WilmerAI
1.0.0
Este é um projeto pessoal que está em forte desenvolvimento. Pode conter, e provavelmente contém, bugs, código incompleto ou outros problemas não intencionais. Como tal, o software é fornecido no estado em que se encontra, sem qualquer tipo de garantia.
WilmerAI reflete o trabalho de um único desenvolvedor e os esforços de seu tempo e recursos pessoais; quaisquer pontos de vista, metodologias, etc. encontrados nele são de sua autoria e não devem refletir sobre seu empregador.
WilmerAI é um sistema de middleware sofisticado projetado para receber prompts e executar várias tarefas neles antes de enviá-los para APIs LLM. Este trabalho inclui a utilização de um Large Language Model (LLM) para categorizar o prompt e encaminhá-lo para o fluxo de trabalho apropriado ou processar um contexto grande (mais de 200.000 tokens) para gerar um prompt menor e mais gerenciável, adequado para a maioria dos modelos locais.
WilmerAI significa "E se os modelos de linguagem roteassem habilmente todas as inferências?"
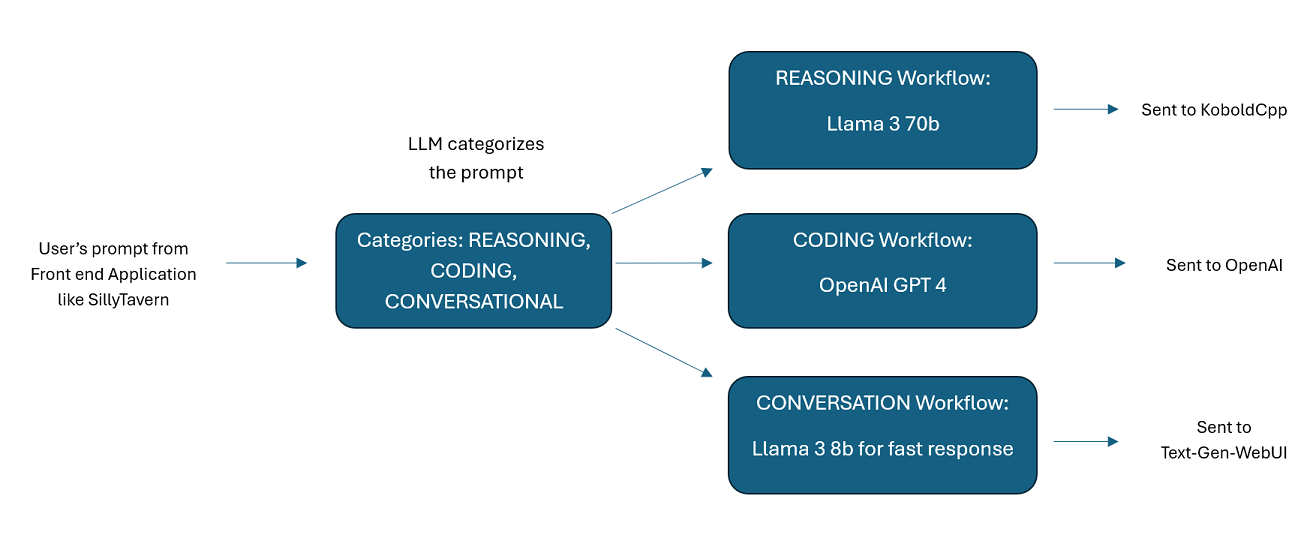
Assistentes alimentados por vários LLMs em conjunto : os prompts recebidos podem ser roteados para "categorias", com cada categoria alimentada por um fluxo de trabalho. Cada fluxo de trabalho pode ter quantos nós você desejar, cada nó alimentado por um LLM diferente. Por exemplo, se você perguntar ao seu assistente "Você pode me escrever um jogo Snake em python?", isso pode ser categorizado como CODING e vai para o seu fluxo de trabalho de codificação. O primeiro nó desse fluxo de trabalho pode pedir ao Codestral-22b (ou ChatGPT 4o, se desejar) para responder à pergunta. O segundo nó pode solicitar que Deepseek V2 ou Claude Sonnet revisem o código. O próximo nó pode pedir ao Codestral para dar uma última olhada e então responder a você. Quer o seu fluxo de trabalho seja apenas um único modelo respondendo porque é o seu melhor codificador, ou se são muitos nós de diferentes LLMs trabalhando juntos para gerar uma resposta - a escolha é sua.
Suporte para a API Offline Wikipedia : WilmerAI possui um nó que pode fazer chamadas para OfflineWikipediaTextApi. Isso significa que você pode ter uma categoria, por exemplo "FACTUAL", que analisa sua mensagem recebida, gera uma consulta a partir dela, consulta a API da Wikipédia em busca de um artigo relacionado e usa esse artigo como injeção de contexto RAG para responder.
