evidently
v0.4.40
Uma estrutura de código aberto para avaliar, testar e monitorar sistemas baseados em ML e LLM.

Documentação | Comunidade Discord | Blogue | Twitter | Evidentemente Nuvem
Evidentemente 0.4.25 . Avaliação LLM -> Tutorial
Evidentemente é uma biblioteca Python de código aberto para avaliação e observabilidade de ML e LLM. Ele ajuda a avaliar, testar e monitorar sistemas e pipelines de dados alimentados por IA, desde a experimentação até a produção.
Evidentemente é muito modular. Você pode começar com avaliações únicas usando Reports ou Test Suites em Python ou obter um serviço Dashboard de monitoramento em tempo real.
Os relatórios calculam vários dados, métricas de qualidade de ML e LLM. Você pode começar com predefinições ou personalizar.
| Relatórios |
|---|
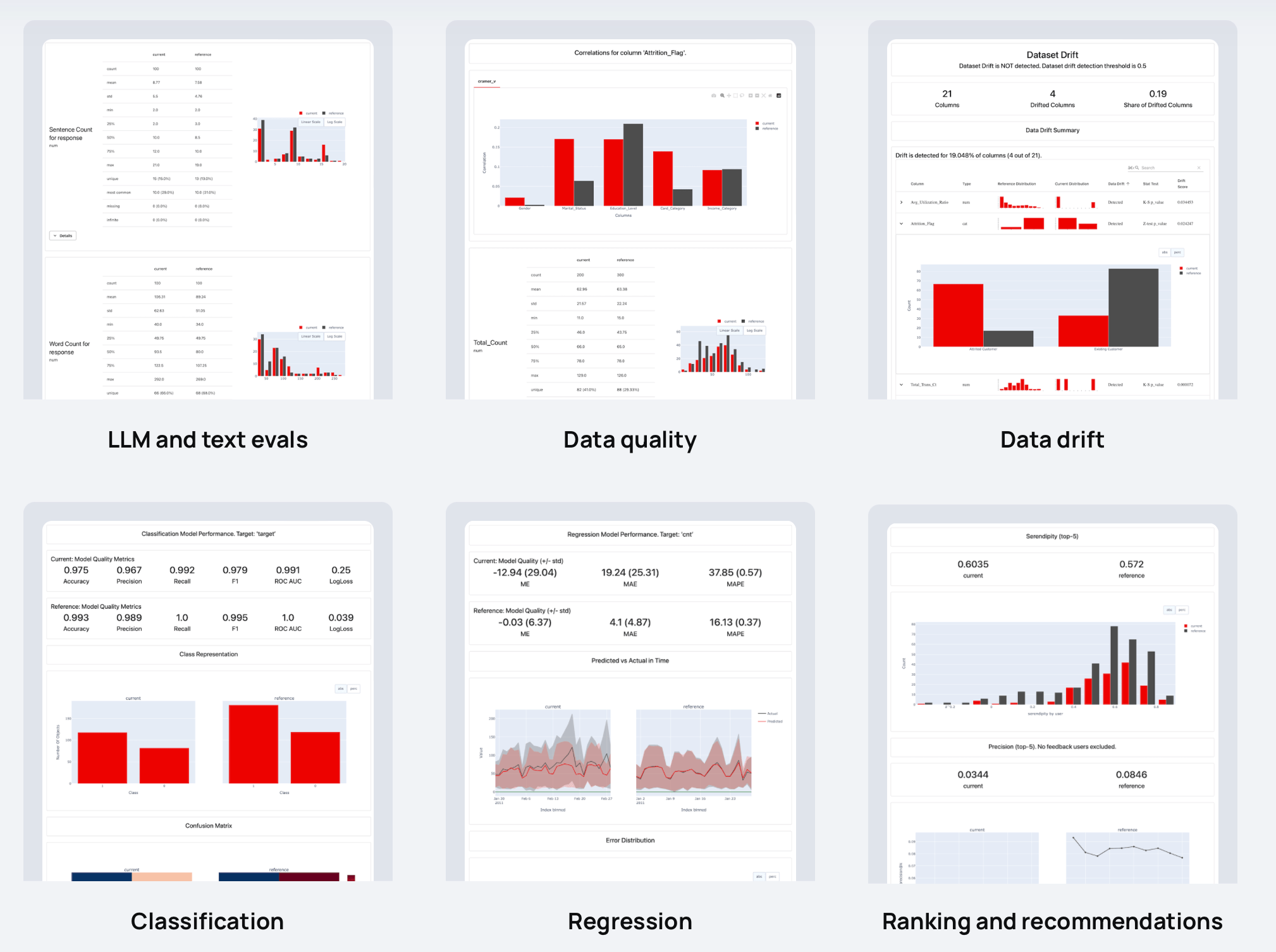 |
Os conjuntos de testes verificam as condições definidas nos valores de métrica e retornam um resultado de aprovação ou reprovação.
