bedrock agents infer models
1.0.0
Este projeto serve como base para os desenvolvedores estenderem seus casos de uso a vários modelos de linguagem grandes (LLMs) usando agentes Amazon Bedrock. O objetivo é mostrar o potencial de aproveitar vários modelos no Bedrock para criar respostas encadeadas que se adaptem a diversos cenários. Além de gerar resultados baseados em texto, este aplicativo também oferece suporte à criação e exame de imagens usando geração de imagens e modelos de texto para imagem. Esta funcionalidade expandida aumenta a versatilidade do aplicativo, tornando-o adequado para casos de uso mais criativos e visuais.
Para aqueles que preferem uma abordagem de infraestrutura como código (IaC), também fornecemos um modelo AWS CloudFormation que configura os componentes principais, como um agente Amazon Bedrock, um bucket S3 e uma função Lambda. Se preferir implantar este projeto por meio do AWS CloudFormation, consulte o guia do workshop aqui.
Como alternativa, este README orientará você no processo passo a passo para instalar e configurar manualmente os agentes Amazon Bedrock por meio do Console AWS, oferecendo flexibilidade para experimentar os modelos mais recentes e desbloquear totalmente o potencial dos agentes Bedrock.
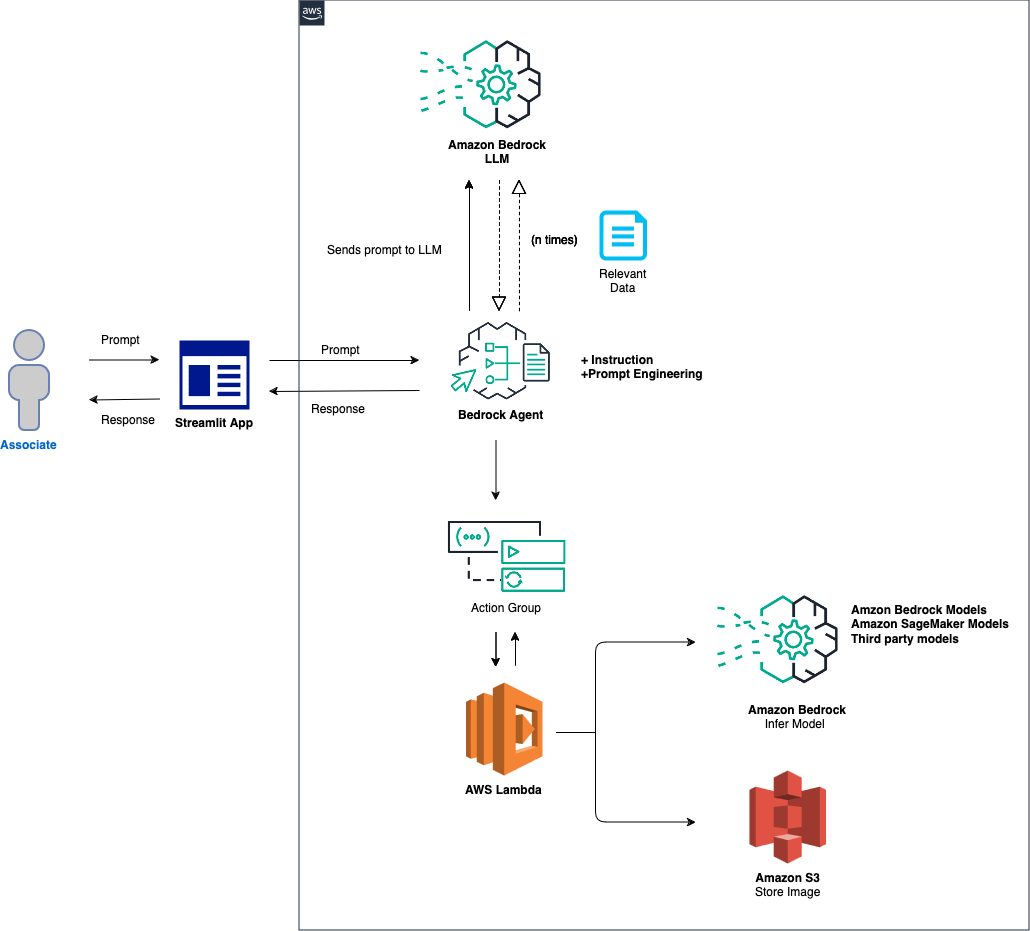
A visão geral de alto nível da solução é a seguinte:
Configuração de agente e ambiente: a solução começa configurando um agente Amazon Bedrock, uma função AWS Lambda e um bucket Amazon S3. Esta etapa estabelece a base para a interação do modelo e manipulação de dados, preparando o sistema para receber e processar prompts de um aplicativo front-end. Processamento de prompt e inferência de modelo: quando um prompt é recebido do aplicativo front-end, o agente Bedrock avalia e envia o prompt, junto com o ID do modelo