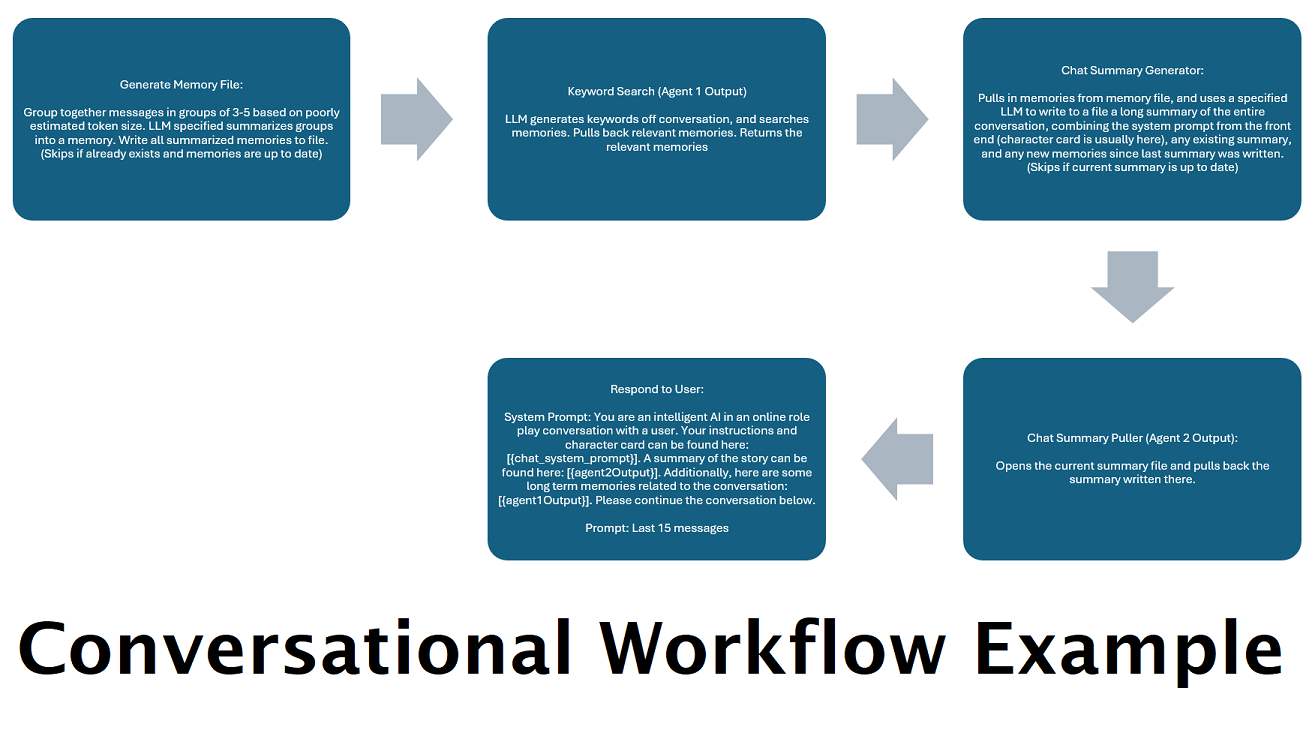
Resumos de bate-papo gerados continuamente para simular uma "memória" : O nó Resumo de bate-papo gerará "memórias", agrupando suas mensagens e, em seguida, resumindo-as e salvando-as em um arquivo. Em seguida, ele pegará esses pedaços resumidos e gerará um resumo contínuo e em constante atualização de toda a conversa, que pode ser obtido e usado no prompt do LLM. Os resultados permitem que você tenha mais de 200 mil conversas de contexto e mantenha um controle relativo do que foi dito, mesmo ao limitar os prompts do LLM a 5 mil contextos ou menos.
