Ainur
1.0.0
Ainur é um modelo inovador de aprendizagem profunda para geração de música multimodal condicional. Ele foi projetado para gerar amostras de música estéreo de alta qualidade a 48 kHz, condicionadas a uma variedade de entradas, como letras, descritores de texto e outros tipos de áudio. A arquitetura de difusão hierárquica do Ainur, combinada com incorporações CLASP, permite produzir composições musicais coerentes e expressivas em uma ampla gama de gêneros e estilos. 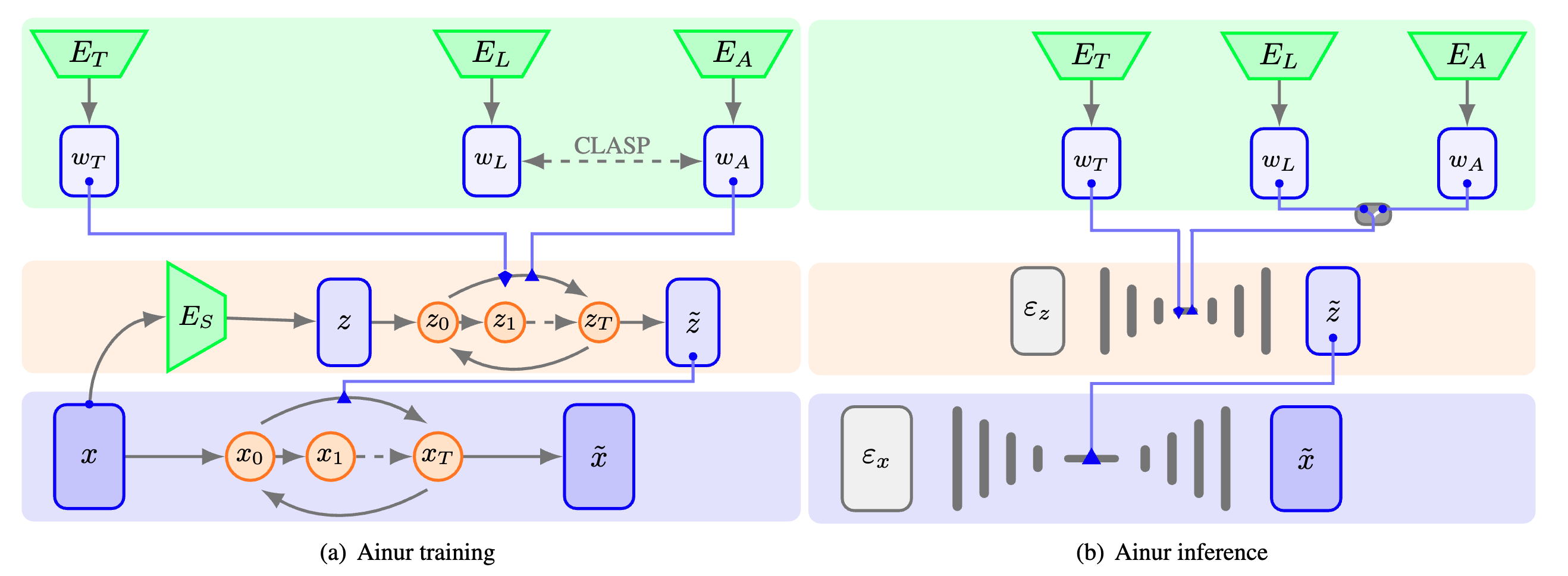

Geração Condicional: Ainur permite a geração de música condicionada a letras, descritores de texto ou outro áudio, oferecendo uma abordagem flexível e criativa à composição musical.
Saída de alta qualidade: O modelo é capaz de produzir amostras de música estéreo de 22 segundos a 48 kHz, garantindo alta fidelidade e realismo.
Aprendizagem multimodal: Ainur emprega embeddings CLASP, que são representações multimodais de letras e áudio, para facilitar o alinhamento de letras textuais com fragmentos de áudio correspondentes.
Avaliação objetiva: Fornecemos métricas de avaliação abrangentes, incluindo Frechet Audio Distance (FAD) e CLASP Cycle Consistency (C3), para avaliar a qualidade e a coerência da música gerada.
Para executar o Ainur, certifique-se de ter as seguintes dependências instaladas:
Python 3.8+
PyTorch 1.13.1
PyTorch Relâmpago 2.0.0
Você pode instalar os pacotes Python necessários executando:
pip instalar -r requisitos.txt
Clone este repositório:
clone do git https://github.com/ainur-music/ainur.gitcd ainur
Instale as dependências (conforme mencionado acima).
Execute Ainur com a entrada desejada. Confira os cadernos de exemplo na pasta de examples para obter orientação sobre como usar o Ainur para geração de música. ( em breve )
Ainur orienta a geração da música e melhora a qualidade dos vocais por meio de informações textuais e letras sincronizadas. Aqui estão alguns exemplos de insumos para treinar e gerar música com Ainur:
«Red Hot Chili Peppers, Alternative Rock, 7 of 19»
«[00:45.18] I got your hey oh, now listen what I say oh [...]»
Comparamos o desempenho do Ainur com outro modelo de última geração para geração de texto para música. Baseamos a avaliação em métricas objetivas como FAD e usando diferentes modelos de incorporação como referência: VGGish, YAMNet e Trill.
| Modelo | Taxa [kHz] | Comprimento[s] | Parâmetros [M] | Etapas de inferência | Tempo de inferência [s] ↓ | FAD VGGish ↓ | FAD YAMNet ↓ | Trinado FAD ↓ |
|---|---|---|---|---|---|---|---|---|
| Ainur | 48@2 | 22 | 910 | 50 | 14,5 | 8,38 | 20h70 | 0,66 |
| Ainur (sem CLASP) | 48@2 | 22 | 910 | 50 | 14,7 | 8h40 | 20,86 | 0,64 |
| ÁudioLDM | 16@1 | 22 | 181 | 200 | 2.20 | 15,5 | 784,2 | 0,52 |
| ÁudioLDM 2 | 16@1 | 22 | 1100 | 100 | 20,8 | 8,67 | 23,92 | 0,52 |
| MusicGen | 16@1 | 22 | 300 | 1500 | 81,3 | 14.4 | 53.04 | 0,66 |
| Juke-box | 16@1 | 1 | 1000 | - | 538 | 20.4 | 178,1 | 1,59 |
| MúsicaLM | 16@1 | 5 | 1890 | 125 | 153 | 15,0 | 61,58 | 0,47 |
| Rifusão | 44.1@1 | 5 | 890 | 50 | 6,90 | 5.24 | 15,96 | 0,67 |
Explore e ouça músicas geradas por Ainur aqui.
Você pode baixar pontos de verificação Ainur e CLASP pré-treinados do drive:
Melhor ponto de verificação de Ainur (modelo com menor perda durante o treinamento)
Último ponto de verificação de Ainur (modelo com maior número de etapas de treinamento)
Ponto de verificação CLASP
Este projeto está licenciado sob a licença MIT - consulte o arquivo LICENSE para obter detalhes.
© 2023 Giuseppe Concialdi