gt (maior que), lt (menor que), etc.| Conjunto de testes |
|---|
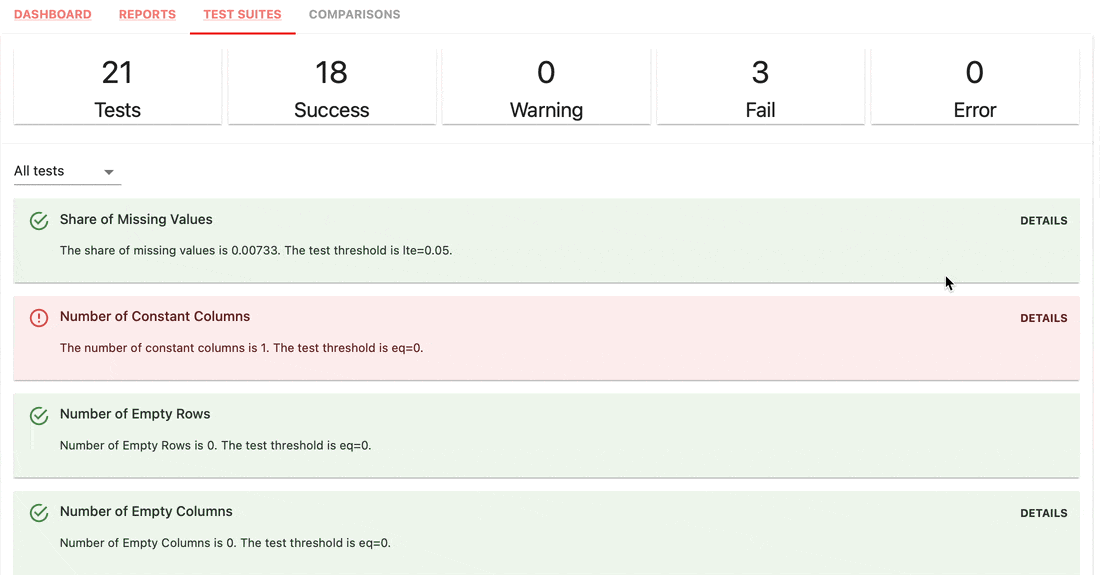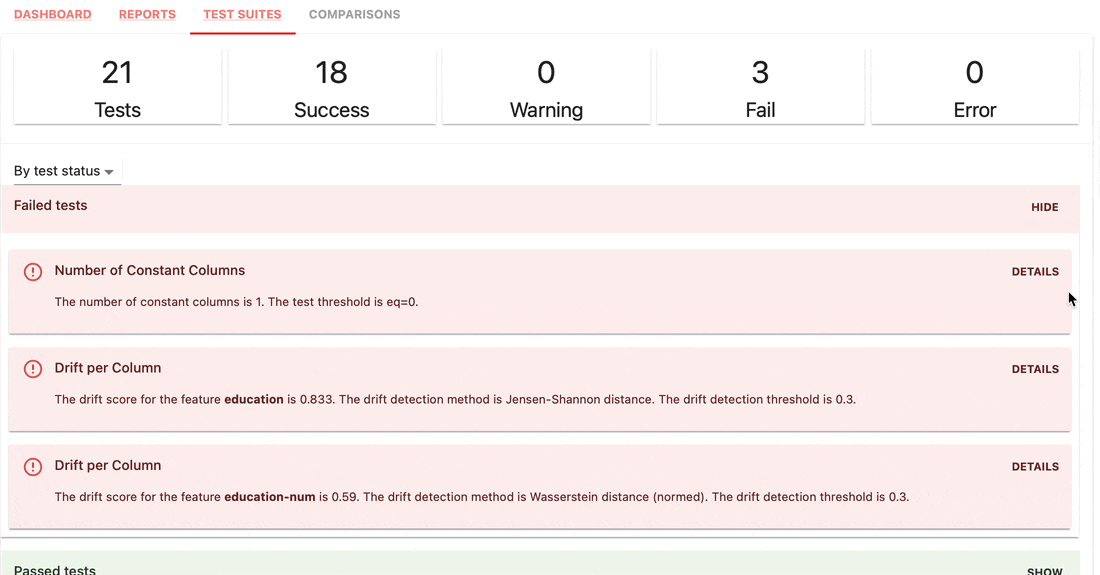