Use vários computadores para processar memórias e respostas em paralelo : se você tiver 2 computadores que podem executar LLMs, você pode designar um para ser o "respondente" e outro para ser responsável por gerar memórias/resumos. Esse tipo de fluxo de trabalho permite que você continue conversando com seu LLM enquanto as memórias/resumo estão sendo atualizados, enquanto ainda usa as memórias existentes. Isso significa não precisar esperar a atualização do resumo, mesmo se você atribuir um modelo grande e poderoso para lidar com essa tarefa, para que você tenha memórias de maior qualidade. (Veja o exemplo do usuário convo-role-dual-model )
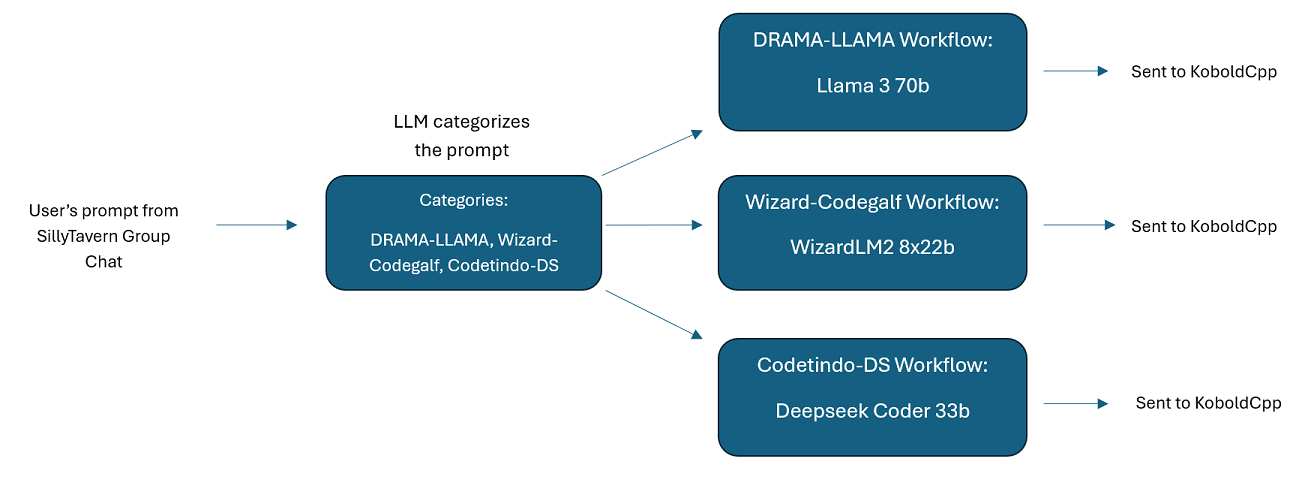
Bate-papos em grupo com vários LLM no SillyTavern: É possível usar o Wilmer para ter um bate-papo em grupo no ST, onde cada personagem é um LLM diferente, se desejar (o autor faz isso pessoalmente). Existem exemplos de caracteres disponíveis em DocsSillyTavern , divididos em dois grupos. Esses caracteres/grupos de exemplo são subconjuntos de grupos maiores que o autor usa.
Funcionalidade de middleware: WilmerAI fica entre a interface que você usa para se comunicar com um LLM (como SillyTavern, OpenWebUI ou mesmo um terminal de programa Python) e a API de back-end que atende os LLMs. Ele pode lidar com vários LLMs de back-end simultaneamente.
Usando vários LLMs ao mesmo tempo: Exemplo de configuração: SillyTavern -> WilmerAI -> várias instâncias de KoboldCpp. Por exemplo, Wilmer poderia ser conectado ao Command-R 35b, Codestral 22b, Gemma-2-27b e usar todos eles em suas respostas ao usuário. Contanto que o LLM de sua escolha seja exposto por meio de um endpoint v1/Completion ou chat/Completion, ou do endpoint Generate do KoboldCpp, você pode usá-lo.
Predefinições personalizáveis : as predefinições são salvas em um arquivo json que você pode personalizar facilmente. Quase todas as predefinições podem ser gerenciadas por meio do json, incluindo os nomes dos parâmetros. Isso significa que você não precisa esperar por uma atualização do Wilmer para usar algo novo. Por exemplo, DRY foi lançado recentemente no KoboldCpp. Se isso não estivesse no json predefinido para Wilmer, você poderia simplesmente adicioná-lo e começar a usá-lo.
Pontos finais de API: fornece pontos de extremidade chat/Completions e v1/Completions compatíveis com API OpenAI para conexão por meio de seu front-end e pode se conectar a qualquer tipo no back-end. Isso permite configurações complexas, como conectar-se ao Wilmer como uma API v1/Completion e, em seguida, conectar o Wilmer ao chat/Completion, v1/Completion KoboldCpp Gerar endpoints, tudo ao mesmo tempo.
Modelos de prompt: oferece suporte a modelos de prompt para endpoints da API v1/Completions . WilmerAI também tem seu próprio modelo de prompt para conexões de um front-end via v1/Completions . O modelo pode ser encontrado na pasta "Docs" e está pronto para upload no SillyTavern.

