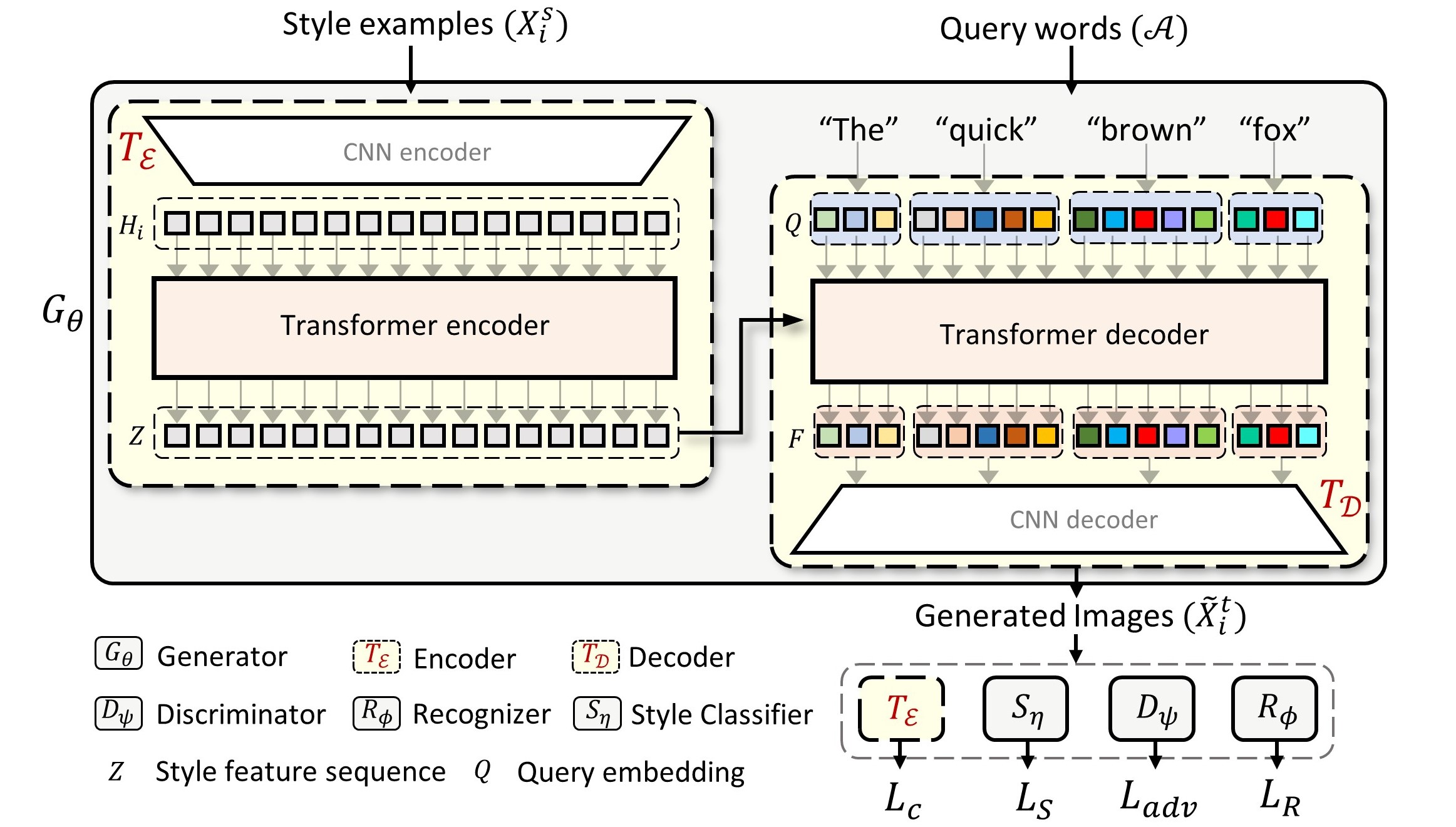
Handwriting Transformers
1.0.0
Projeto | ArXiv | Papel | Huggingface-demonstração | Demonstração Colab
2024.02 Teste o modelo usando amostras de caligrafia personalizadas:
Uma demonstração do Huggingface já está disponível e em execução
Demonstração do Colab para caligrafia personalizada
Demonstração do Colab para conjunto de dados IAM/CVL
Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Fahad Shahbaz Khan e Mubarak Shah
Resumo: Propomos uma nova abordagem de geração de imagens de texto manuscrito com estilo baseada em transformador, HWT, que se esforça para aprender tanto o emaranhamento estilo-conteúdo quanto os padrões de estilo de escrita globais e locais. O HWT proposto captura os relacionamentos de longo e curto alcance dentro dos exemplos de estilo através de um mecanismo de autoatenção, codificando assim padrões de estilo globais e locais. Além disso, o HWT baseado em transformador proposto compreende uma atenção codificador-decodificador que permite o emaranhamento estilo-conteúdo, reunindo a representação de estilo de cada caractere de consulta. Até onde sabemos, somos os primeiros a introduzir uma rede generativa baseada em transformador para geração de texto manuscrito estilizado. Nosso HWT proposto gera imagens de texto manuscritas com estilo realista e supera significativamente o estado da arte demonstrado por meio de extensas avaliações qualitativas, quantitativas e baseadas