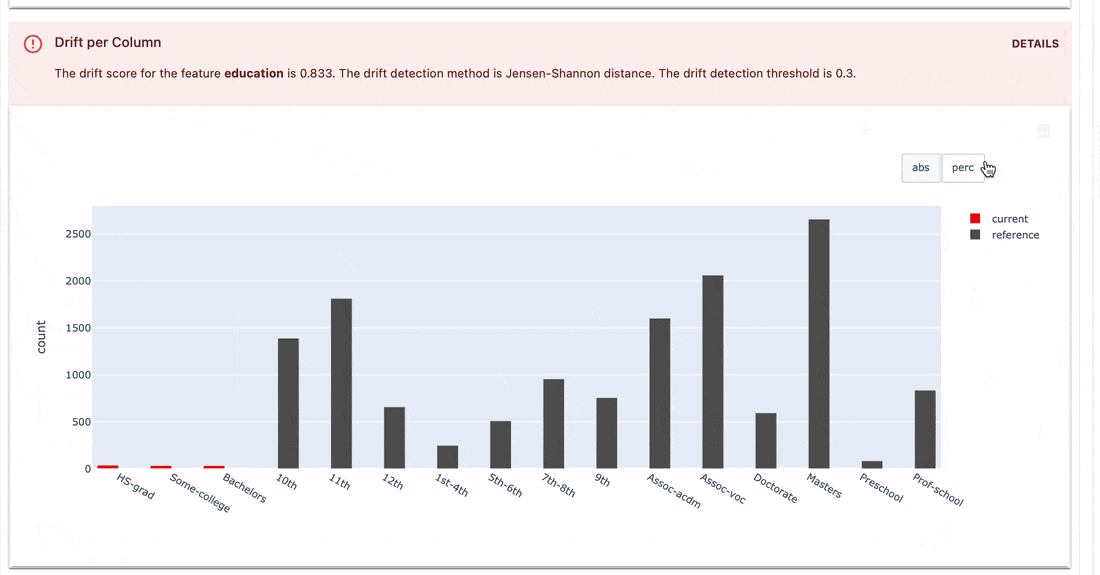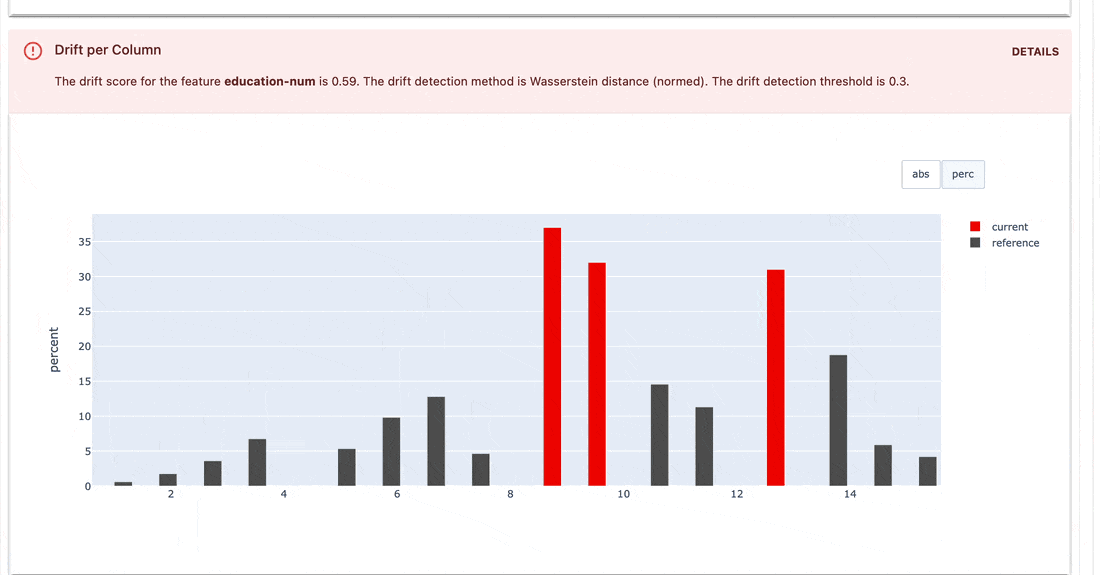 |
