uniflow llm based pdf extraction text cleaning data clustering
0.0.31
uniflow fornece uma interface LLM unificada para extrair e transformar documentos brutos.
O Uniflow aborda dois desafios principais na preparação de dados de treinamento LLM para cientistas de ML:
Portanto, construímos o Uniflow, uma interface LLM unificada para extrair e transformar documentos brutos.
O Uniflow tem como objetivo ajudar cada cientista de dados a gerar seus próprios conjuntos de dados de treinamento com privacidade preservada e prontos para uso para ajuste fino de LLM e, portanto, tornar o ajuste fino de LLMs mais acessível a todos: foguete:.
Confira as soluções práticas da Uniflow:
A instalação uniflow leva cerca de 5 a 10 minutos se você seguir as 3 etapas abaixo:
Crie um ambiente conda em seu terminal usando:
conda create -n uniflow python=3.10 -y
conda activate uniflow # some OS requires `source activate uniflow`
Instale o pytorch compatível com base no seu sistema operacional.
nvcc -V . pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121 # cu121 means cuda 12.1
pip3 install torch
Instale uniflow :
pip3 install uniflow
(Opcional) Se estiver executando um dos seguintes fluxos OpenAI , você terá que configurar sua chave de API OpenAI. Para fazer isso, crie um arquivo .env na pasta raiz do uniflow. Em seguida, adicione a seguinte linha ao arquivo .env :
OPENAI_API_KEY=YOUR_API_KEY
(Opcional) Se você estiver executando o HuggingfaceModelFlow , também precisará instalar as bibliotecas transformers , accelerate , bitsandbytes , scipy :
pip3 install transformers accelerate bitsandbytes scipy
(Opcional) Se você estiver executando o LMQGModelFlow , também precisará instalar as bibliotecas lmqg e spacy :
pip3 install lmqg spacy
Parabéns, você concluiu a instalação!
Se você estiver interessado em contribuir conosco, aqui estão as configurações preliminares de desenvolvimento.
conda create -n uniflow python=3.10 -y
conda activate uniflow
cd uniflow
pip3 install poetry
poetry install --no-root
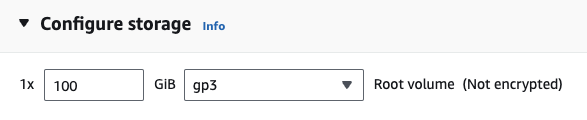
Se você estiver no EC2, poderá iniciar uma instância de GPU com a seguinte configuração:
g4dn.xlarge (se você deseja executar um LLM pré-treinado com parâmetros 7B)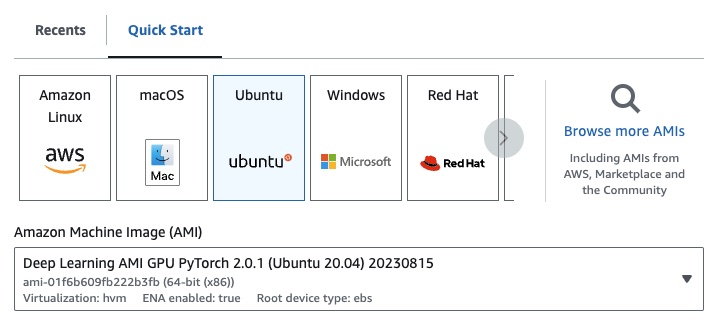
Se estiver executando um dos seguintes fluxos OpenAI , você terá que configurar sua chave de API OpenAI.
Para fazer isso, crie um arquivo .env na pasta raiz do uniflow. Em seguida, adicione a seguinte linha ao arquivo .env :
OPENAI_API_KEY=YOUR_API_KEY
Para usar uniflow , siga três etapas principais:
Escolha uma Config
Isto determina o LLM e os diferentes parâmetros configuráveis.
Construa seus Prompts
Construa o contexto que você deseja usar para solicitar seu modelo. Você pode configurar instruções e exemplos personalizados usando a classe PromptTemplate .
Execute seu Flow
Execute o fluxo nos seus dados de entrada e gere a saída do seu LLM.
Observação: no momento, também estamos criando fluxos
Preprocessingpara ajudar a processar dados de diferentes fontes, comohtml,Markdowne muito mais.
O Config determina qual LLM é usado e como os dados de entrada são serializados e desserializados. Também possui parâmetros específicos do LLM.