em humanos. O HWT proposto pode lidar com comprimentos arbitrários de texto e qualquer estilo de escrita desejado em poucas cenas. Além disso, nosso HWT generaliza bem para o cenário desafiador, onde as palavras e o estilo de escrita não são vistos durante o treinamento, gerando imagens de texto manuscrito com estilo realista.
Pitão 3.7
PyTorch >=1,4
Consulte INSTALL.md para instalar as bibliotecas necessárias. Você pode alterar o conteúdo do arquivo mytext.txt para visualizar a caligrafia gerada durante o treinamento.
Baixe arquivos e modelos do conjunto de dados em https://drive.google.com/file/d/16g9zgysQnWk7-353_tMig92KsZsrcM6k/view?usp=sharing e descompacte dentro da pasta files . Resumindo, execute as seguintes linhas em um terminal bash.
clone git https://github.com/ankanbhunia/Handwriting-Transformerscd Handwriting-Transformers pip install --upgrade --no-cache-dir gdown gdown --id 16g9zgysQnWk7-353_tMig92KsZsrcM6k && descompacte arquivos.zip && rm arquivos.zip
Para começar a treinar o modelo: execute
python train.py
Se você quiser usar wandb , instale-o e altere seu auth_key no arquivo train.py (ln:4).
Você pode alterar diferentes parâmetros no arquivo params.py .
Você pode treinar o modelo em qualquer conjunto de dados personalizado que não seja IAM e CVL. O processo envolve a criação de um arquivo dataset_name.pickle e sua colocação dentro da pasta files . A estrutura de dataset_name.pickle é um dicionário python simples.
