fastsag
1.0.0
Esta é uma implementação PyTorch/GPU do artigo IJCAI 2024 FastSAG: Towards Fast Non-Autoregressive Singing Accompaniment Generation. A página de demonstração pode ser encontrada em demo.
@article{chen2024fastsag,
title={FastSAG: Towards Fast Non-Autoregressive Singing Accompaniment Generation},
author={Chen, Jianyi and Xue, Wei and Tan, Xu and Ye, Zhen and Liu, Qifeng and Guo, Yike},
journal={arXiv preprint arXiv:2405.07682},
year={2024}
}Baixe este código:
git clone https://github.com/chenjianyi/fastsag/ cd fastsag
Baixe o checkpoint fastsag aqui e coloque todos os pesos em fastsag/weights
Os pontos de verificação BigvGAN podem ser baixados do BigvGAN. Os pontos de verificação que usamos são "bigvgan_24khz_100band". Eu atualizo BigvGAN para BigvGAN-v2 e os pontos de verificação serão baixados automaticamente.
Os pontos de verificação pré-treinados do MERT seriam baixados automaticamente do huggingface. Por favor, certifique-se de que seu servidor possa acessar o huggingface.
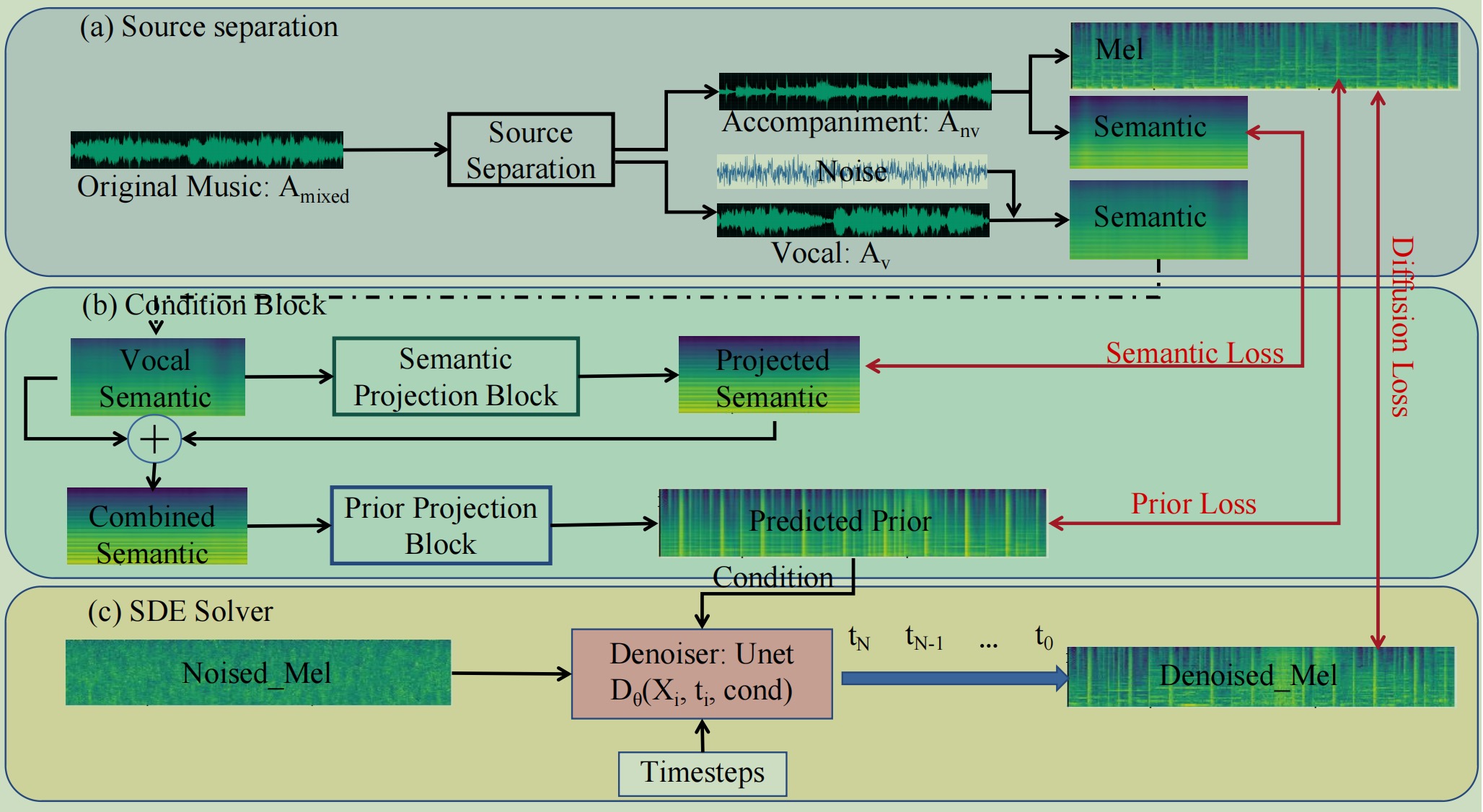
Separação de fontes:
cd preprocessing python3 demucs_processing.py # you may need to change root_dir and out_dir in this file
recortando em 10s e filtrando clipes salientes
python3 clip_to_10s.py # change src_root and des_root for your dataset
cd ../sde_diffusion python3 train.py --data_dir YOUR_TRAIN_DATA --data_dir_testset YOUR_TEST_DATA --results_folder RESULTS
python3 generate.py --ckpt TRAINED_MODEL --data_dir DATA_DIR --result_dir OUTPUT
Grad-TTS.
CoMoSpeech