especificado, para a função Lambda usando o mecanismo de grupo de ação. Esta etapa aproveita o esquema de API do grupo de ação para manipulação precisa de parâmetros, facilitando a inferência eficaz do modelo com base no prompt de entrada. Tratamento de dados e geração de resposta: para tarefas que envolvem conversão de imagem em texto ou de texto em imagem, a função Lambda interage com o bucket S3 para executar as operações necessárias de leitura ou gravação em imagens. Esta etapa garante o tratamento dinâmico do conteúdo multimídia, culminando na geração de respostas ou transformações ditadas pelo prompt inicial.
Nas seções a seguir, iremos guiá-lo através de:
AWS SAM (Serverless Application Model) é uma estrutura de código aberto que ajuda você a construir aplicativos sem servidor na AWS. Ele simplifica a implantação, o gerenciamento e o monitoramento de recursos sem servidor, como AWS Lambda, Amazon API Gateway, Amazon DynamoDB e muito mais. Aqui está um guia completo sobre como configurar e usar o AWS SAM.
A estrutura simplifica o processo de criação, implantação e gerenciamento de aplicativos sem servidor, abstraindo as complexidades da infraestrutura em nuvem. Ele fornece uma maneira unificada de definir e gerenciar recursos sem servidor usando um arquivo de configuração e um conjunto de comandos.
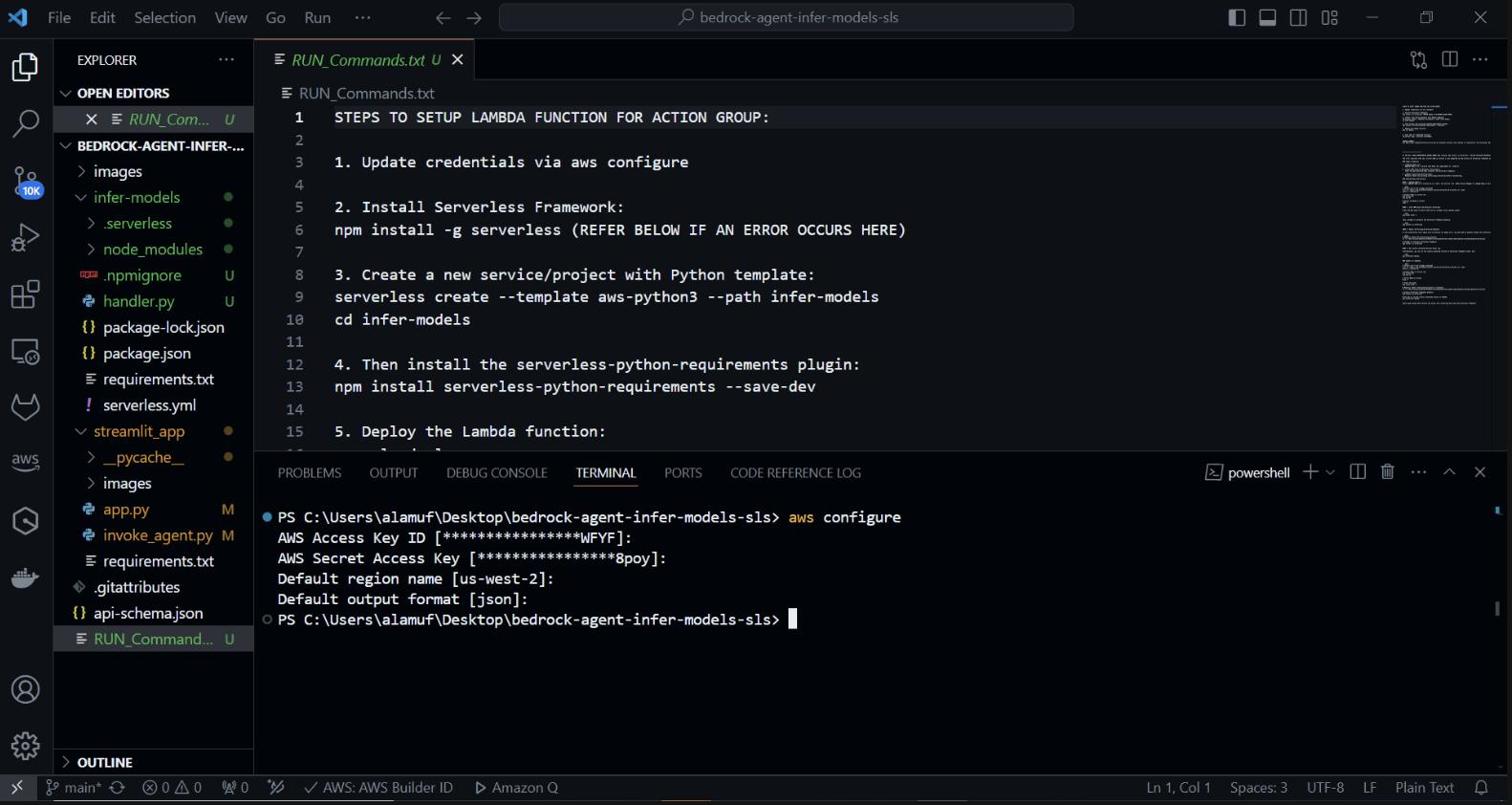
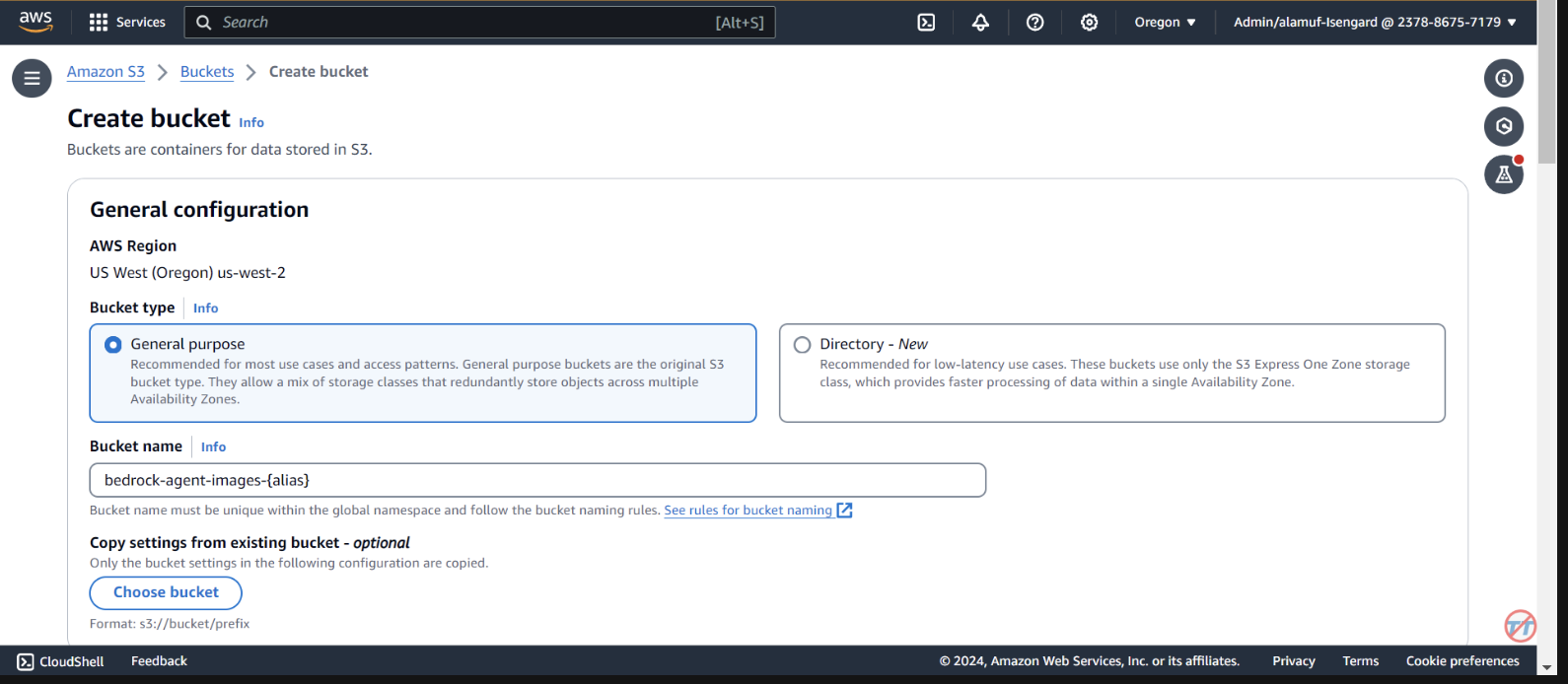
Crie um novo projeto Serverless com um modelo Python. No seu terminal, execute: cd infer-models Em seguida, execute serverless 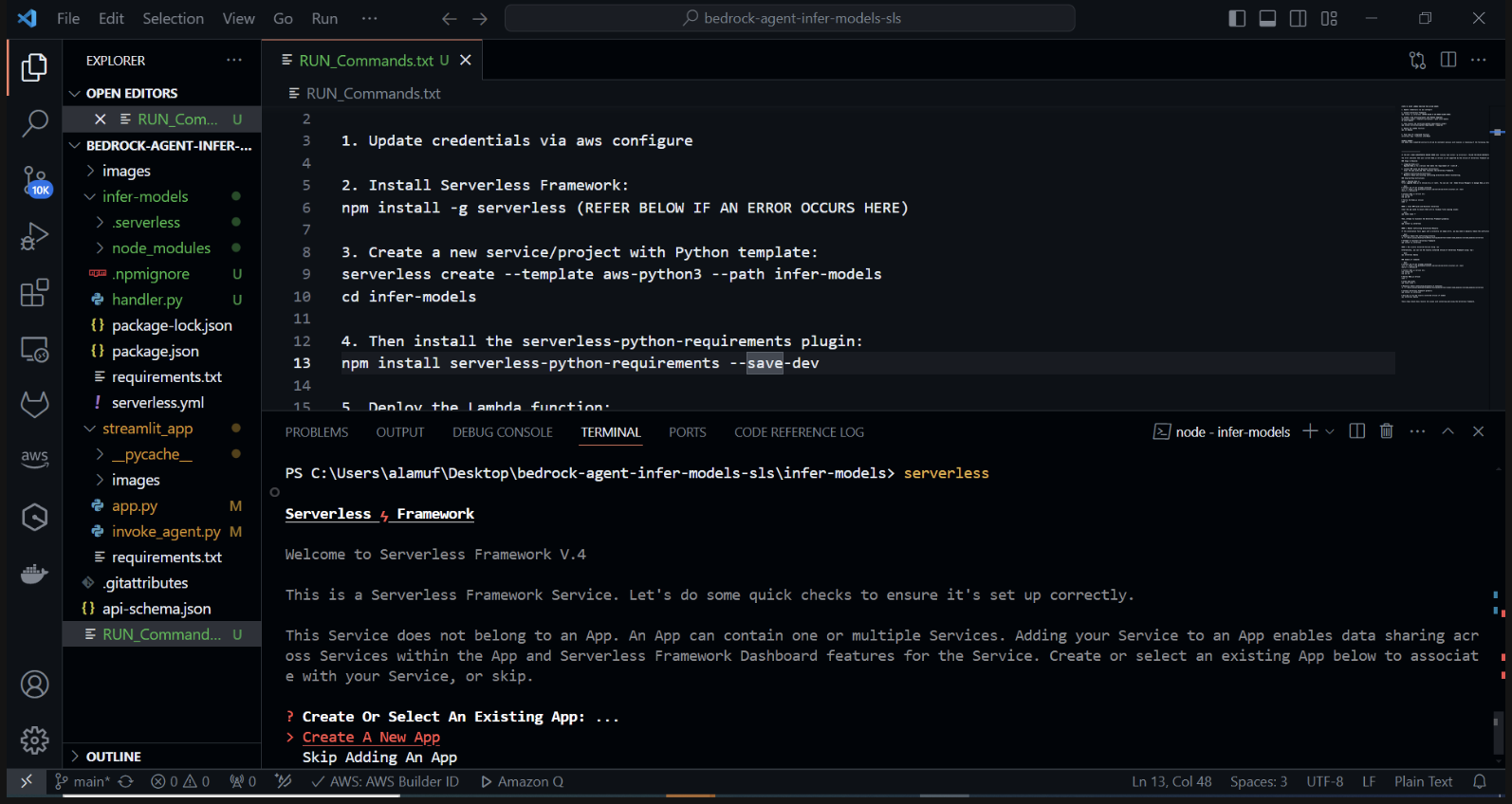
Isso iniciará o processo de criação de projeto interativo do Serverless Framework. Você verá várias opções: Escolha "Criar novo aplicativo Serverless". Selecione o modelo “aws-python3” e forneça “infer-models” como o nome do seu projeto.
