hands on llms
1.0.0
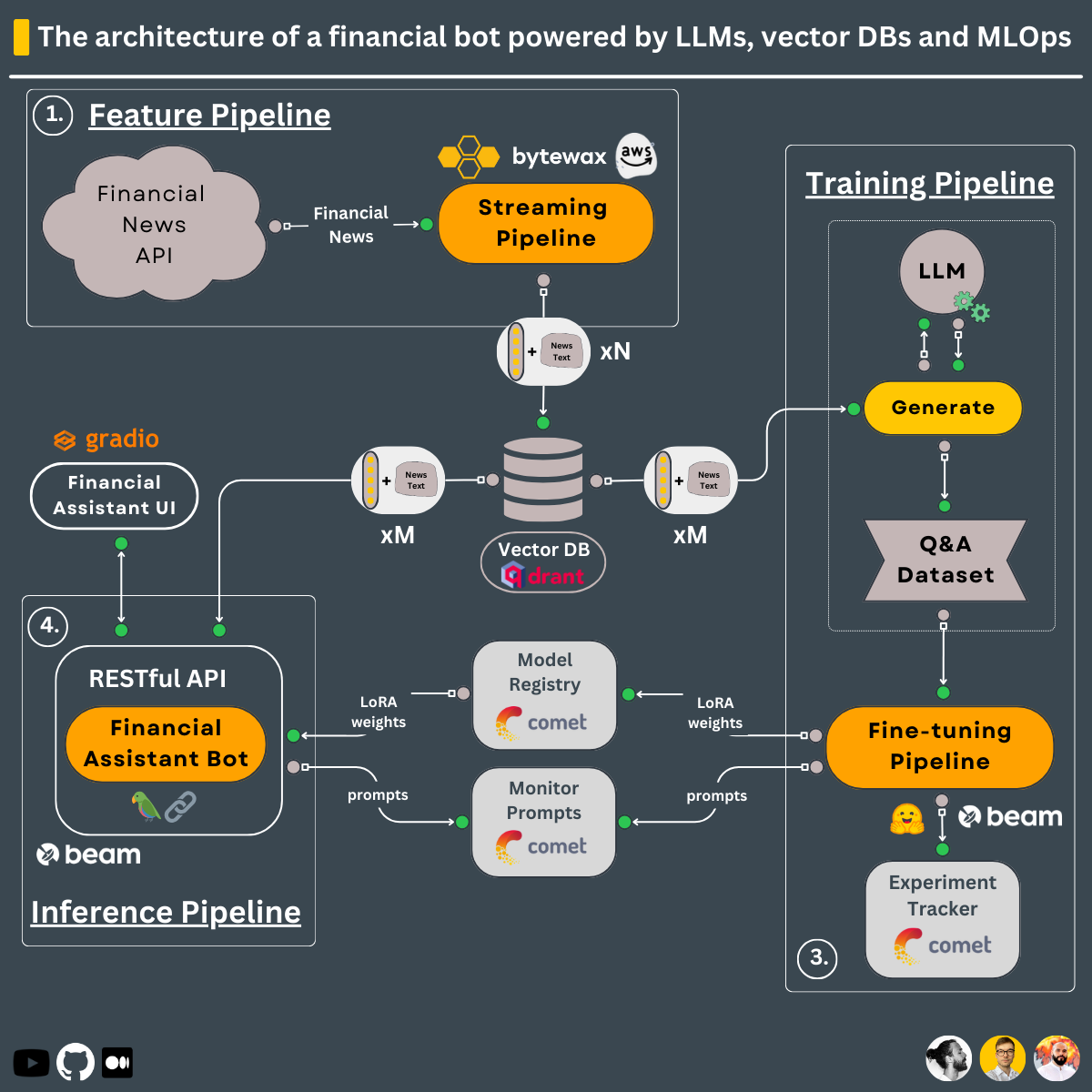
Usando o design de 3 pipelines, é isso que você aprenderá a construir neste curso ↓
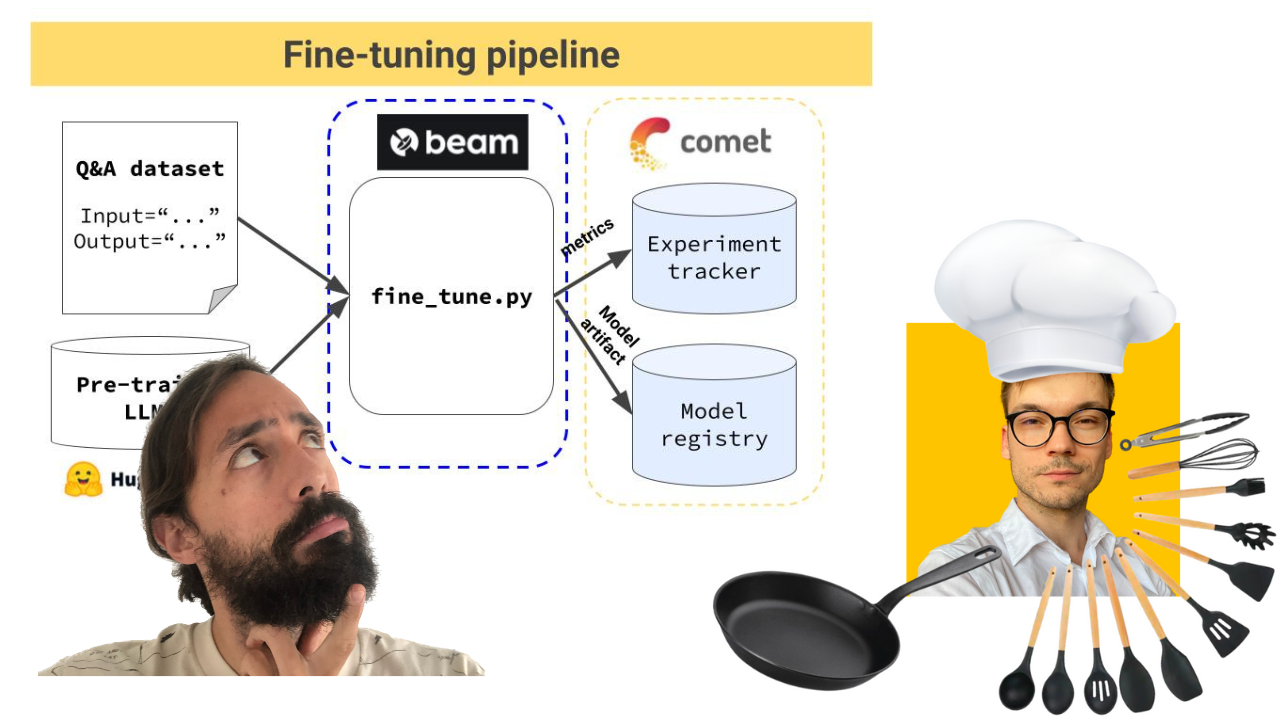
Pipeline de treinamento que:
O pipeline de treinamento é implantado usando o Beam como uma infraestrutura de GPU sem servidor.
-> Encontrado no diretório modules/training_pipeline .
Nota: Não se preocupe se não tiver os requisitos mínimos de hardware. Mostraremos como implantar o pipeline de treinamento na infraestrutura sem servidor do Beam e treinar o LLM lá.
Pipeline de recursos em tempo real que:
O pipeline de streaming é implantado automaticamente em uma máquina AWS EC2 usando um pipeline de CI/CD criado em ações do GitHub.
-> Encontrado no diretório modules/streaming_pipeline .
