airllm
1.0.0

Início rápido | Configurações | Mac OS | Cadernos de exemplo | Perguntas frequentes
AirLLM otimiza o uso de memória de inferência, permitindo que modelos de linguagem grande de 70B executem inferência em uma única placa GPU de 4GB sem quantização, destilação e poda. E você pode executar 405B Llama3.1 em 8GB vram agora.
[2024/08/20] v2.11.0: Suporte Qwen2.5
[2024/08/18] v2.10.1 Suporta inferência de CPU. Suporta modelos não fragmentados. Obrigado @NavodPeiris pelo excelente trabalho!
[2024/07/30] Suporte Llama3.1 405B (exemplo de notebook). Suporta quantização de 8 bits/4 bits .
[2024/04/20] AirLLM já suporta Llama3 nativamente. Execute Llama3 70B em GPU única de 4 GB.
[2023/12/25] v2.8.2: Suporta MacOS executando modelos de linguagem grande de 70B.
[2023/12/20] v2.7: Suporte AirLLMMixtral.
[2023/12/20] v2.6: Adicionado AutoModel, detecta automaticamente o tipo de modelo, não há necessidade de fornecer classe de modelo para inicializar o modelo.
[2023/12/18] v2.5: adição de pré-busca para sobrepor o carregamento e a computação do modelo. Melhoria de velocidade de 10%.
[2023/12/03] adicionado suporte para ChatGLM , QWen , Baichuan , Mistral , InternLM !
[2023/12/02] adicionou suporte para safetensors. Agora suporte todos os 10 principais modelos na tabela de classificação aberta do LLM.
[2023/12/01] airllm 2.0. Compressões de suporte: tempo de execução 3x mais rápido!
[2023/11/20] airllm Versão inicial!
Primeiro, instale o pacote airllm pip.
pip install airllmEm seguida, inicialize AirLLMLlama2, passe o ID do repositório huggingface do modelo que está sendo usado ou o caminho local, e a inferência pode ser realizada de forma semelhante a um modelo de transformador normal.
( Você também pode especificar o caminho para salvar o modelo em camadas divididas por meio de layer_shards_ Saving_path ao iniciar AirLLMLlama2.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )Nota: Durante a inferência, o modelo original será primeiro decomposto e salvo em camadas. Certifique-se de que haja espaço em disco suficiente no diretório de cache huggingface.
Acabamos de adicionar compactação de modelo com base na compactação de modelo baseada em quantização em bloco. O que pode acelerar ainda mais a velocidade de inferência em até 3x , com perda de precisão quase ignorável! (veja mais avaliações de desempenho e por que usamos a quantização em blocos neste artigo)
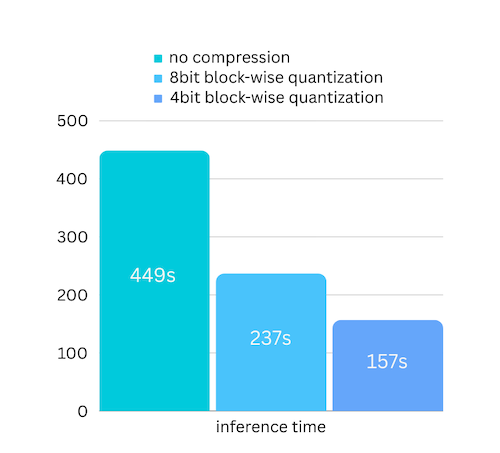
pip install -U bitsandbytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)A quantização normalmente precisa quantizar pesos e ativações para realmente acelerar as coisas. O que torna mais difícil manter a precisão e evitar o impacto de valores discrepantes em todos os tipos de entradas.
Embora no nosso caso o gargalo esteja principalmente no carregamento do disco, precisamos apenas diminuir o tamanho do carregamento do modelo. Assim, conseguimos quantizar apenas a parte dos pesos, o que é mais fácil de garantir a precisão.
Ao inicializar o modelo, oferecemos suporte às seguintes configurações:
Basta instalar o airllm e executar o código da mesma forma que no Linux. Veja mais em Início Rápido.
Exemplo [caderno python] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
Exemplo de colabs aqui:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])Muito do código é baseado no excelente trabalho do SimJeg na competição de exames Kaggle. Uma grande mensagem para SimJeg:
Conta GitHub @SimJeg, o código no Kaggle, a discussão associada.
safetensors_rust.SafetensorError: Erro ao desserializar o cabeçalho: MetadataIncompleteBuffer
Se você encontrar esse erro, a causa mais possível é que você ficou sem espaço em disco. O processo de divisão do modelo consome muito disco. Veja isto. Pode ser necessário estender o espaço em disco, limpar o huggingface .cache e executar novamente.
Provavelmente você está carregando o modelo QWen ou ChatGLM com a classe Llama2. Experimente o seguinte:
Para o modelo QWen:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Para o modelo ChatGLM:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)Alguns modelos são modelos fechados, precisam de token de API huggingface. Você pode fornecer hf_token:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')O tokenizer de alguns modelos não possui token de preenchimento, então você pode definir um token de preenchimento ou simplesmente desativar a configuração de preenchimento:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)Se você achar o AirLLM útil em sua pesquisa e desejar citá-lo, use a seguinte entrada BibTex:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
Contribuições, ideias e discussões bem-vindas!
Se você achar útil, por favor ou me compre um café!