Isso criará um novo diretório chamado infer-models com uma estrutura básica de projeto sem servidor e um modelo Python.
Você também pode ser solicitado a fazer login/registrar-se. selecione a opção "Login/Cadastro". Isso abrirá uma janela do navegador onde você poderá criar uma nova conta ou fazer login, se já tiver uma. Após fazer login ou criar uma conta, escolha a opção “Framework Open Source”, de uso gratuito.
Se sua pilha falhar na implantação, comente a linha 2 do arquivo serverless.yml
Após executar o comando serverless e seguir os prompts, um novo diretório com o nome do projeto (por exemplo, infer-models) será criado, contendo a estrutura padrão e os arquivos de configuração do projeto Serverless.
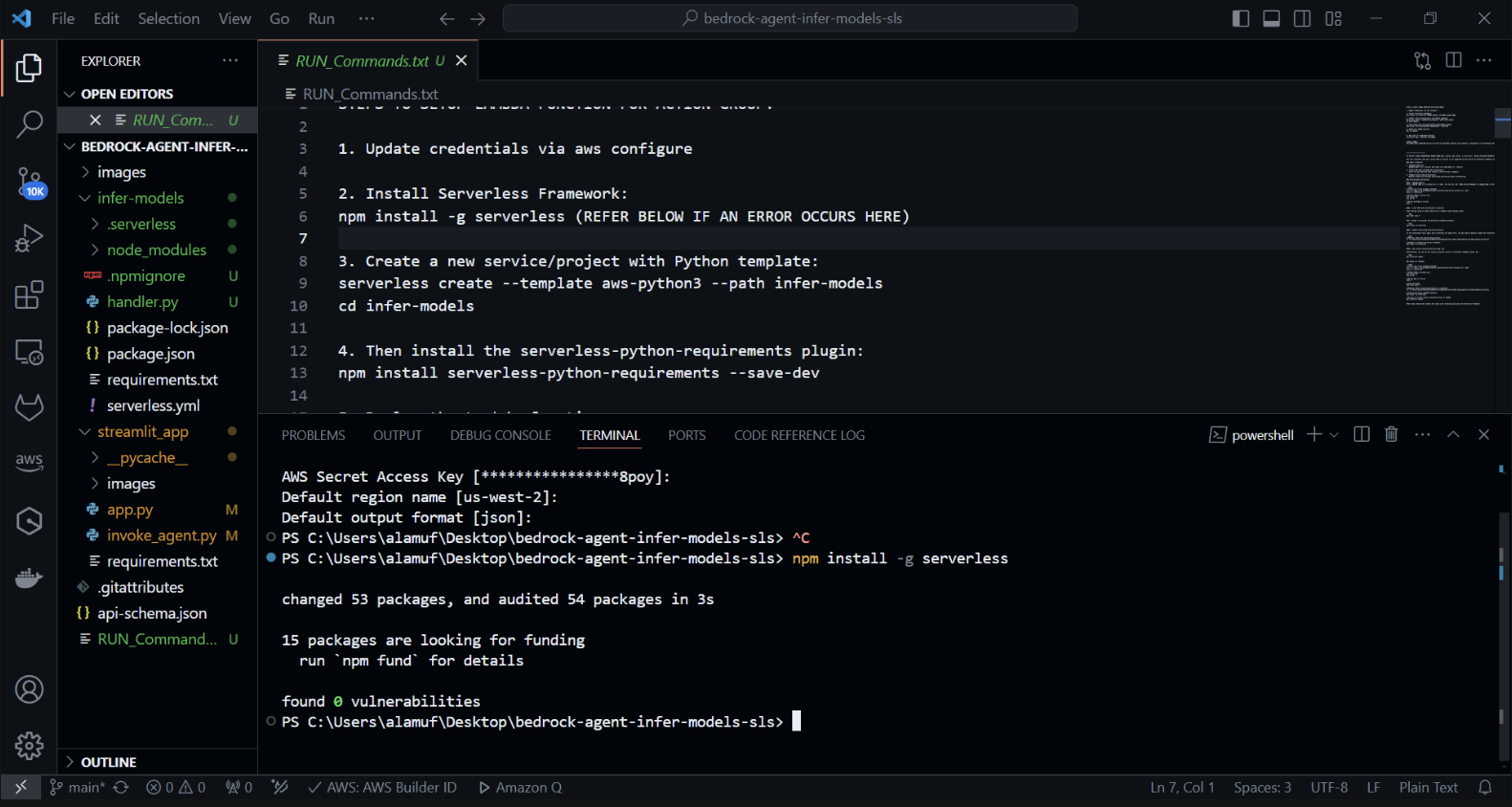
Agora instalaremos o plug-in serverless-python-requirements: O plug-in serverless-python-requirements ajuda a gerenciar dependências Python para seu projeto Serverless. Instale-o executando:
npm install serverless-python-requirements —save-dev
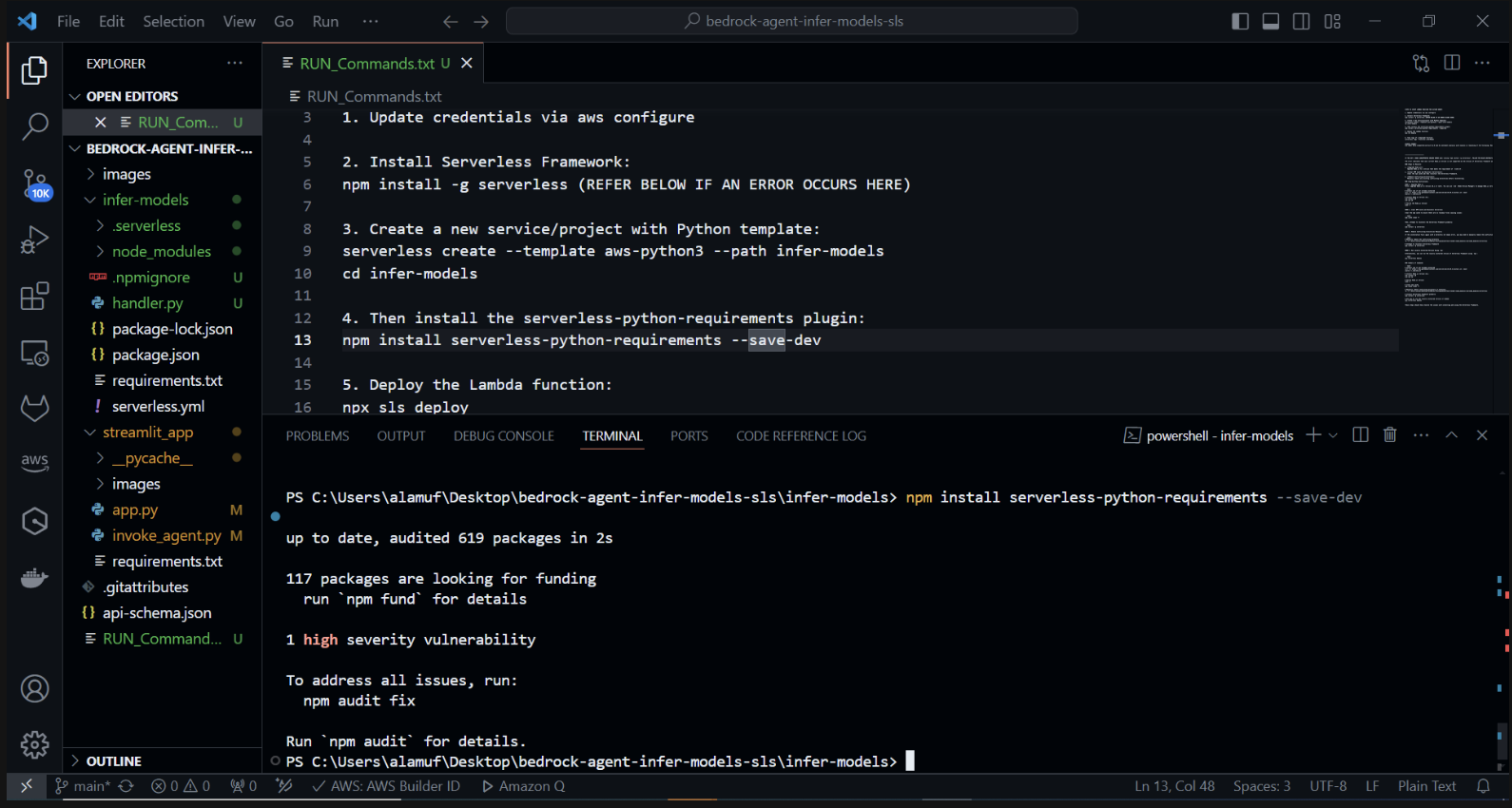
3.) npx sls deploy
(ANTES DE EXECUTAR O COMANDO ACIMA, O DOCKER ENGINE PRECISARÁ SER INSTALADO E FUNCIONADO. MAIS INFORMAÇÕES PODEM SER ENCONTRADAS AQUI)
(Isso irá empacotar e implantar a função AWS Lambda) 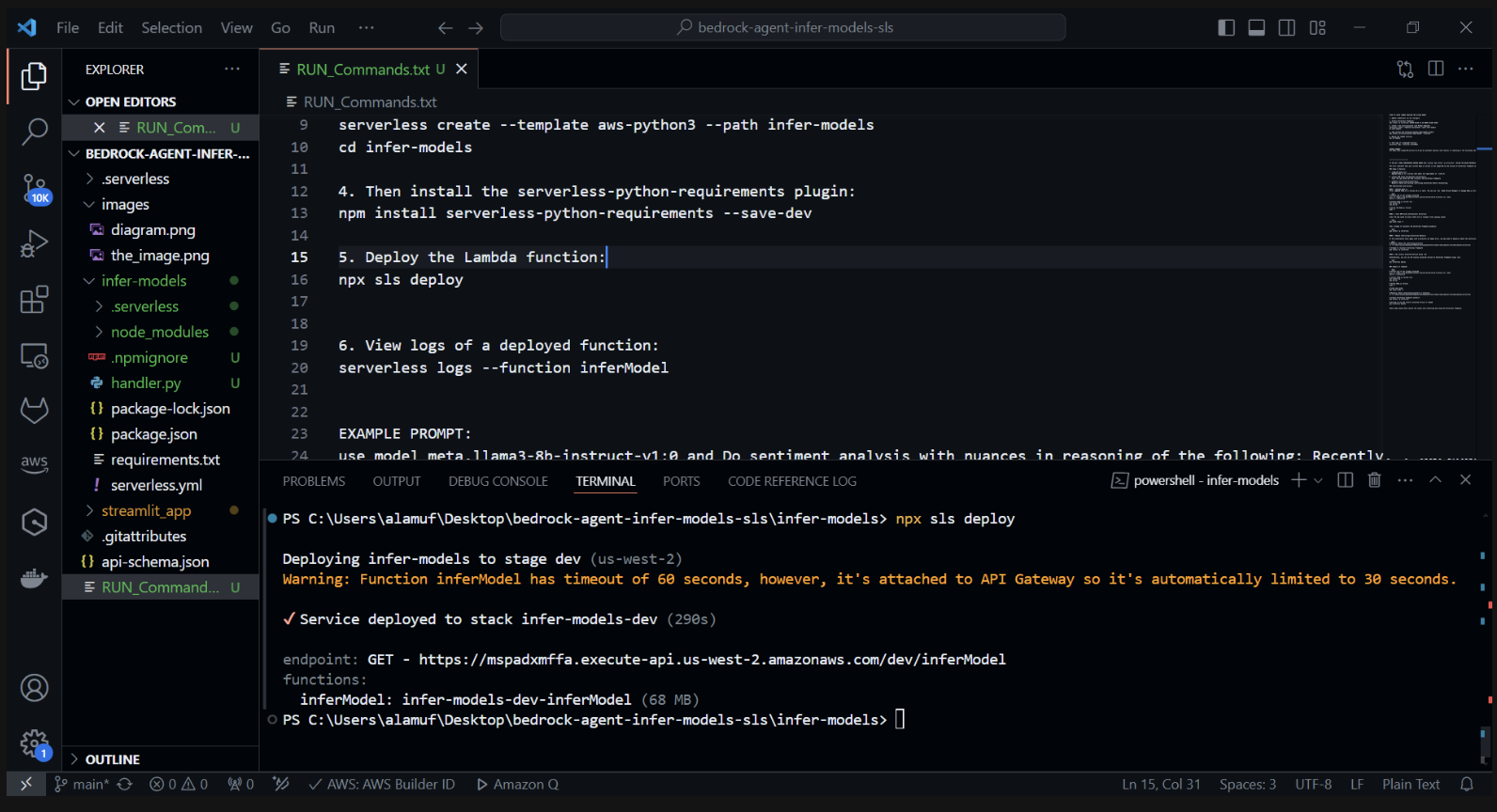
Inspecione a implantação no CloudFormation no Console AWS
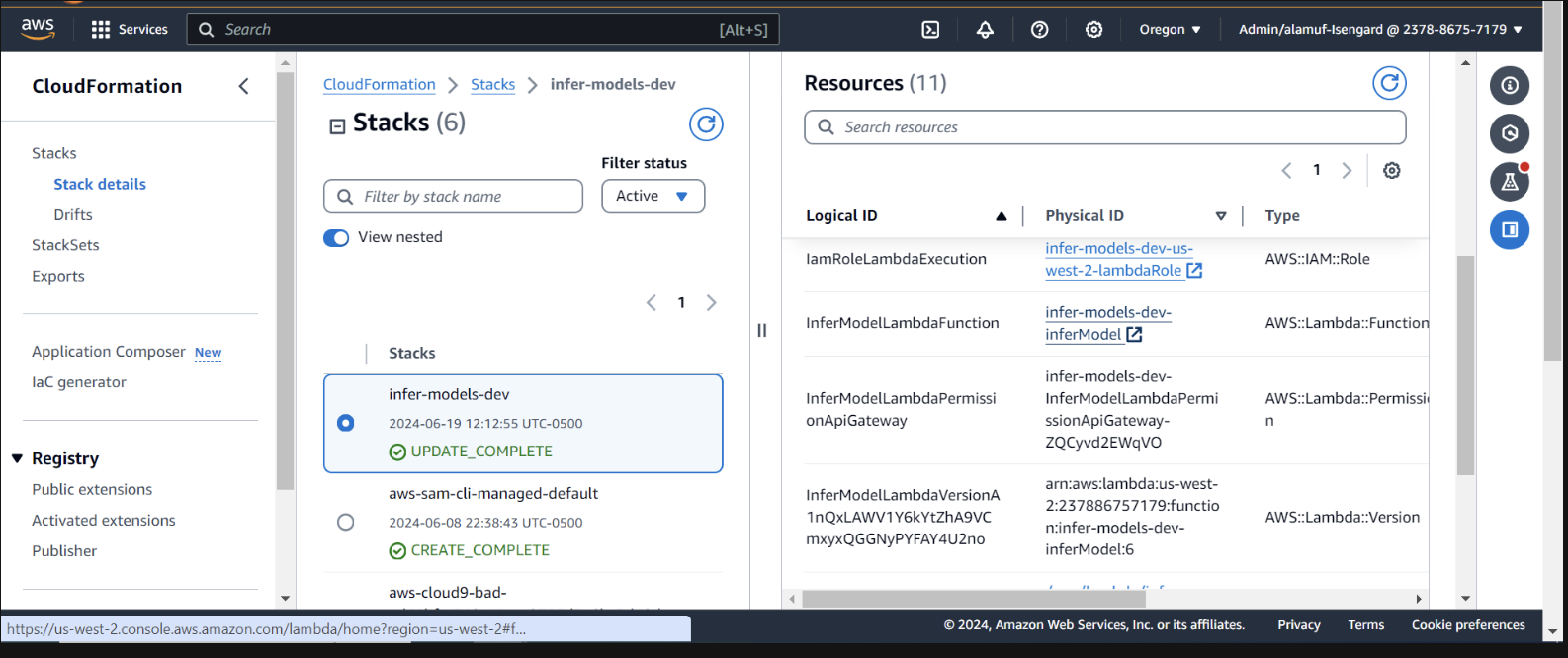
Precisamos fornecer permissões ao agente fundamental para invocar a função lambda. Abra a função lambda e role para baixo para selecionar a guia Configuração . À esquerda, selecione Permissões . Role para baixo até Declarações de políticas baseadas em recursos e selecione Adicionar permissões.
Selecione o serviço AWS no meio para sua declaração de política. Escolha Outro para o seu serviço e coloque agente de permissão para StatementID. Para o Diretor, coloque bedrock.amazonaws.com .