Lembre-se de que os fluxos de trabalho, por sua própria natureza, podem fazer muitas chamadas para um endpoint de API com base em como você os configurou. WilmerAI não rastreia o uso de tokens, não relata o uso preciso de tokens por meio de sua API, nem oferece qualquer maneira viável de monitorar o uso de tokens. Portanto, se o rastreamento do uso de tokens for importante para você por motivos de custo, certifique-se de acompanhar quantos tokens você está usando por meio de qualquer painel fornecido por suas APIs LLM, especialmente no início, à medida que você se acostumar com este software.
Seu LLM afeta diretamente a qualidade do WilmerAI. Este é um projecto orientado para o LLM, onde os fluxos e resultados dependem quase inteiramente dos LLMs conectados e das suas respostas. Se você conectar Wilmer a um modelo que produz resultados de qualidade inferior, ou se suas predefinições ou modelo de prompt apresentarem falhas, a qualidade geral de Wilmer também será de qualidade muito inferior. Nesse sentido, não é muito diferente dos fluxos de trabalho de agentes.
Embora o autor esteja fazendo o possível para criar algo útil e de alta qualidade, este é um projeto solo ambicioso e certamente terá seus problemas (especialmente porque o autor não é nativamente um desenvolvedor Python e dependeu muito da IA para ajudá-lo a conseguir isso). distante). Ele está lentamente descobrindo isso, no entanto.
Wilmer expõe um endpoint OpenAI v1/Completions e chat/Completions, tornando-o compatível com a maioria dos front-ends. Embora eu tenha usado isso principalmente com SillyTavern, também pode funcionar com Open-WebUI.
Para conectar como uma conclusão de texto no SillyTavern, siga estas etapas (a captura de tela abaixo é do SillyTavern):
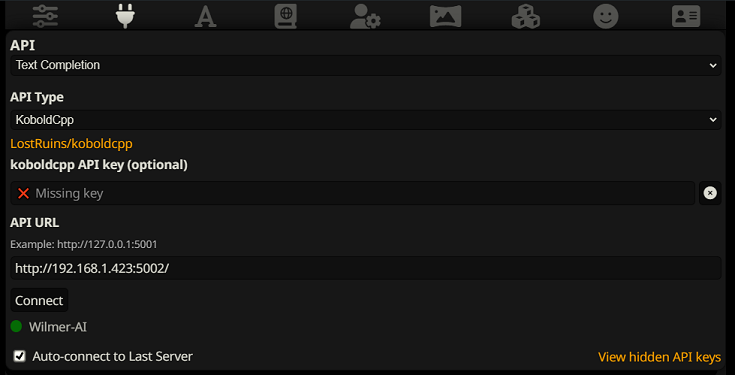
Ao usar conclusões de texto, você precisa usar um formato de modelo de prompt específico do WilmerAI. Um arquivo ST importável pode ser encontrado em Docs/SillyTavern/InstructTemplate . O modelo de contexto também está incluído se você quiser usá-lo também.
O modelo de instrução é assim:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
Da SillyTavern:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
Não há novas linhas ou caracteres esperados entre tags.
Certifique-se de que o modelo de contexto esteja "ativado" (caixa de seleção acima do menu suspenso)
Para conectar-se como conclusões de bate-papo no SillyTavern, siga estas etapas (a captura de tela abaixo é do SillyTavern):
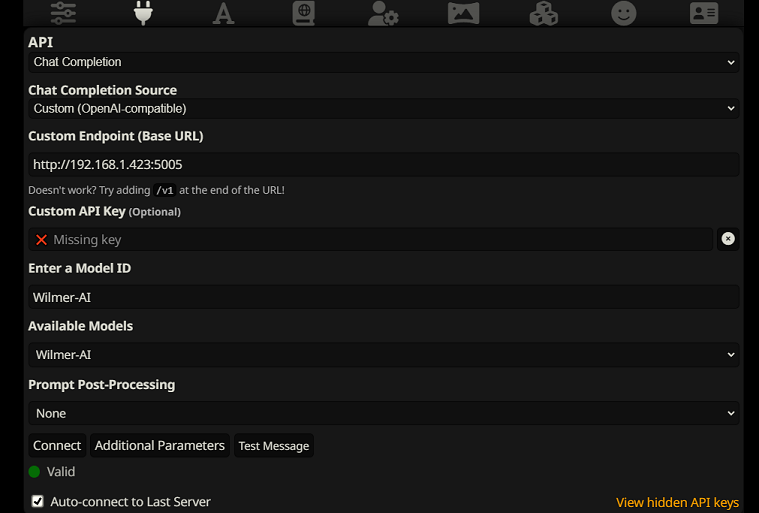
chatCompleteAddUserAssistant como verdadeiro. (Eu não recomendo definir ambos como verdadeiros ao mesmo tempo. Faça nomes de personagens de SillyTavern OU usuário/assistente de Wilmer. Caso contrário, a IA pode ficar confusa.)Para qualquer tipo de conexão, recomendo ir até o ícone "A" no SillyTavern e selecionar "Incluir Nomes" e "Forçar Grupos e Personas" no modo de instrução e, em seguida, ir até o ícone mais à esquerda (onde estão os amostradores) e marcar " stream" no canto superior esquerdo e, em seguida, no canto superior direito, marcando "desbloquear" no contexto e arrastando-o para mais de 200.000. Deixe Wilmer se preocupar com o contexto.