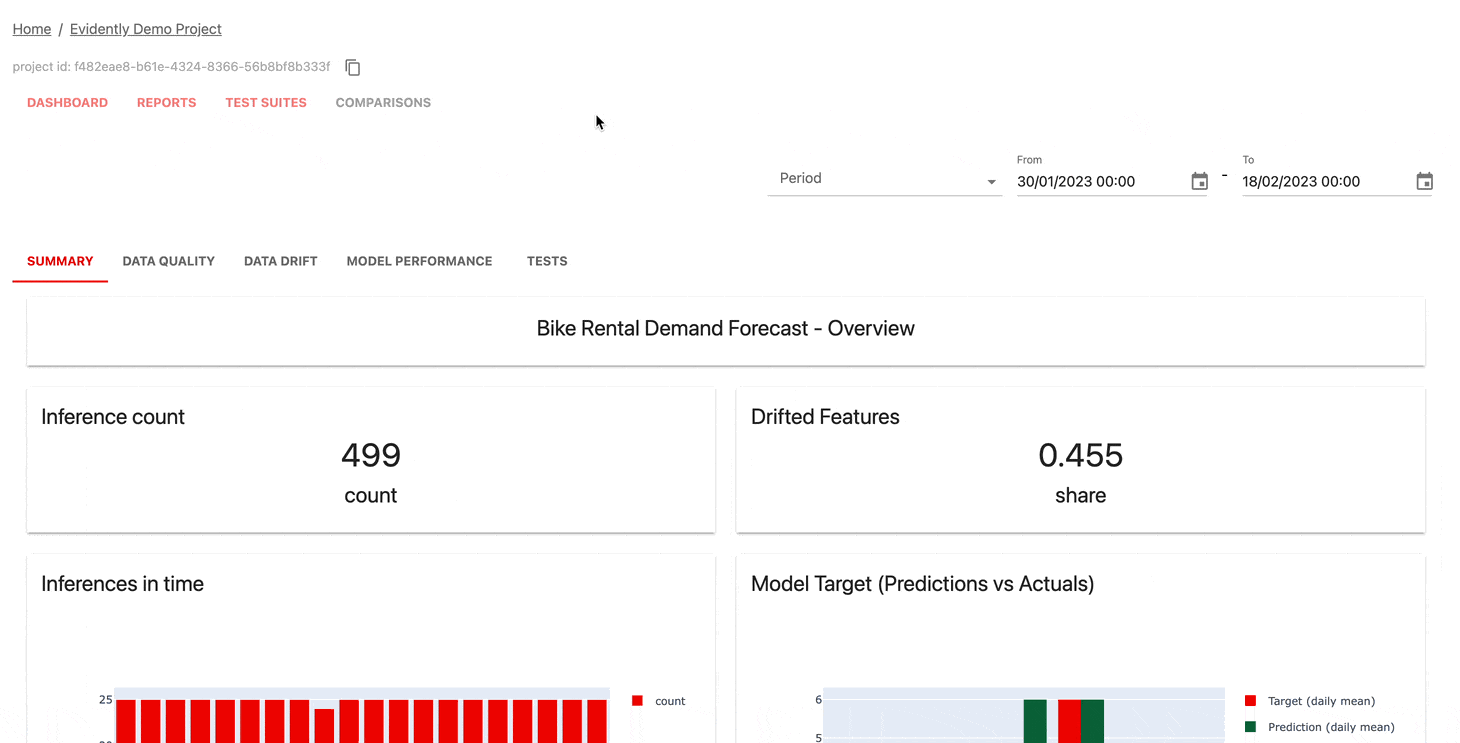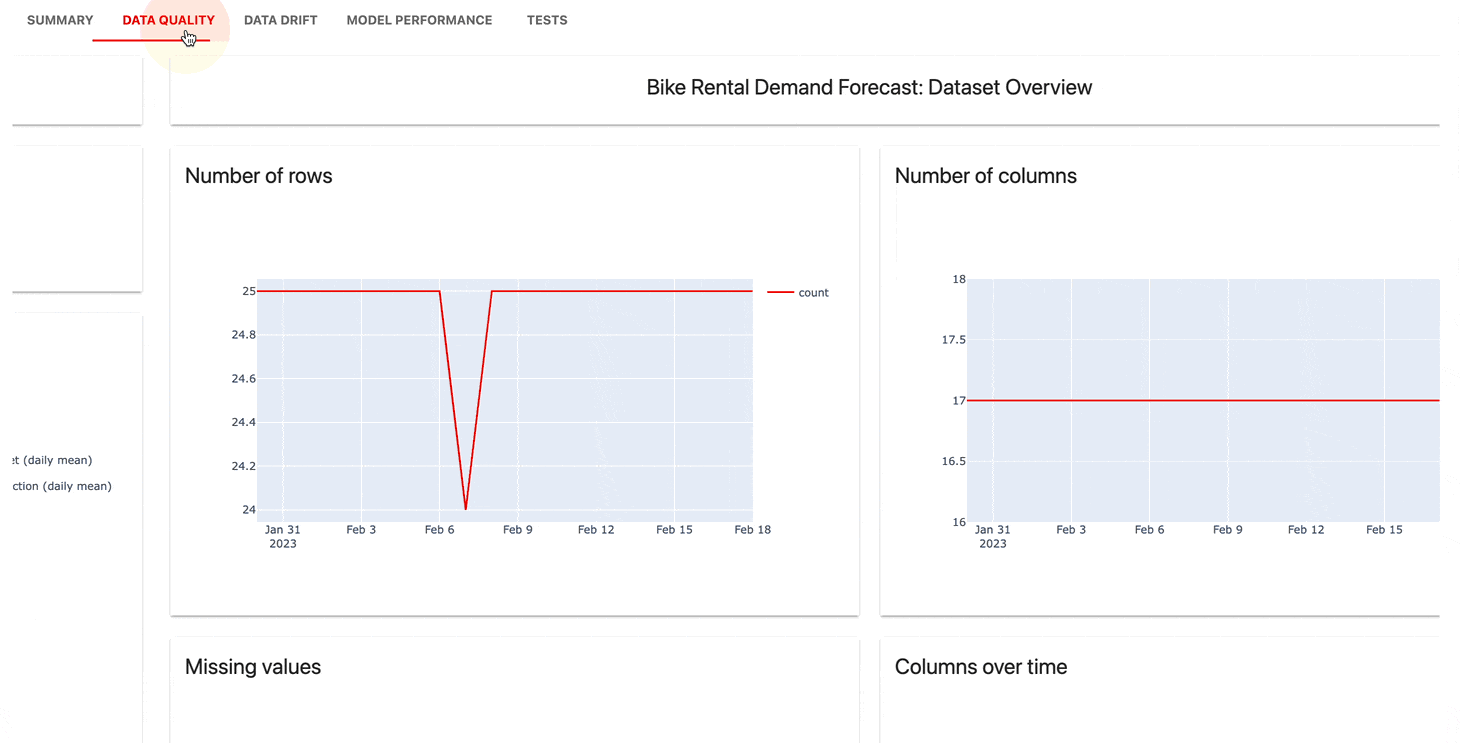