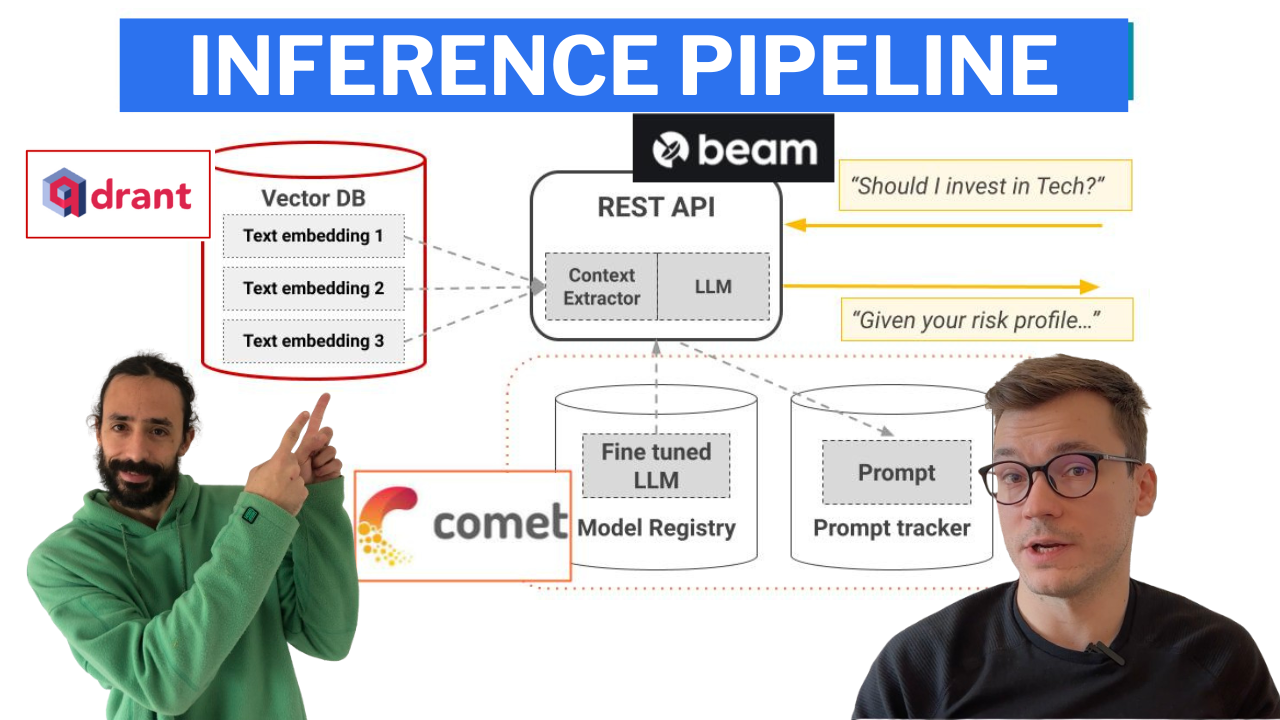
Pipeline de inferência que usa LangChain para criar uma cadeia que:
O pipeline de inferência é implantado usando o Beam como uma infraestrutura de GPU sem servidor, como uma API RESTful. Além disso, ele é agrupado em uma UI para fins de demonstração, implementada no Gradio.
-> Encontrado no diretório modules/financial_bot .
Nota: Não se preocupe se não tiver os requisitos mínimos de hardware. Mostraremos como implantar o pipeline de inferência na infraestrutura sem servidor do Beam e chamar o LLM a partir daí.