Wilmer atualmente não possui interface de usuário; tudo é controlado através de arquivos de configuração JSON localizados na pasta “Público”. Esta pasta contém todas as configurações essenciais. Ao atualizar ou baixar uma nova cópia do WilmerAI, você deve simplesmente copiar sua pasta “Pública” para a nova instalação para manter suas configurações.
Esta seção orientará você na configuração do Wilmer. Dividi as seções em etapas; Eu recomendo copiar cada etapa, 1 por 1, em um LLM e pedir ajuda para configurar a seção. Isso pode tornar tudo muito mais fácil.
NOTAS IMPORTANTES
É importante observar três coisas sobre a configuração do Wilmer.
A) Os arquivos predefinidos são 100% personalizáveis. O que está nesse arquivo vai para a API llm. Isso ocorre porque as APIs de nuvem não lidam com algumas das várias predefinições que as APIs LLM locais manipulam. Dessa forma, se você usar a API OpenAI ou outros serviços em nuvem, as chamadas provavelmente falharão se você usar uma das predefinições regulares de IA local. Consulte a predefinição "OpenAI-API" para obter um exemplo do que o openAI aceita.
B) Substituí recentemente todos os prompts do Wilmer para passar do uso da segunda para a terceira pessoa. Isso teve resultados bastante decentes para mim e espero que tenha para você também.
C) Por padrão, todos os arquivos do usuário estão configurados para ativar respostas de streaming. Você precisa habilitar isso em seu front-end que está chamando Wilmer para que ambos correspondam, ou você precisa entrar em Users/username.json e definir Stream como "false". Se você tiver uma incompatibilidade, onde o front-end espera/não espera streaming e seu wilmer espera o oposto, provavelmente nada será exibido no front-end.
Instalar o Wilmer é simples. Certifique-se de ter o Python instalado; o autor tem usado o programa com Python 3.10 e 3.12 e ambos funcionam bem.
Opção 1: usando scripts fornecidos
Por conveniência, Wilmer inclui um arquivo BAT para Windows e um arquivo .sh para macOS. Esses scripts criarão um ambiente virtual, instalarão os pacotes necessários de requirements.txt e, em seguida, executarão o Wilmer. Você pode usar esses scripts para iniciar o Wilmer todas as vezes.
.bat fornecido..sh fornecido.IMPORTANTE: Nunca execute um arquivo BAT ou SH sem inspecioná-lo primeiro, pois isso pode ser arriscado. Se você não tiver certeza sobre a segurança de tal arquivo, abra-o no Bloco de Notas/TextEdit, copie o conteúdo e peça ao seu LLM para revisá-lo em busca de possíveis problemas.
Opção 2: instalação manual
Alternativamente, você pode instalar manualmente as dependências e executar o Wilmer com as seguintes etapas:
Instale os pacotes necessários:
pip install -r requirements.txtInicie o programa:
python server.pyOs scripts fornecidos são projetados para agilizar o processo configurando um ambiente virtual. No entanto, você pode ignorá-los com segurança se preferir a instalação manual.
NOTA : Ao executar o arquivo bat, o arquivo sh ou o arquivo python, todos os três agora aceitam os seguintes argumentos OPCIONAIS:
Então, por exemplo, considere as seguintes execuções possíveis:
bash run_macos.sh (usará o usuário especificado em _current-user.json, configurações em "Público", logs em "logs")bash run_macos.sh --User "single-model-assistant" (o padrão será público para configurações e "log" para logs)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (usará apenas o padrão para "logs"bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"Esses argumentos opcionais permitem que os usuários criem várias instâncias do WilmerAI, cada instância usando um perfil de usuário diferente, registrando-se em um local diferente e especificando configurações em um local diferente, se desejado.
Dentro de Public/Configs você encontrará uma série de pastas contendo arquivos json. As duas que mais lhe interessam são a pasta Endpoints e a pasta Users .