Insira arn:aws:bedrock:us-west-2:{aws-account-id}:agent/* . Observe que a AWS recomenda privilégios mínimos para que apenas o agente permitido possa invocar esta função Lambda. Um * no final do ARN concede a qualquer agente na conta acesso para invocar este Lambda. Idealmente, não usaríamos isso em um ambiente de produção. Por último, para a Ação, selecione lambda:InvokeFunction e depois Salvar. 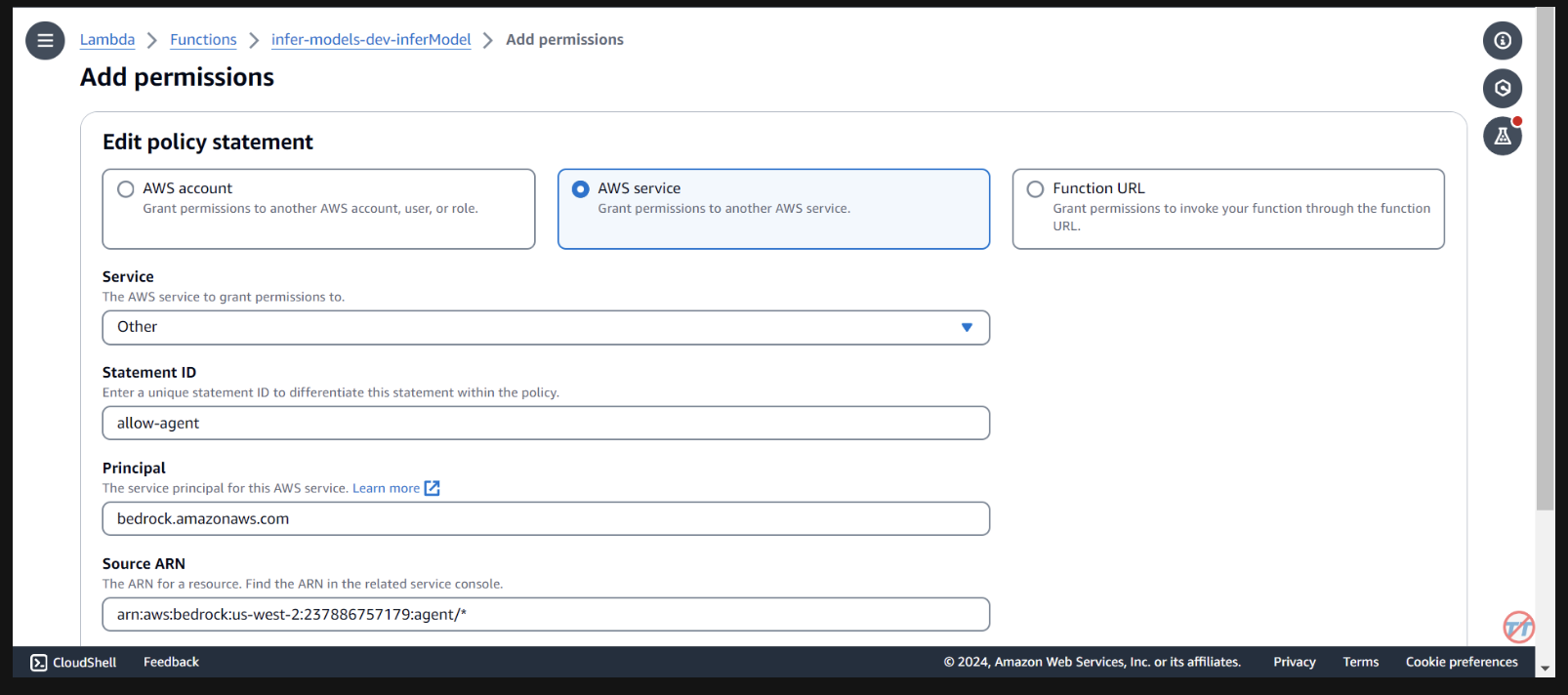
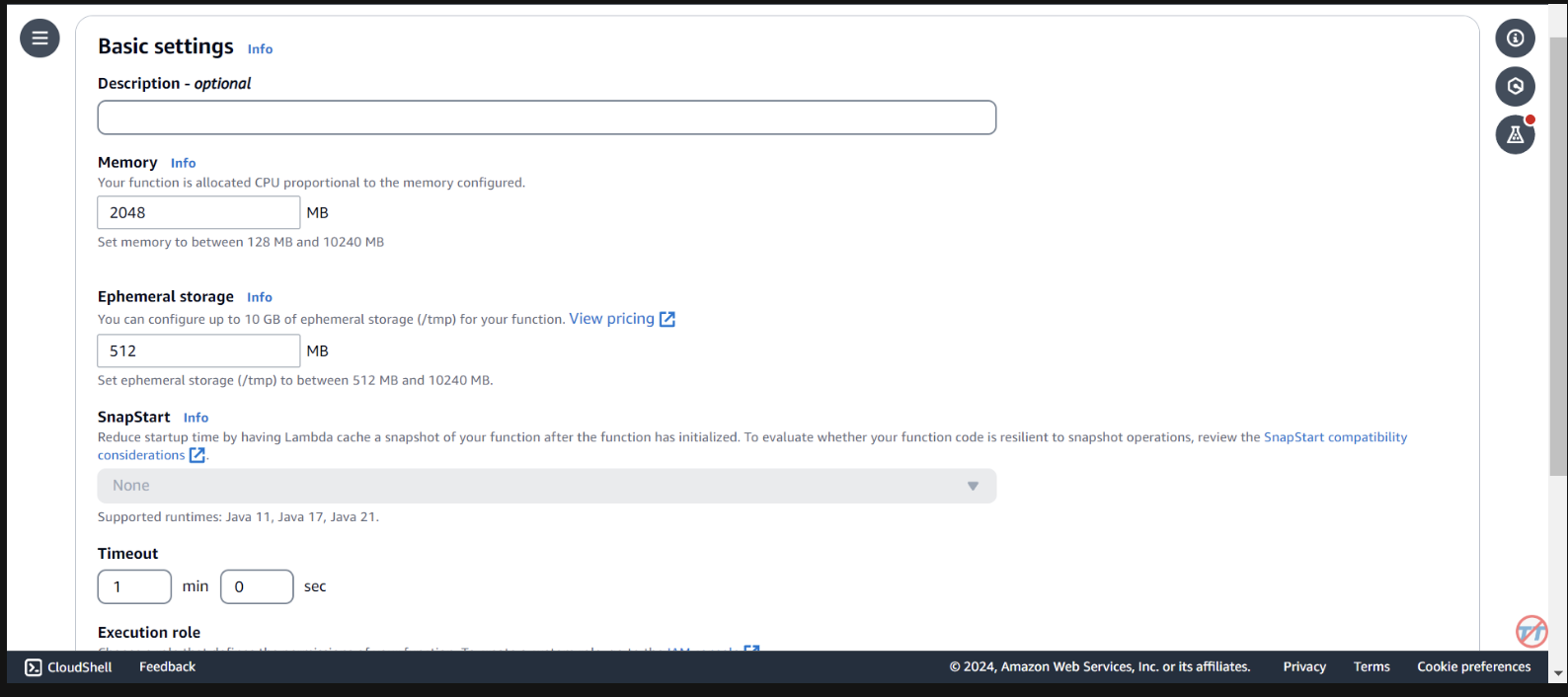
Para ajudar na inferência, aumentaremos a CPU/memória na função Lambda. Também aumentaremos o tempo limite para permitir que a função tenha tempo suficiente para concluir a invocação. Selecione Configuração geral à esquerda e Editar à direita.
Altere a memória para 2.048 MB e o tempo limite para 1 minuto . Role para baixo e selecione Salvar.
Agents . Forneça um nome de agente, como agente multimodelo e crie o agente. 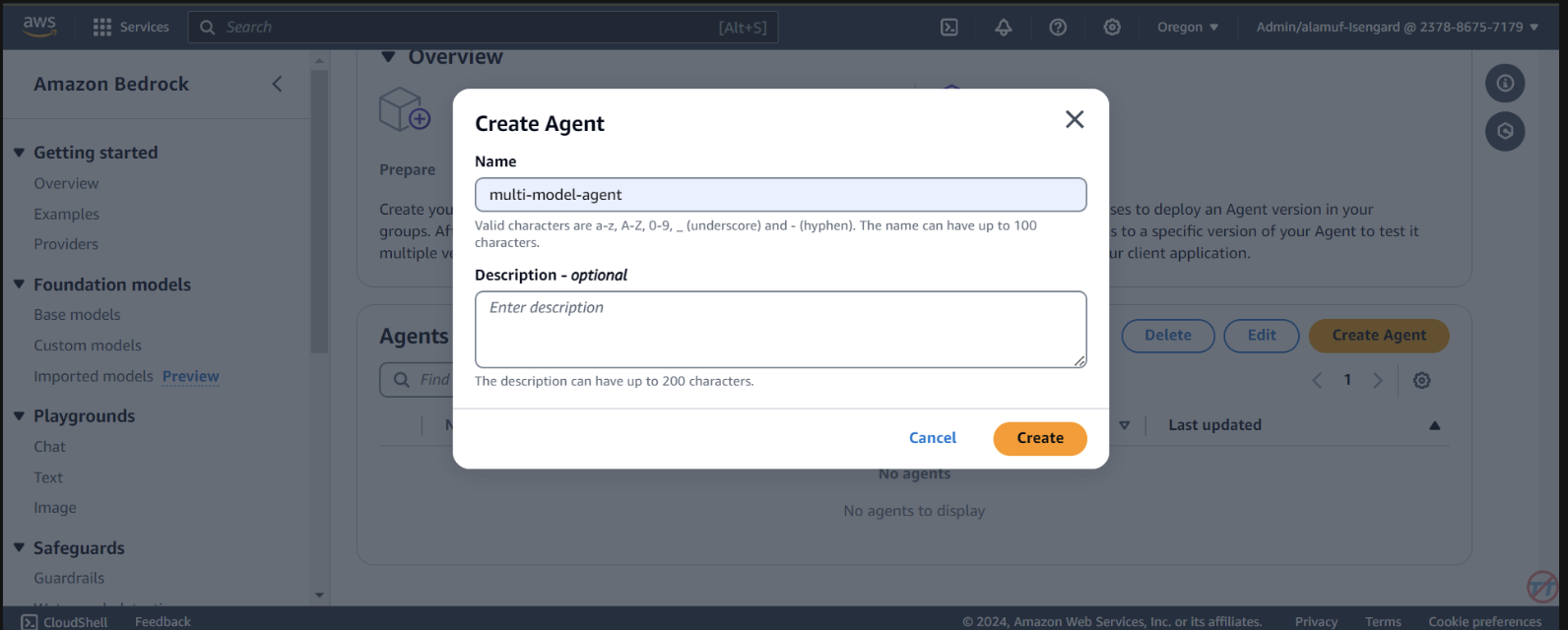
You are a research agent that interacts with various large language models. You pass the model ID and prompt from requests to large language models to create and store images. Then, the LLM will return a presigned URL to the image similar to the URL example provided. You also call LLMS for text and code generation, summarization, problem solving, text-to-sql, response comparisons and ratings. Remeber. you use other large language models for inference. Do not decide when to provide your own response, unless asked.