Aqui está uma tabela das diferentes configurações predefinidas que você pode usar e seus LLMs correspondentes:
| Configuração | LLM |
|---|---|
| Configuração | gpt-3.5-turbo-1106 |
| OpenAIConfig | gpt-3.5-turbo-1106 |
| HuggingfaceConfig | mistralai/Mistral-7B-Instruct-v0.1 |
| LMQGConfig | lmqg/t5-base-squad-qg-ae |
Você pode executar cada configuração com os padrões ou pode passar parâmetros personalizados, como temperature ou batch_size para a configuração do seu caso de uso. Consulte a seção de configuração personalizada avançada para obter mais detalhes.
Por padrão, uniflow é configurado para gerar perguntas e respostas com base no Context que você passa. Para fazer isso, ele possui uma instrução padrão e alguns exemplos rápidos que usa para orientar o LLM.
Aqui está a instrução padrão:
Generate one question and its corresponding answer based on the last context in the last example. Follow the format of the examples below to include context, question, and answer in the response
Aqui estão os exemplos padrão de algumas fotos:
context="The quick brown fox jumps over the lazy brown dog.",
question="What is the color of the fox?",
answer="brown."
context="The quick brown fox jumps over the lazy black dog.",
question="What is the color of the dog?",
answer="black."
Para executar essas instruções e exemplos padrão, tudo o que você precisa fazer é passar uma lista de objetos Context para o fluxo. uniflow irá então gerar um prompt personalizado com as instruções e exemplos rápidos para cada objeto Context a ser enviado ao LLM. Consulte a seção Executando o fluxo para obter mais detalhes.
A classe Context é usada para passar o contexto para o prompt LLM. Um Context consiste em uma propriedade context , que é uma sequência de texto.
Para executar uniflow com as instruções padrão e exemplos rápidos, você pode passar uma lista de objetos Context para o fluxo. Por exemplo:
from uniflow.op.prompt import Context
data = [
Context(
context="The quick brown fox jumps over the lazy brown dog.",
),
...
]
client.run(data)
Para obter uma visão geral mais detalhada da execução do fluxo, consulte a seção Executando o fluxo.
Se quiser executar com uma instrução de prompt personalizada ou exemplos de poucas etapas, você pode usar o objeto PromptTemplate . Possui instruction e propriedades example .
| Propriedade | Tipo | Descrição |
|---|---|---|
instruction | str | Instruções detalhadas para o LLM |
examples | Lista[Contexto] | Os exemplos de poucas fotos. |
Você pode substituir qualquer um dos padrões conforme necessário.
Para ver um exemplo de como usar o PromptTemplate para executar uniflow com uma instruction personalizada, exemplos rápidos e campos Context personalizados para gerar um resumo, verifique o bloco de notas openai_pdf_source_10k_summary
Depois de decidir sua estratégia Config e solicitação, você poderá executar o fluxo nos dados de entrada.
Importe os objetos uniflow Client , Config e Context .
from uniflow.flow.client import TransformClient
from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig
from uniflow.op.prompt import Context
Pré-processe seus dados em pedaços para passar para o fluxo. No futuro teremos fluxos Preprocessing para ajudar nesta etapa, mas por enquanto você pode usar uma biblioteca de sua escolha, como pypdf, para agrupar seus dados.
raw_input_context = ["It was a sunny day and the sky color is blue.", "My name is bobby and I am a talent software engineer working on AI/ML."]
Crie uma lista de objetos Context para passar seus dados para o fluxo.
data = [
Context(context=c)
for c in raw_input_context
]
[Opcional] Se você quiser usar instruções e/ou exemplos personalizados, crie um PromptTemplate .
from uniflow.op.prompt import PromptTemplate
guided_prompt = PromptTemplate(
instruction="Generate a one sentence summary based on the last context below. Follow the format of the examples below to include context and summary in the response",
few_shot_prompt=[
Context(
context="When you're operating on the maker's schedule, meetings are a disaster. A single meeting can blow a whole afternoon, by breaking it into two pieces each too small to do anything hard in. Plus you have to remember to go to the meeting. That's no problem for someone on the manager's schedule. There's always something coming on the next hour; the only question is what. But when someone on the maker's schedule has a meeting, they have to think about it.",
summary="Meetings disrupt the productivity of those following a maker's schedule, dividing their time into impractical segments, while those on a manager's schedule are accustomed to a continuous flow of tasks.",
),
],
)
Crie um objeto Config para passar para o objeto Client .