NOTA: Os nós de fluxo de trabalho factual dos usuários assistant-single-model , assistant-multi-model e group-chat-example tentarão utilizar o projeto OfflineWikipediaTextApi para extrair artigos completos da Wikipedia para RAG. Se você não tiver essa API, o fluxo de trabalho não deverá apresentar problemas, mas eu pessoalmente uso essa API para ajudar a melhorar as respostas factuais que recebo. Você pode especificar o endereço IP da sua API no usuário json de sua escolha.
Primeiro, escolha qual usuário de modelo você gostaria de usar:
assistant-single-model : Este modelo é para um único modelo pequeno sendo usado em todos os nós. Isso também possui rotas para muitos tipos de categorias diferentes e usa predefinições apropriadas para cada nó. Se você está se perguntando por que existem rotas para categorias diferentes quando há apenas um modelo: é para que você possa dar a cada categoria suas próprias predefinições e também para criar fluxos de trabalho personalizados para elas. Talvez você queira que o codificador faça várias iterações para verificar a si mesmo ou que o raciocínio pense nas coisas em várias etapas.
assistant-multi-model : Este modelo serve para usar muitos modelos em conjunto. Observando os endpoints desse usuário, você pode ver que cada categoria tem seu próprio endpoint. Não há absolutamente nada que impeça você de reutilizar a mesma API para várias categorias. Por exemplo, você pode usar Llama 3.1 70b para codificação, matemática e raciocínio, e Command-R 35b 08-2024 para categorização, conversação e fatos. Não sinta que PRECISA de 10 modelos diferentes. Isto é simplesmente para permitir que você traga tantos, se quiser. Este usuário usa predefinições apropriadas para cada nó nos fluxos de trabalho.
convo-roleplay-single-model : Este usuário usa um modelo único com um fluxo de trabalho personalizado que é bom para conversas e deve ser bom para roleplay (aguardando feedback para ajustar, se necessário). Isso ignora todo o roteamento.
convo-roleplay-dual-model : Este usuário usa dois modelos com um fluxo de trabalho personalizado que é bom para conversas e deve ser bom para roleplay (aguardando feedback para ajustar, se necessário). Isso ignora todo o roteamento. NOTA : Este fluxo de trabalho funciona melhor se você tiver 2 computadores que possam executar LLMs. Com a configuração atual para este usuário, quando você envia uma mensagem para Wilmer, o modelo respondedor (computador 1) responderá a você. Em seguida, o fluxo de trabalho aplicará um "bloqueio de fluxo de trabalho" nesse ponto. O modelo de resumo de memória/bate-papo (computador 2) começará então a atualizar as memórias e o resumo da conversa até o momento, que é passado ao respondente para ajudá-lo a lembrar das coisas. Se você enviar outro prompt enquanto as memórias estão sendo escritas, o respondente (computador 1) pegará qualquer resumo existente e irá em frente e responderá a você. O bloqueio do fluxo de trabalho impedirá que você entre novamente na seção de novas memórias. O que isso significa é que você pode continuar conversando com seu modelo respondedor enquanto novas memórias estão sendo escritas. Este é um ENORME aumento de desempenho. Eu experimentei e, para mim, os tempos de resposta foram incríveis. Sem isso, obtenho respostas em 30 segundos, de 3 a 5 vezes, e de repente tenho uma espera de 2 minutos para gerar memórias. Com isso, cada mensagem dura 30 segundos, sempre, no Llama 3.1 70b no meu Mac Studio.
group-chat-example : Este usuário é um exemplo de meus próprios chats em grupo pessoais. Os personagens e os grupos incluídos são personagens e grupos reais que eu uso. Você pode encontrar os caracteres de exemplo na pasta Docs/SillyTavern . Esses são caracteres compatíveis com SillyTavern que você pode importar diretamente para esse programa ou qualquer programa que suporte tipos de importação de caracteres .png. Os personagens da equipe de desenvolvimento têm apenas 1 nó por fluxo de trabalho: eles simplesmente respondem a você. Os personagens do grupo consultivo têm 2 nós por fluxo de trabalho: o primeiro nó gera uma resposta e o segundo nó impõe a "persona" do personagem (o endpoint responsável por isso é o endpoint businessgroup-speaker ). As personas do chat em grupo ajudam muito a variar as respostas que você obtém, mesmo que você use apenas 1 modelo. No entanto, pretendo usar modelos diferentes para cada personagem (mas reutilizando modelos entre grupos; então, por exemplo, tenho um personagem modelo Llama 3.1 70b em cada grupo).
Depois de selecionar o usuário que deseja usar, há algumas etapas a serem executadas:
Atualize os endpoints do seu usuário em Public/Configs/Endpoints. Os caracteres de exemplo são classificados em pastas para cada um. A pasta do endpoint do usuário é especificada na parte inferior do arquivo user.json. Você desejará preencher cada endpoint adequadamente para os LLMs que está usando. Você pode encontrar alguns endpoints de exemplo na pasta _example-endpoints .
