comunidade a melhorar o produto. Apenas as chamadas internas da API do BentoML estão sendo reportadas. Isso exclui qualquer informação confidencial, como código de usuário, dados de modelo, nomes de modelo ou rastreamentos de pilha. Aqui está o código usado para rastreamento de uso. Você pode cancelar o rastreamento de uso pela opção CLI --do-not-track :
bentoml [command] --do-not-trackOu definindo a variável de ambiente:
export BENTOML_DO_NOT_TRACK=TrueLicença Apache 2.0