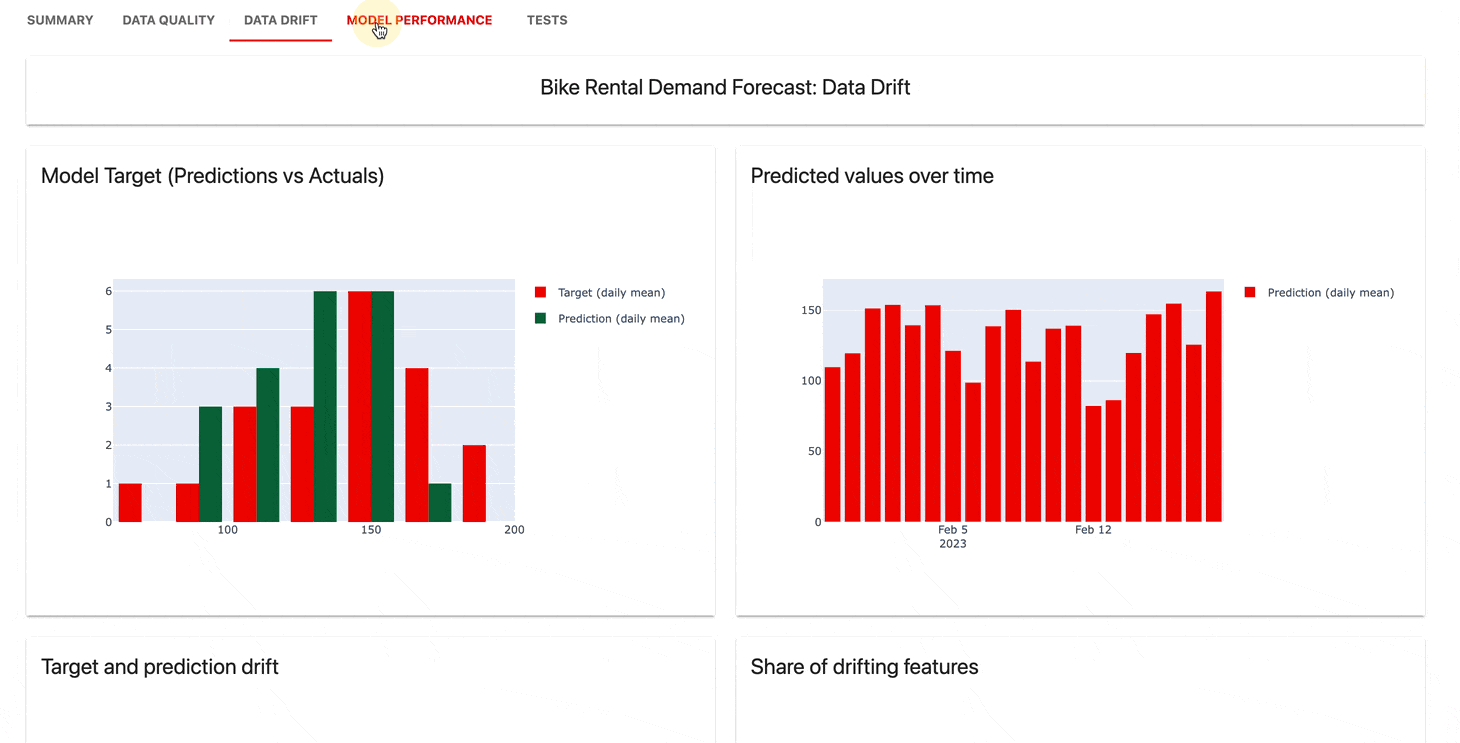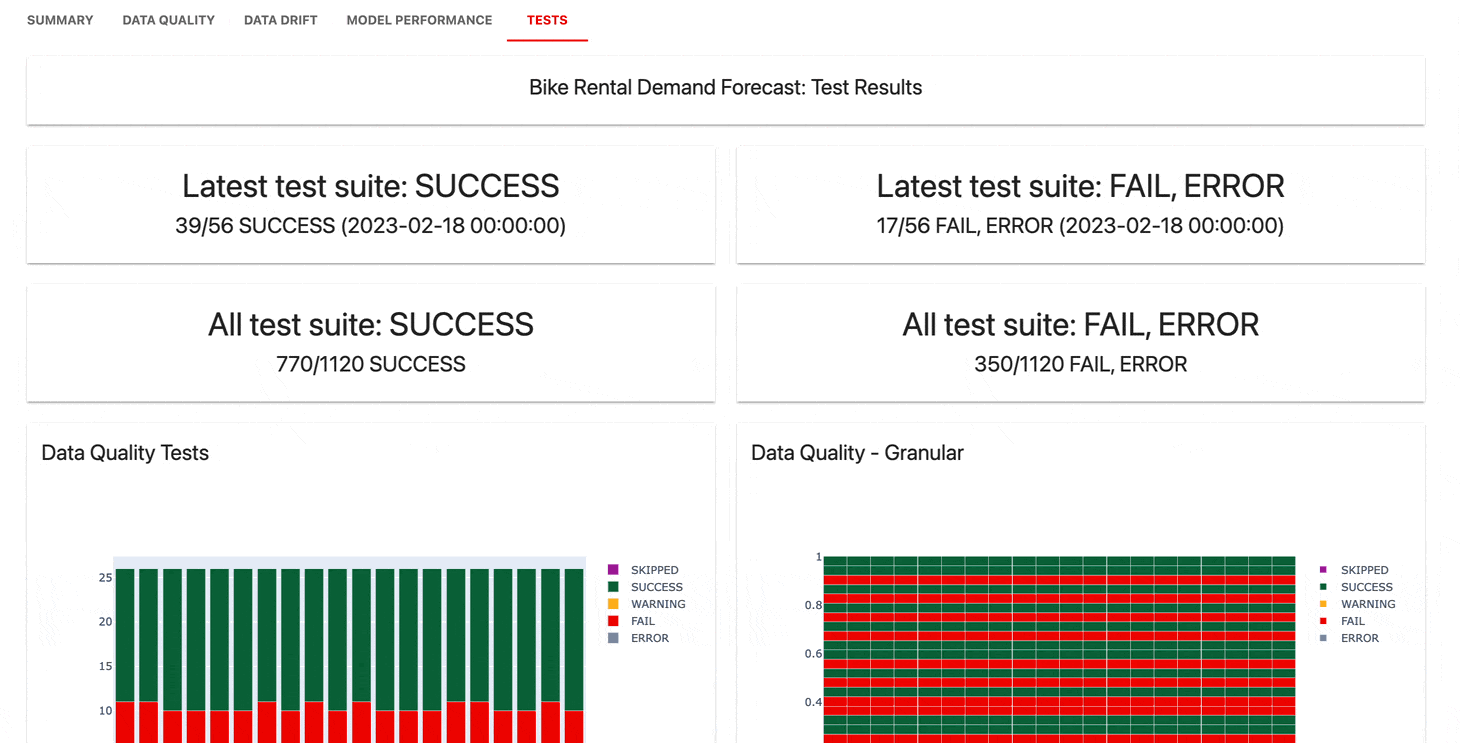
O serviço de UI de monitoramento ajuda a visualizar métricas e resultados de testes ao longo do tempo.