Você precisará definir seu usuário atual. Você pode fazer isso ao executar o arquivo bat/sh/py usando o argumento --User ou pode fazer isso em Public/Configs/Users/_current-user.json. Basta colocar o nome do usuário como usuário atual e salvar.
Você vai querer abrir o arquivo json do usuário e dar uma olhada nas opções. Aqui você pode definir se deseja streaming ou não, pode definir o endereço IP para sua API wiki offline (se estiver usando), especificar para onde deseja que seus arquivos de memórias/resumo vão durante os fluxos de DiscussionId e também especificar onde você deseja. deseja que o banco de dados sqllite funcione se você usar bloqueios de fluxo de trabalho.
É isso! Execute o Wilmer, conecte-se a ele e você estará pronto para prosseguir.
Primeiro, configuraremos os endpoints e os modelos. Dentro da pasta Public/Configs você deverá ver as seguintes subpastas. Vamos examinar o que você precisa.
Esses arquivos de configuração representam os terminais da API LLM aos quais você está conectado. Por exemplo, o seguinte arquivo JSON, SmallModelEndpoint.json , define um endpoint:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}Esses arquivos de configuração representam os diferentes tipos de API que você pode encontrar ao usar o Wilmer.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} Esses arquivos especificam o modelo de prompt para um modelo. Considere o seguinte exemplo, llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} Esses modelos são aplicados a todas as chamadas de endpoint v1/Completion. Se você preferir não usar um modelo, existe um arquivo chamado _chatonly.json que divide as mensagens apenas com novas linhas.
Criar e ativar um usuário envolve quatro etapas principais. Siga as instruções abaixo para configurar um novo usuário.
Primeiro, na pasta Users , crie um arquivo JSON para o novo usuário. A maneira mais fácil de fazer isso é copiar um arquivo JSON de usuário existente, colá-lo como duplicado e renomeá-lo. Aqui está um exemplo de arquivo JSON do usuário:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 , tornando-o visível na sua rede se for executado em outro computador. Há suporte para a execução de múltiplas instâncias do Wilmer em portas diferentes.true , o roteador é desabilitado e todos os prompts vão apenas para o fluxo de trabalho especificado, tornando-o uma única instância de fluxo de trabalho do Wilmer.customWorkflowOverride for true .Routing , sem a extensão .json .DiscussionId .chatCompleteAddUserAssistant for true .DataFinder do grupo de exemplo. Em seguida, atualize o arquivo _current-user.json para especificar qual usuário você deseja usar. Corresponda ao nome do novo arquivo JSON do usuário, sem a extensão .json .
NOTA : Você pode ignorar isso se quiser usar o argumento --User ao executar o Wilmer.
Crie um arquivo JSON de roteamento na pasta Routing . Este arquivo pode ter o nome que você quiser. Atualize a propriedade routingConfig no arquivo JSON do usuário com este nome, menos a extensão .json . Aqui está um exemplo de arquivo de configuração de roteamento:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json , acionado se a categoria for escolhida. Na pasta Workflow , crie uma nova pasta que corresponda ao nome de usuário da pasta Users . A maneira mais rápida de fazer isso é copiar a pasta de um usuário existente, duplicá-la e renomeá-la.
Se você optar por não fazer outras alterações, precisará passar pelos fluxos de trabalho e atualizar os endpoints para apontar para o endpoint desejado. Se você estiver usando um exemplo de fluxo de trabalho adicionado com Wilmer, então você já deve estar bem aqui.
Dentro da pasta "Público" você deverá ter:
Os fluxos de trabalho neste projeto são modificados e controlados na pasta Public/Workflows , dentro da pasta de fluxos de trabalho específica do seu usuário. Por exemplo, se o nome do seu usuário for socg e você tiver um arquivo socg.json na pasta Users , dentro dos fluxos de trabalho você deverá ter uma pasta Workflows/socg .