{'train': [{writer_1:[{'img': <PIL.IMAGE>, 'label':<str_label>},...]}, {writer_2:[{'img': <PIL.IMAGE> , 'rótulo':<str_label>},...]},...],
'teste': [{writer_3:[{'img': <PIL.IMAGE>, 'rótulo':<str_label>},...]}, {writer_4:[{'img': <PIL.IMAGE>, 'rótulo':<str_label>},...]},...],
}docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/ankankbhunia-hwt:latest python app.py
Por favor, verifique a pasta de results no repositório para ver mais análises qualitativas. Além disso, confira a demonstração do colab para experimentar seu próprio texto e estilo de escrita personalizados

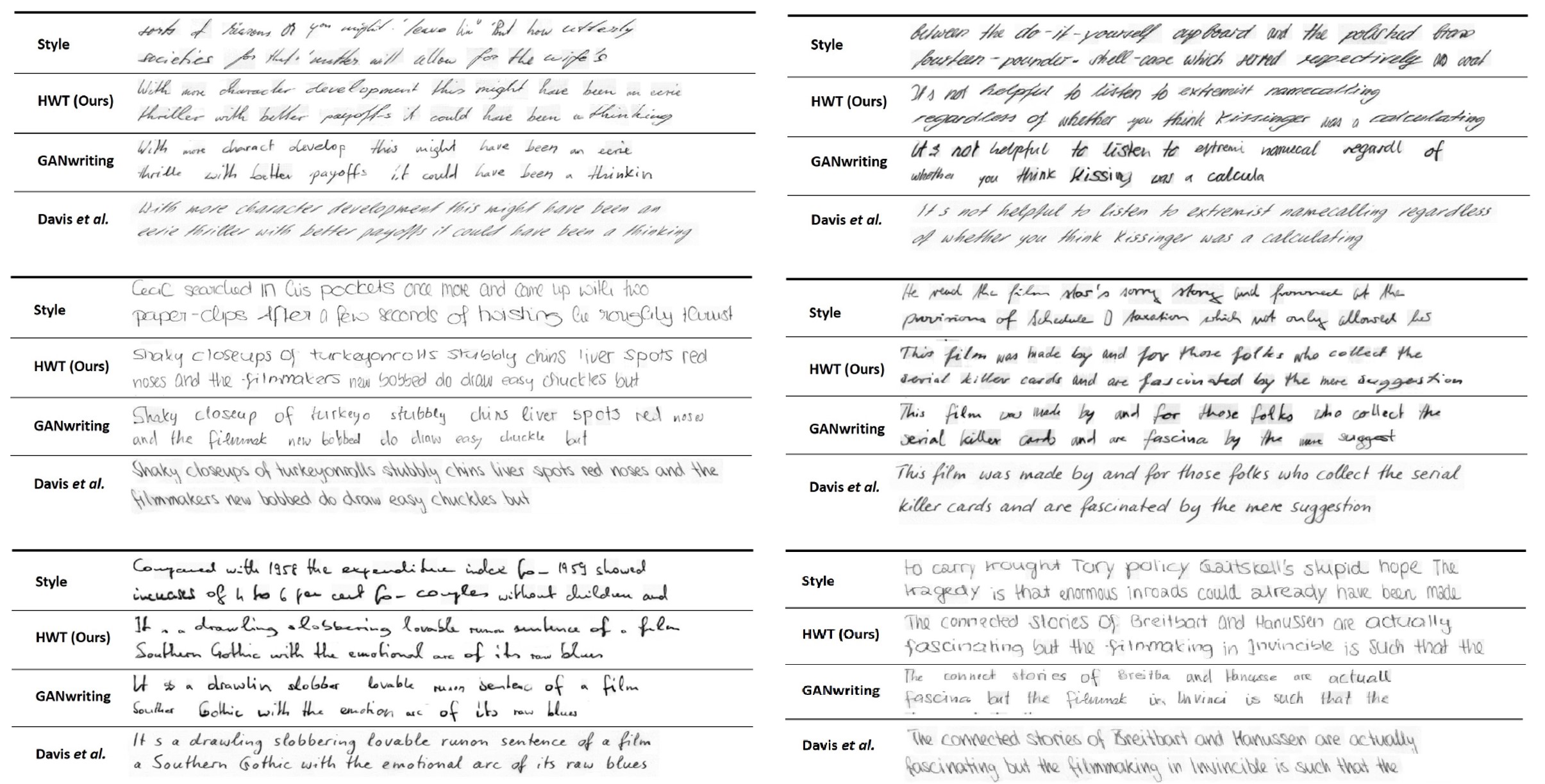
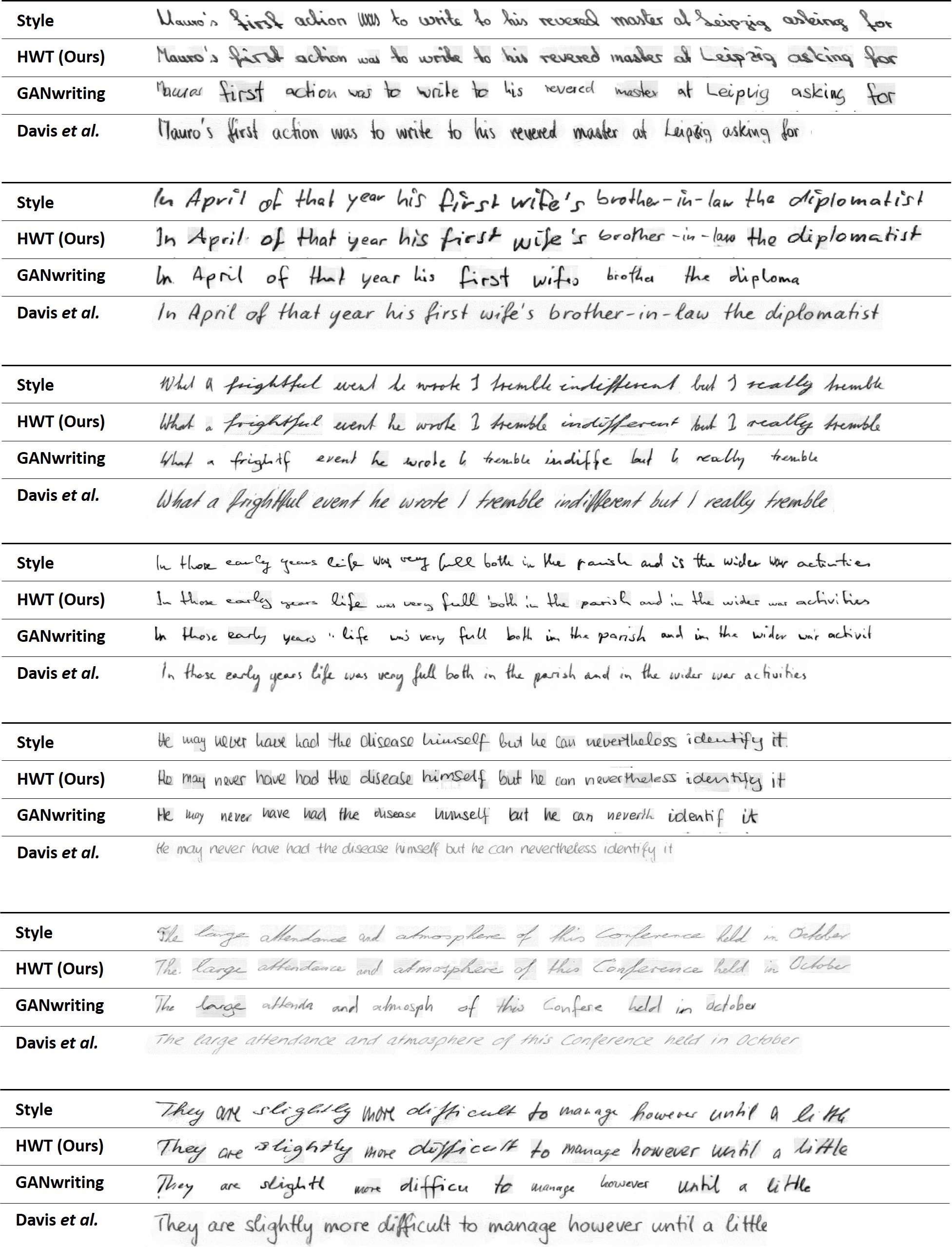
Resultados de reconstrução usando o HWT proposto em comparação com GANwriting e Davis et al. Usamos o mesmo texto dos exemplos de estilo para gerar imagens manuscritas.
Se você usar o código para sua pesquisa, cite nosso artigo:
@InProceedings{Bhunia_2021_ICCV,
author = {Bhunia, Ankan Kumar and Khan, Salman and Cholakkal, Hisham and Anwer, Rao Muhammad and Khan, Fahad Shahbaz and Shah, Mubarak},
title = {Handwriting Transformers},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {1086-1094}
} 