Você pode escolher:
Evidentemente, o Cloud oferece um nível gratuito generoso e recursos extras, como gerenciamento de usuários, alertas e avaliações sem código.
| Painel |
|---|
 |
Evidentemente está disponível como um pacote PyPI. Para instalá-lo usando o gerenciador de pacotes pip, execute:
pip install evidentlyPara instalar Evidentemente usando o instalador conda, execute:
conda install -c conda-forge evidentlyEste é um simples Olá Mundo. Confira os Tutoriais para mais: Dados tabulares ou avaliação LLM.
Importe o Test Suite , o Preset de avaliação e o conjunto de dados tabulares de brinquedo.
import pandas as pd
from sklearn import datasets
from evidently . test_suite import TestSuite
from evidently . test_preset import DataStabilityTestPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame Divida o DataFrame em referência e atual. Execute o conjunto de testes de estabilidade de dados que gerará automaticamente verificações em intervalos de valores de colunas, valores ausentes, etc. a partir da referência. Obtenha a saída no notebook Jupyter:
data_stability = TestSuite ( tests = [
DataStabilityTestPreset (),
])
data_stability . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_stabilityVocê também pode salvar um arquivo HTML. Você precisará abri-lo na pasta de destino.
data_stability . save_html ( "file.html" )Para obter a saída como JSON:
data_stability . json ()Você pode escolher outros Presets, testes individuais e condições definidas.
Importe o relatório , a predefinição de avaliação e o conjunto de dados tabulares do brinquedo.
import pandas as pd
from sklearn import datasets
from evidently . report import Report
from evidently . metric_preset import DataDriftPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame Execute o relatório de desvio de dados que comparará as distribuições de colunas entre current e reference :
data_drift_report = Report ( metrics = [
DataDriftPreset (),
])
data_drift_report . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_drift_reportSalve o relatório como HTML. Posteriormente, você precisará abri-lo na pasta de destino.
data_drift_report . save_html ( "file.html" )Para obter a saída como JSON:
data_drift_report . json ()Você pode escolher outras predefinições e métricas individuais, incluindo avaliações LLM para dados de texto.
Isso inicia um projeto de demonstração na IU do Evidently. Verifique os tutoriais para auto-hospedagem ou Evidentemente Cloud.
Etapa recomendada: crie um ambiente virtual e ative-o.
pip install virtualenv
virtualenv venv
source venv/bin/activate
Depois de instalar o Evidently ( pip install evidently ), execute a IU do Evidently com os projetos de demonstração:
evidently ui --demo-projects all
Acesse o serviço Evidely UI em seu navegador. Vá para localhost:8000 .
Evidentemente tem mais de 100 avaliações integradas. Você também pode adicionar outros personalizados. Cada métrica possui uma visualização opcional: você pode usá-la em Reports , Test Suites ou plotar em um Dashboard .
Aqui estão alguns exemplos de coisas que você pode verificar:
| ? Descritores de texto | Resultados do LLM |
| Comprimento, sentimento, toxicidade, idioma, símbolos especiais, correspondências de expressões regulares, etc. | Similaridade semântica, relevância de recuperação, qualidade de resumo, etc. com avaliações baseadas em modelo e LLM. |
| ? Qualidade dos dados | Desvio de distribuição de dados |
| Valores ausentes, duplicatas, intervalos mínimo-máximo, novos valores categóricos, correlações, etc. | Mais de 20 testes estatísticos e métricas de distância para comparar mudanças na distribuição de dados. |
| Classificação | ? Regressão |
| Exatidão, precisão, recall, ROC AUC, matriz de confusão, viés, etc. | MAE, ME, RMSE, distribuição de erros, normalidade de erros, viés de erro, etc. |
| ? Classificação (incluindo RAG) | ? Recomendações |
| NDCG, MAP, MRR, taxa de acerto, etc. | Serendipidade, novidade, diversidade, preconceito de popularidade, etc. |
Aceitamos contribuições! Leia o Guia para saber mais.
Para mais informações, consulte a documentação completa. Você pode começar com os tutoriais:
Veja mais exemplos nos Documentos.
Explore os guias de instruções para entender os recursos específicos do Evidely.
Se você quiser conversar e se conectar, junte-se à nossa comunidade Discord!