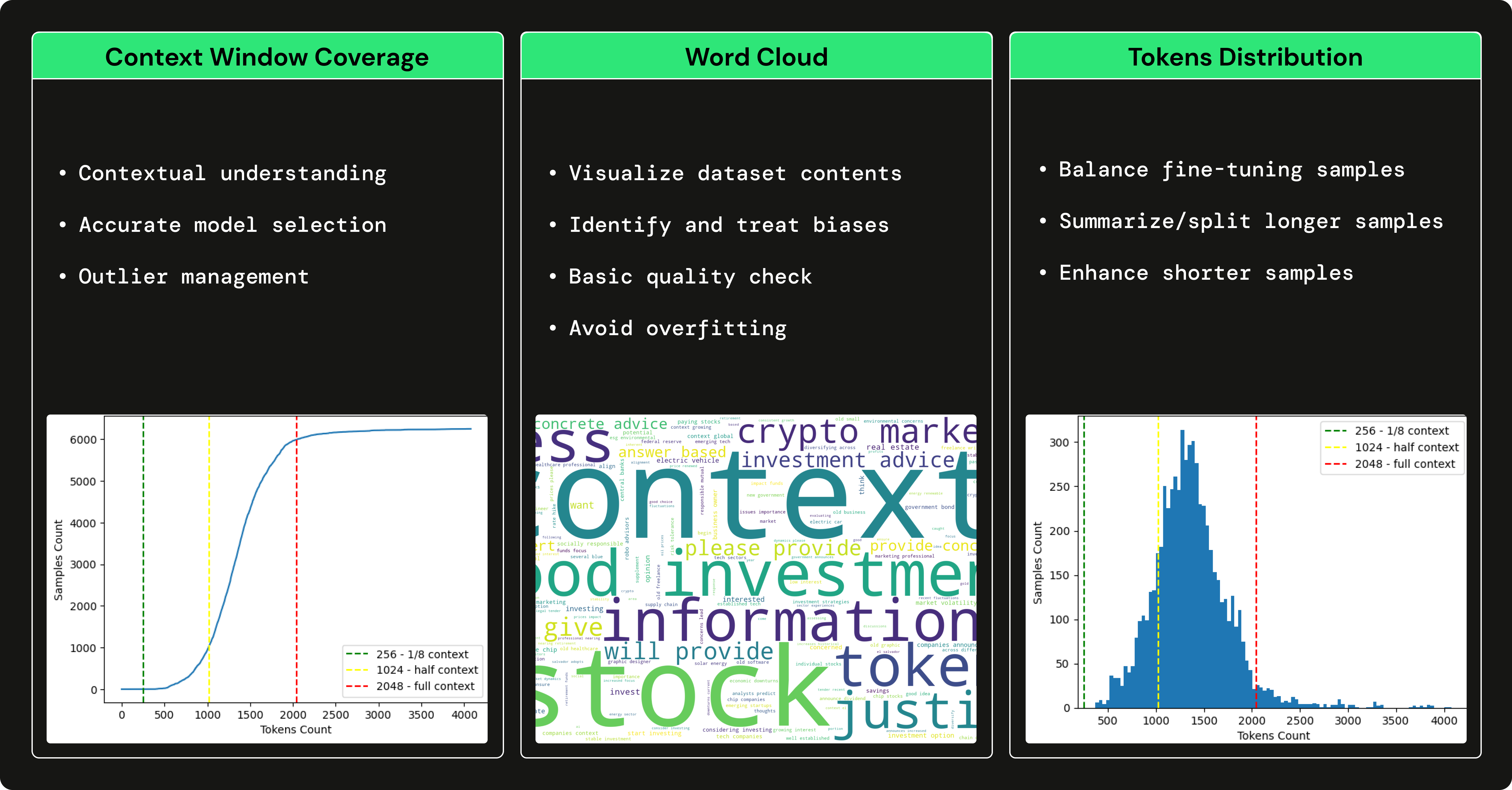
Usamos GPT3.5 para gerar um conjunto de dados de perguntas e respostas financeiras para ajustar nosso LLM de código aberto para nos especializarmos no uso de termos financeiros e na resposta a perguntas financeiras. Usar um LLM grande, como GPT3.5 para gerar um conjunto de dados que treina um LLM menor (por exemplo, Falcon 7B) é conhecido como ajuste fino com destilação .
→ Para entender como geramos o conjunto de dados financeiros de perguntas e respostas, confira este artigo escrito por Pau Labarta.
→ Para ver uma análise completa do conjunto de dados de perguntas e respostas financeiras, verifique a subseção dataset_análise do curso escrito por Alexandru Razvant.
Antes de mergulhar nos módulos, você deve configurar algumas ferramentas externas adicionais para o curso.
NOTA: Você pode configurá-los conforme avança para cada módulo, pois indicaremos em cada módulo o que você precisa.
financial news data source
Siga este documento para mostrar como criar uma conta GRATUITA e gerar as chaves de API necessárias neste curso.
Nota: 1 conexão de dados Alpaca é GRATUITA.
serverless vector DB
Vá para Qdrant e crie uma conta GRATUITA.
Depois, siga este documento sobre como gerar as chaves API que você precisará neste curso.