Depois, certifique-se de rolar até o topo e selecionar o botão Salvar antes de passar para a próxima etapa.
A seguir, adicionaremos um grupo de ação. Role para baixo até Action groups e selecione Adicionar . Chame o grupo de ação call-model .
Para o tipo de grupo de ação, escolha Definir com esquemas de API
Na próxima seção, selecionaremos uma função Lambda existente infer-models-dev-inferModel .
Para o esquema de API, escolheremos Define with in-line OpenAPI schema editor . Copie e cole o esquema abaixo no editor de esquema OpenAPI in-line e selecione Adicionar :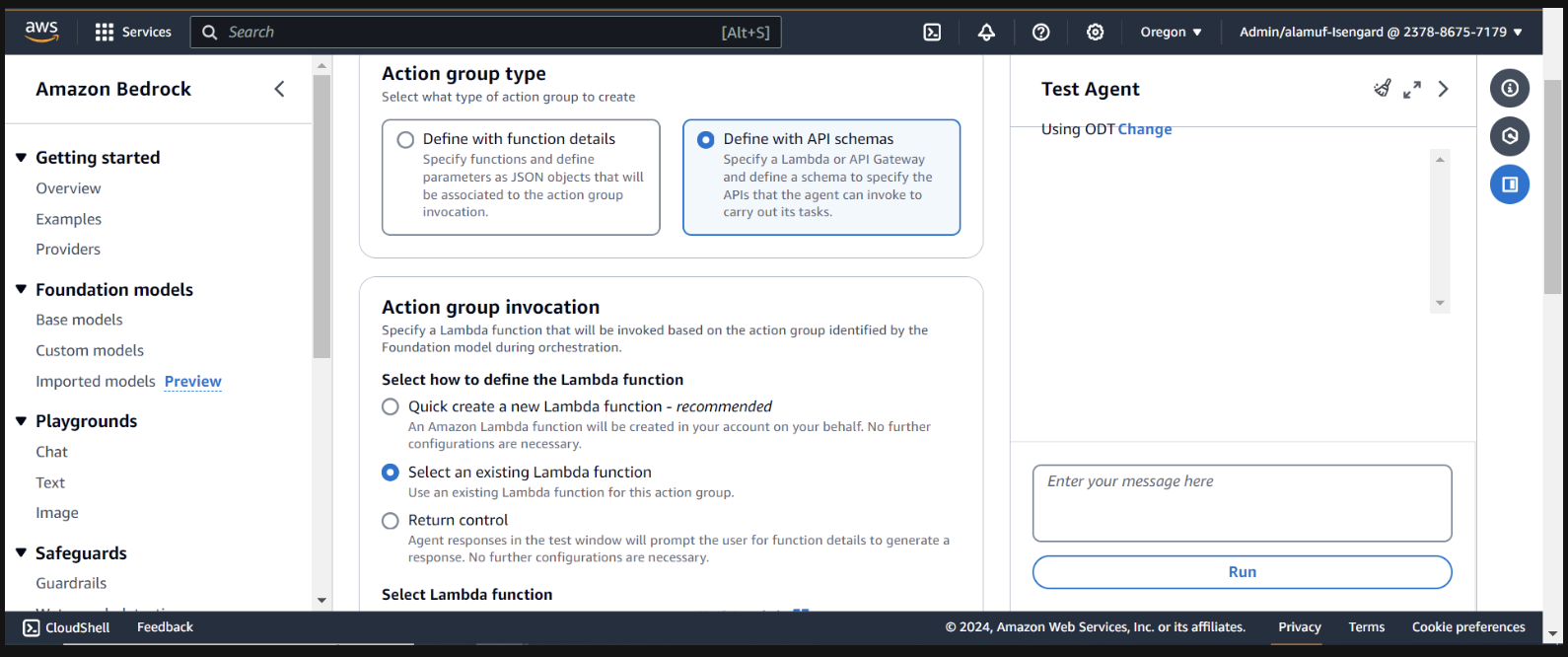
(This API schema is needed so that the bedrock agent knows the format structure and parameters required for the action group to interact with the Lambda function.)
{
"openapi": "3.0.0",
"info": {
"title": "Model Inference API",
"description": "API for inferring a model with a prompt, and model ID.",
"version": "1.0.0"
},
"paths": {
"/callModel": {
"post": {
"description": "Call a model with a prompt, model ID, and an optional image",
"parameters": [
{
"name": "modelId",
"in": "query",
"description": "The ID of the model to call",
"required": true,
"schema": {
"type": "string"
}
},
{
"name": "prompt",
"in": "query",
"description": "The prompt to provide to the model",
"required": true,
"schema": {
"type": "string"
}
}
],
"requestBody": {
"required": true,
"content": {
"multipart/form-data": {
"schema": {
"type": "object",
"properties": {
"modelId": {
"type": "string",
"description": "The ID of the model to call"
},
"prompt": {
"type": "string",
"description": "The prompt to provide to the model"
},
"image": {
"type": "string",
"format": "binary",
"description": "An optional image to provide to the model"
}
},
"required": ["modelId", "prompt"]
}
}
}
},
"responses": {
"200": {
"description": "Successful response",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"result": {
"type": "string",
"description": "The result of calling the model with the provided prompt and optional image"
}
}
}
}
}
}
}
}
}
}
}
Orchestration , habilite a opção Override orchestration template defaults . 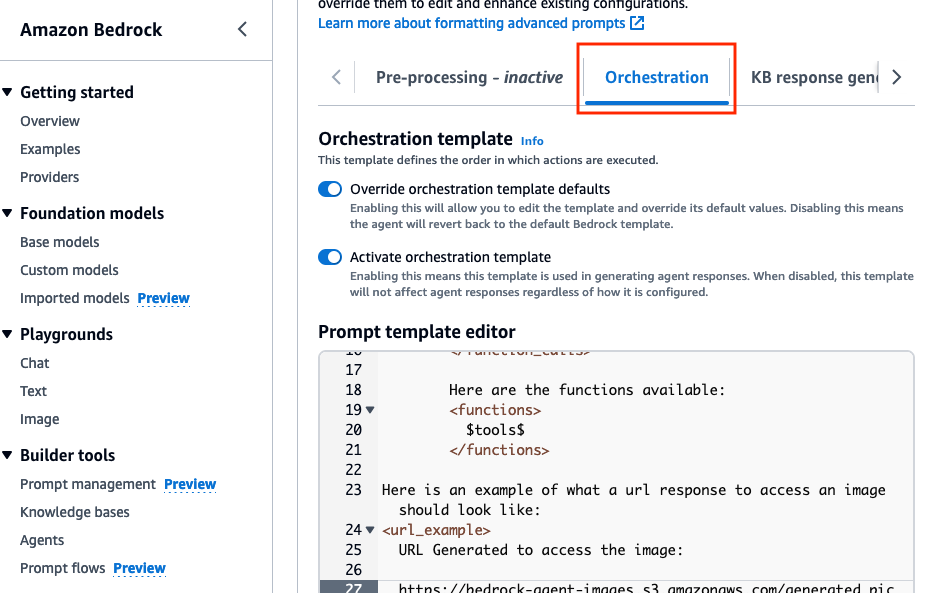
Here is an example of what a url response to access an image should look like:
<url_example>
URL Generated to access the image:
https://bedrock-agent-images.s3.amazonaws.com/generated_pic.png?AWSAccessKeyId=123xyz&Signature=rlF0gN%2BuaTHzuEDfELz8GOwJacA%3D&x-amz-security-token=IQoJb3JpZ2msqKr6cs7sTNRG145hKcxCUngJtRcQ%2FzsvDvt0QUSyl7xgp8yldZJu5Jg%3D%3D&Expires=1712628409
</url_example>
Esse prompt ajuda a fornecer ao agente um exemplo ao formatar a resposta de um URL pré-assinado após uma imagem ser gerada no bucket S3. Além disso, há uma opção de usar uma função Lambda de analisador personalizado para uma formatação mais granular.