config = TransformOpenAIConfig(
prompt_template=guided_prompt,
model_config=OpenAIModelConfig(
response_format={"type": "json_object"}
),
)
client = TransformClient(config)
Use o objeto client para executar o fluxo nos dados de entrada.
output = client.run(data)
Processe os dados de saída. Por padrão, a saída do LLM será uma lista de dictos de saída, um para cada Context passado para o fluxo. Cada dict possui uma propriedade response que contém a resposta LLM, bem como quaisquer erros. Por exemplo output[0]['output'][0] ficaria assim:
{
'response': [{'context': 'It was a sunny day and the sky color is blue.',
'question': 'What was the color of the sky?',
'answer': 'blue.'}],
'error': 'No errors.'
}
Para obter mais exemplos, consulte a pasta de exemplo.
Você também pode configurar os fluxos passando configurações ou argumentos personalizados para o objeto Config se quiser ajustar ainda mais parâmetros específicos, como o modelo LLM, o número de threads, a temperatura e muito mais.
Cada configuração possui os seguintes parâmetros:
| Parâmetro | Tipo | Descrição |
|---|---|---|
prompt_template | PromptTemplate | O modelo a ser usado para o prompt guiado. |
num_threads | interno | O número de threads a serem usados para o fluxo. |
model_config | ModelConfig | A configuração a ser passada para o modelo. |
Você pode configurar ainda mais o model_config passando uma das Model Configs com parâmetros personalizados.
O Model Config é uma configuração que é passada para o objeto Config base e determina qual modelo LLM é usado e possui parâmetros específicos do modelo LLM.
A configuração base é chamada ModelConfig e possui os seguintes parâmetros:
| Parâmetro | Tipo | Padrão | Descrição |
|---|---|---|---|
model_name | str | gpt-3.5-turbo-1106 | Site OpenAI |
O OpenAIModelConfig herda do ModelConfig e possui os seguintes parâmetros adicionais:
| Parâmetro | Tipo | Padrão | Descrição |
|---|---|---|---|
num_calls | interno | 1 | O número de chamadas a serem feitas à API OpenAI. |
temperature | flutuador | 1,5 | A temperatura a ser usada para a API OpenAI. |
response_format | Ditado[str, str] | {"tipo": "texto"} | O formato de resposta a ser usado para a API OpenAI. Pode ser "texto" ou "json" |
O HuggingfaceModelConfig herda do ModelConfig , mas substitui o parâmetro model_name para usar o modelo mistralai/Mistral-7B-Instruct-v0.1 por padrão.
| Parâmetro | Tipo | Padrão | Descrição |
|---|---|---|---|
model_name | str | mistralai/Mistral-7B-Instruct-v0.1 | Site Abraçando o Rosto |
batch_size | interno | 1 | O tamanho do lote a ser usado para a API Hugging Face. |
O LMQGModelConfig herda do ModelConfig , mas substitui o parâmetro model_name para usar o modelo lmqg/t5-base-squad-qg-ae por padrão.
| Parâmetro | Tipo | Padrão | Descrição |
|---|---|---|---|
model_name | str | lmqg/t5-base-squad-qg-ae | Site Abraçando o Rosto |
batch_size | interno | 1 | O tamanho do lote a ser usado para a API LMQG. |
Aqui está um exemplo de como passar uma configuração personalizada para o objeto Client :
from uniflow.flow.client import TransformClient
from uniflow.flow.config import TransformOpenAIConfig, OpenAIModelConfig
from uniflow.op.prompt import Context
contexts = ["It was a sunny day and the sky color is blue.", "My name is bobby and I am a talent software engineer working on AI/ML."]
data = [
Context(
context=c
)
for c in contexts
]
config = OpenAIConfig(
num_threads=2,
model_config=OpenAIModelConfig(
model_name="gpt-4",
num_calls=2,
temperature=0.5,
),
)
client = TransformClient(config)
output = client.run(data)
Como você pode ver, estamos passando parâmetros customizados para o OpenAIModelConfig para as configurações OpenAIConfig de acordo com nossas necessidades.