Observação: usaremos apenas o plano freemium do Qdrant.
serverless ML platform
Vá para Comet ML e crie uma conta GRATUITA.
Depois, siga este guia para gerar uma API KEY e um novo projeto, que você precisará dentro do curso.
Nota: Usaremos apenas o plano freemium do Comet ML.
serverless GPU compute | training & inference pipelines
Vá para o Beam e crie uma conta GRATUITA.
Depois, você deve seguir o guia de instalação para instalar a CLI e configurá-la com suas credenciais do Beam.
Para ler mais sobre o Beam, aqui está um guia de introdução.
Observação: você tem aproximadamente 10 horas de computação gratuitas. Depois, você paga apenas pelo que usar. Se você tiver uma GPU Nvidia >8 GB VRAM e não quiser implantar os pipelines de treinamento e inferência, usar o Beam é opcional.
Ao usar o Poetry, tivemos problemas para localizar a CLI do Beam dentro de um ambiente virtual do Poetry. Para corrigir isso, após instalar o Beam, criamos um link simbólico que aponta para os binários do Poetry, como segue:
export COURSE_MODULE_PATH= < your-course-module-path > # e.g., modules/training_pipeline
cd $COURSE_MODULE_PATH
export POETRY_ENV_PATH= $( dirname $( dirname $( poetry run which python ) ) )
ln -s /usr/local/bin/beam ${POETRY_ENV_PATH} /bin/beam cloud compute | feature pipeline
Acesse AWS, crie uma conta e gere um par de credenciais.
Depois, baixe e instale o AWS CLI v2.11.22 e configure-o com suas credenciais.
Observação: você pagará apenas pelo que usar. Você implantará apenas uma VM EC2 t2.small , que custa apenas ~$0.023 /hora. Se você não quiser implantar o pipeline de recursos, usar a AWS será opcional.
Cada módulo tem suas dependências e scripts. Numa configuração de produção, cada módulo teria seu repositório, mas neste caso de uso, para fins de aprendizagem, colocamos tudo em um só lugar:
Portanto, verifique o README de cada módulo individualmente para ver como instalá-lo e usá-lo:
Recomendamos fortemente que você clone este repositório e replique tudo o que fizemos para aproveitar ao máximo este curso.
Nas vídeo-aulas, nos artigos e na documentação README de cada módulo, você encontrará instruções passo a passo.
Feliz aprendizado!
O código GitHub (lançado sob a licença MIT) e as videoaulas (lançadas no YouTube) são totalmente gratuitos. Sempre será.
As aulas do Medium são lançadas no mural pago do Medium. Se você já tem, eles são gratuitos. Caso contrário, você deverá pagar uma taxa mensal de US$ 5 para ler os artigos.
Se você tiver alguma dúvida ou problema durante o curso, encorajamos você a criar um problema neste repositório onde você possa explicar tudo o que precisa em profundidade.
Caso contrário, você também pode entrar em contato com os professores no LinkedIn:
Clique aqui para assistir ao vídeo?

Clique aqui para assistir ao vídeo?
Clique aqui para assistir ao vídeo?

Clique aqui para assistir ao vídeo?

Clique aqui para assistir ao vídeo?
To understand the entire code step-by-step, check out our articles ↓
Este curso é um projeto de código aberto lançado sob a licença do MIT. Assim, desde que você distribua nossa LICENÇA e reconheça nosso trabalho, você pode clonar ou bifurcar este projeto com segurança e usá-lo como fonte de inspiração para o que quiser (por exemplo, projetos universitários, projetos de graduação universitária, etc.).
 | Pau Labarta Baixo | Engenheiro Sênior de ML e MLOps Professor principal. O cara das videoaulas. Twitter/X YouTube Boletim informativo sobre ML do mundo real Site de ML do mundo real |
 | Alexandru Razvant | Engenheiro Sênior de ML Segundo chef. O engenheiro nos bastidores. Neura salta |
 | Paulo Iusztin | Engenheiro Sênior de ML e MLOps Chefe principal. A galera que aparece aleatoriamente nas videoaulas. Twitter/X Decodificando boletim informativo de ML Site pessoal | Centro de ML e MLOps |