Role até a parte inferior e selecione o botão Save and exit .
Depois, certifique-se de clicar no botão Save and exit novamente na parte superior e, em seguida, no botão Preparar na parte superior da interface do agente de teste à direita. Isso nos permitirá testar as alterações mais recentes.
(Antes de continuar, certifique-se de habilitar todos os modelos por meio do console Amazon Bedrock com os quais você planeja testar.)
Para iniciar o teste, prepare o agente encontrando o botão de preparação na página do construtor de agentes 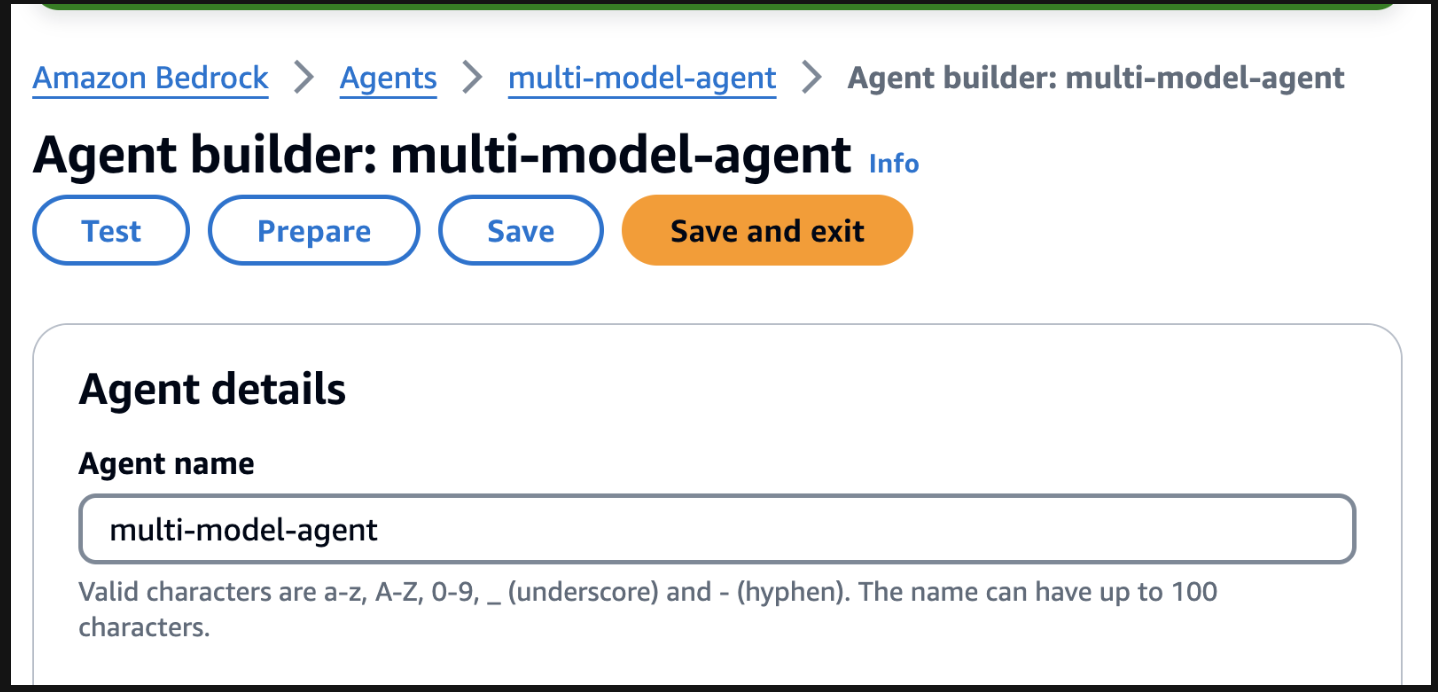
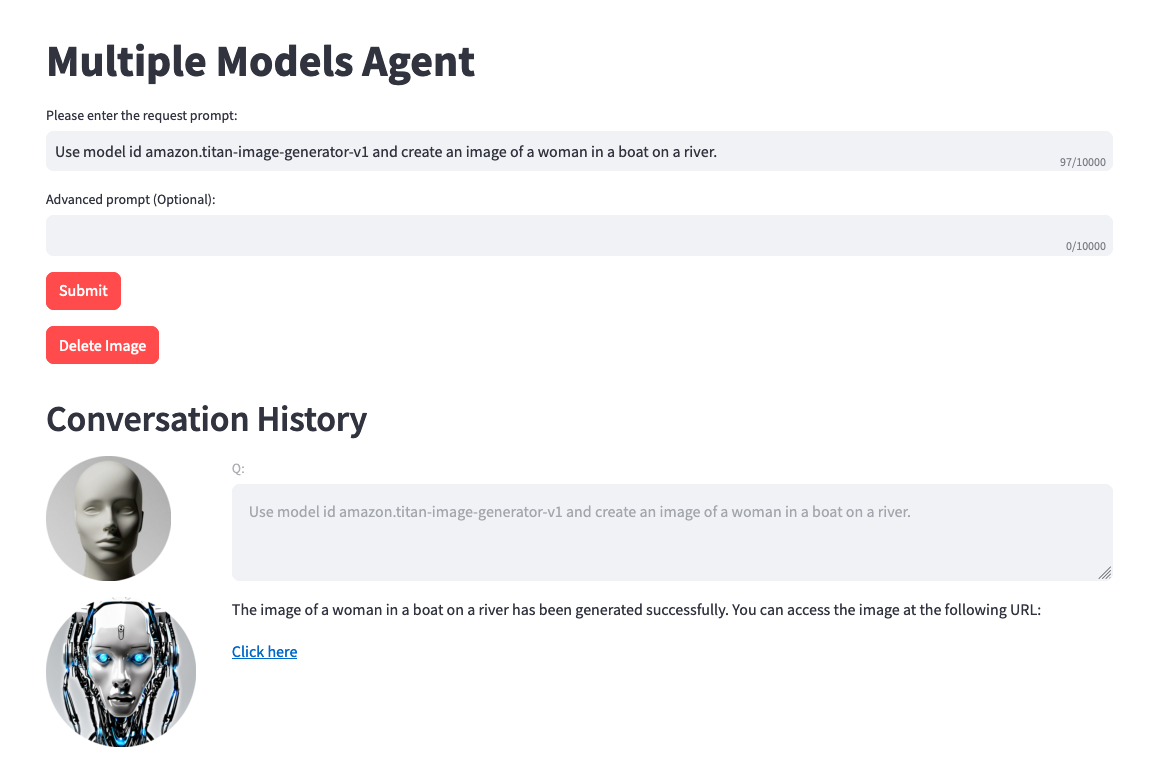
À direita, você verá uma opção para testar o agente com um campo de entrada do usuário. Abaixo estão alguns prompts que você pode testar. No entanto, é recomendável que você seja criativo e teste variações de prompts.
Uma coisa a observar antes do teste. Quando você converte texto para imagem ou imagem para texto, o código do projeto faz referência estaticamente ao mesmo arquivo .png. Em um ambiente ideal, esta etapa pode ser configurada para ser mais dinâmica.
Use model amazon.titan-image-generator-v1 and create me an image of a woman in a boat on a river.
Use model anthropic.claude-3-haiku-20240307-v1:0 and describe to me the image that is uploaded. The model function will have the information needed to provide a response. So, dont ask about the image.
Use model stability.stable-diffusion-xl-v1. Create an image of an astronaut riding a horse in the desert.