Aqui está um exemplo da aparência de um JSON de fluxo de trabalho:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
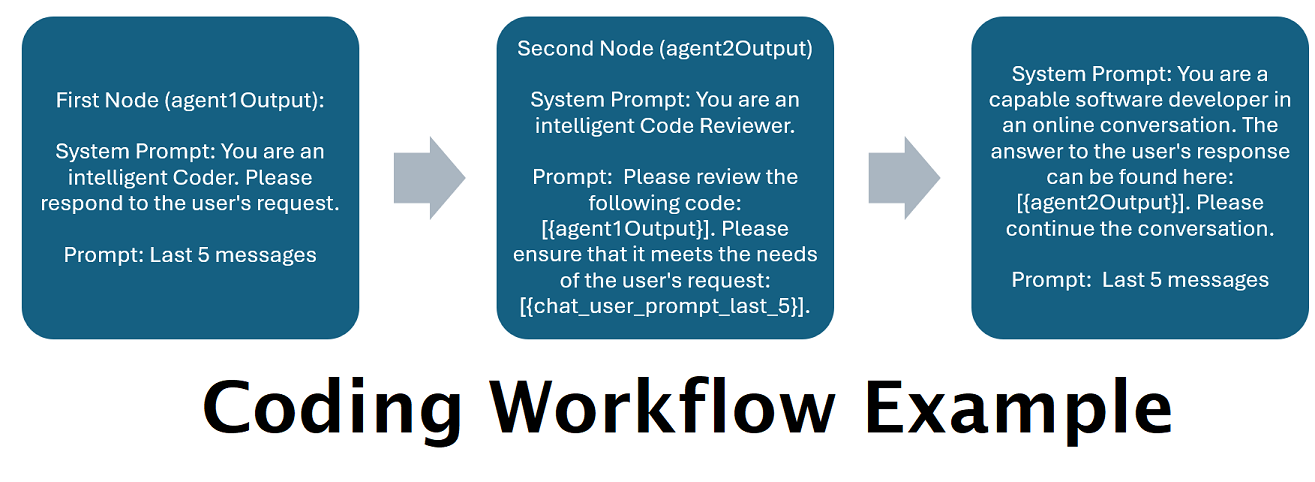
]O fluxo de trabalho acima é composto por nós de conversação. Ambos os nós fazem uma coisa simples: enviam uma mensagem ao LLM especificado no terminal.
title . É útil nomeá-los terminando em “Um”, “Dois”, etc., para acompanhar a saída do agente. A saída do primeiro nó é salva em {agent1Output} , a segunda em {agent2Output} e assim por diante.Endpoints , sem a extensão .json .Presets , sem a extensão .json .false (veja o primeiro nó de exemplo acima). Se você enviar um prompt, defina-o como true (veja o segundo nó de exemplo acima). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
Você pode usar várias variáveis dentro desses instruções. Estes serão substituídos adequadamente em tempo de execução:
{chat_user_prompt_last_one} : a última mensagem na conversa, sem tags de modelo de prompt que envolvem a mensagem.{templated_user_prompt_last_one} : A última mensagem na conversa, envolvida nas tags de modelo de prompt de usuário/assistente apropriado.{chat_system_prompt} : o prompt do sistema enviado do front end. Geralmente contém cartão de personagem e outras informações importantes.{templated_system_prompt} : o prompt do sistema do front -end, embrulhado na etiqueta de modelo de prompt do sistema apropriado.{agent#Output} : # é substituído pelo número desejado. Cada nó gera uma saída de um agente. O primeiro nó é sempre 1, e cada um dos nó subsequente incrementa em 1. Por exemplo, {agent1Output} para o primeiro nó, {agent2Output} para o segundo, etc.{category_colon_descriptions} : puxa as categorias e descrições do seu arquivo JSON Routing .{categoriesSeparatedByOr} : puxa os nomes de categoria, separados por "ou".[TextChunk] : Uma variável especial exclusiva para o processador paralelo, provavelmente não usado com frequência.Nota: Para uma compreensão mais profunda de como as memórias funcionam, consulte a seção de memórias de compreensão
Esse nó puxará N número de memórias (ou mensagens mais recentes se não houver discussão. Portanto, se você tiver um arquivo de memória com 3 memórias e escolher um delimitador de " n --------- n", poderá obter o seguinte:
This is the first memory
---------
This is the second memory
---------
This is the third memory
Combinar esse nó com o resumo do bate -papo pode permitir que o LLM receba não apenas o colapso resumido de toda a conversa como um todo, mas também uma lista de todas as memórias que o resumo foi construído, que pode conter informações mais detalhadas e granulares sobre isto. Enviar os dois juntos, juntamente com as últimas 15 a 20 mensagens, pode criar a impressão de uma memória contínua e persistente de todo o bate-papo para as mensagens mais recentes. Cuidados especiais para criar bons avisos para a geração das memórias podem ajudar a garantir que os detalhes que você se preocupa sejam capturados, enquanto detalhes menos pertinentes são ignorados.
Este nó não gerará novas memórias; Isso é para que os bloqueios do fluxo de trabalho possam ser respeitados se você os estiver usando em uma configuração multi-computador. Atualmente, a melhor maneira de gerar memórias é o nó FullChatsummary.