Use model meta.llama3-70b-instruct-v1:0. You are a gifted copywriter, with special expertise in writing Google ads. You are tasked to write a persuasive and personalized Google ad based on a company name and a short description. You need to write the Headline and the content of the Ad itself. For example: Company: Upwork Description: Freelancer marketplace Headline: Upwork: Hire The Best - Trust Your Job To True Experts Ad: Connect your business to Expert professionals & agencies with specialized talent. Post a job today to access Upwork's talent pool of quality professionals & agencies. Grow your team fast. 90% of customers rehire. Trusted by 5M+ businesses. Secure payments. - Write a persuasive and personalized Google ad for the following company. Company: Click Description: SEO services
(Se desejar ter uma configuração de UI com este projeto, vá para a etapa 6)
Você precisará ter um agent alias ID , juntamente com o agent ID para esta etapa. Vá para o console de gerenciamento Bedrock e selecione seu agente multimodelo. Copie o Agent ID no canto superior direito da seção Agent overview . Em seguida, role para baixo até Aliases e selecione Criar . Nomeie o alias como a1 e crie o agente. Salve o ID do alias gerado, NÃO o nome do alias. 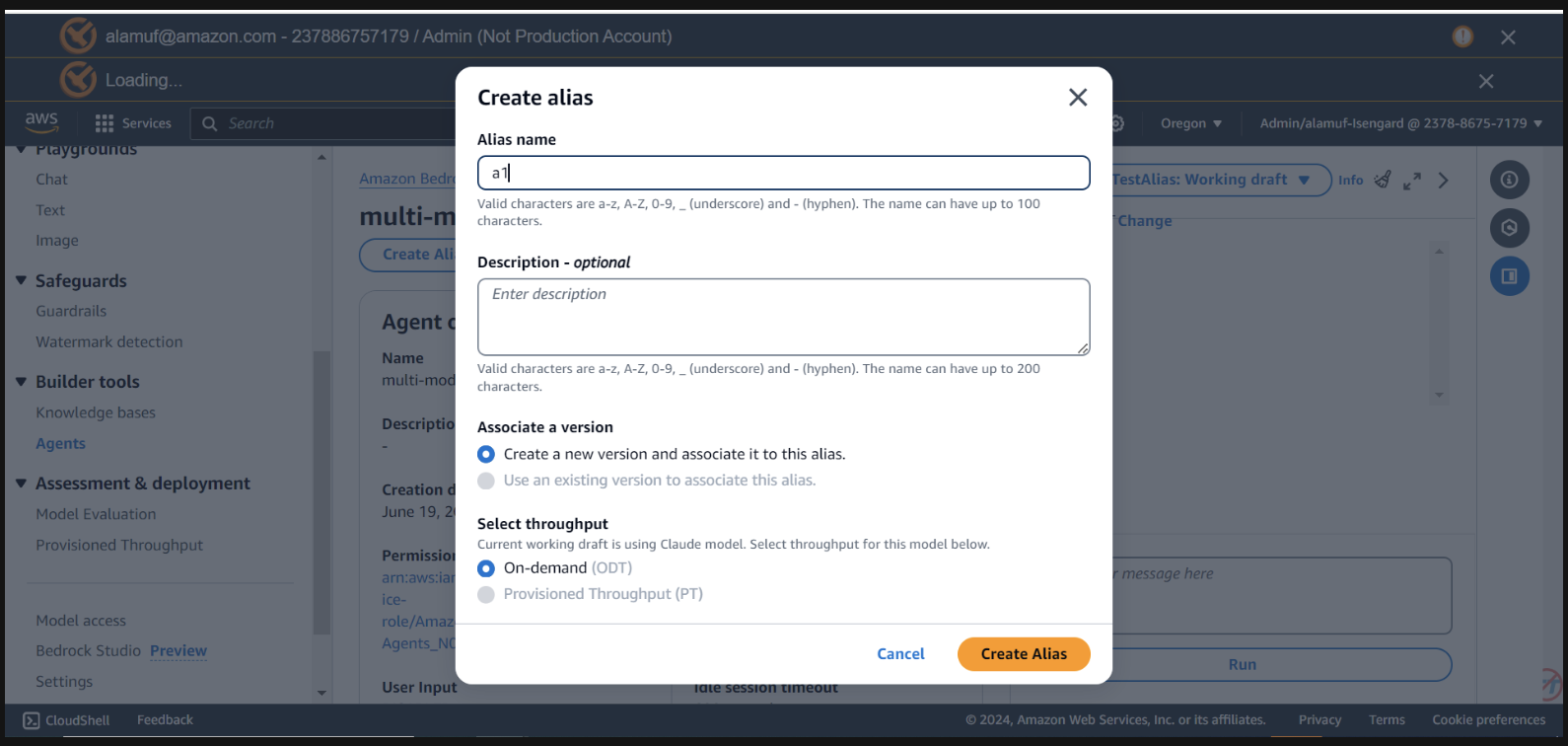
agora, navegue de volta para o IDE que você usou para abrir o projeto.
Navegue até o diretório streamlit_app :
Configuração de atualização :
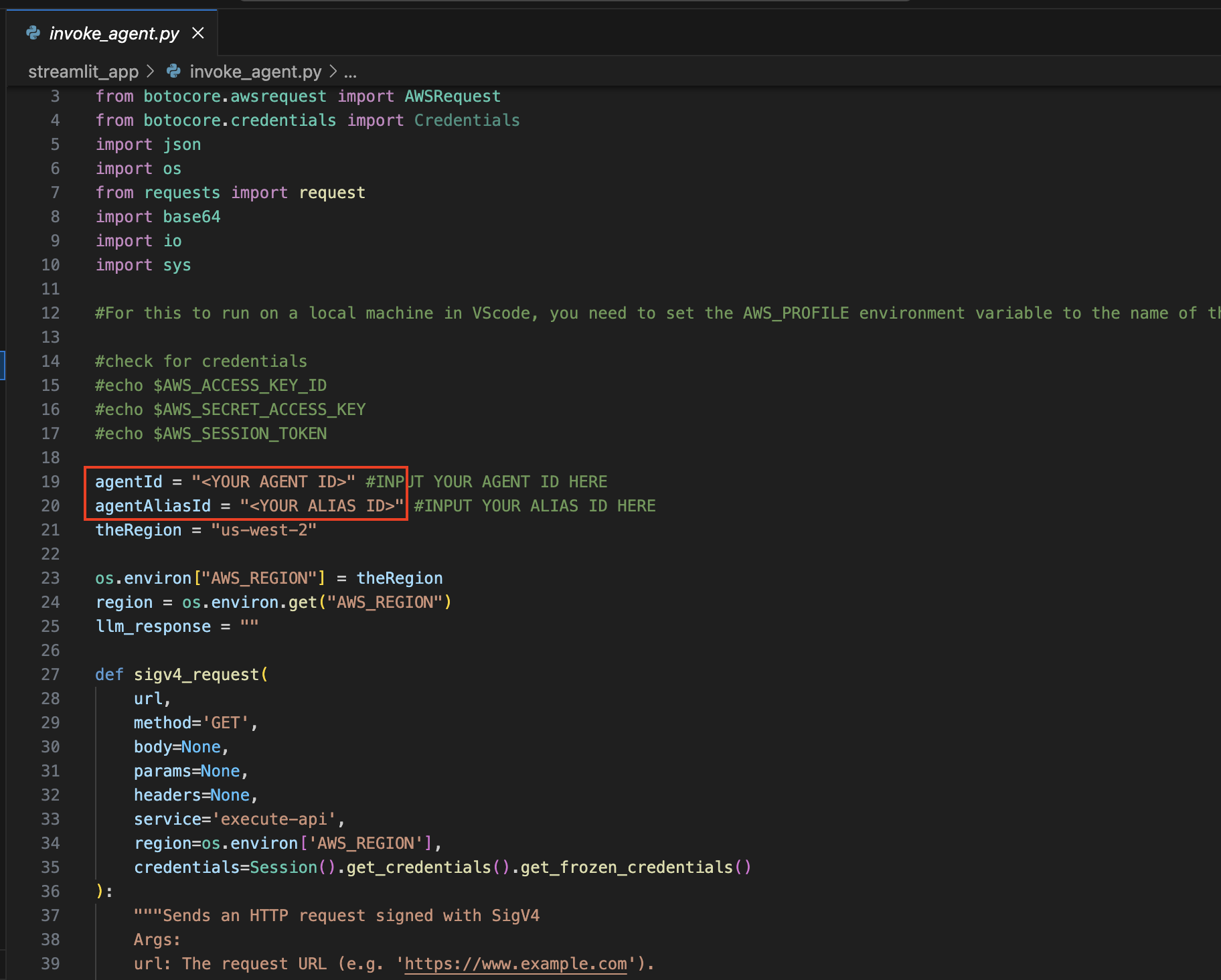
Abra o arquivo Invoke_agent.py .
Nas linhas 19 e 20, atualize as variáveis agentId e agentAliasId com os valores apropriados e salve-as.
Instale o Streamlit (se ainda não estiver instalado):
Execute o seguinte comando para instalar todas as dependências necessárias:
pip install streamlit boto3 pandasExecute o aplicativo Streamlit :
streamlit_app : streamlit run app.py
Lembre-se que você pode usar qualquer modelo disponível na Amazon Bedrock, e não está limitado à lista acima. Se um ID de modelo não estiver listado, consulte os modelos (IDs) disponíveis mais recentes na página de documentação do Amazon Bedrock aqui.
Você pode aproveitar o projeto fornecido para ajustar e comparar esta solução com seus próprios conjuntos de dados e casos de uso. Explore diferentes combinações de modelos, ultrapasse os limites do que é possível e impulsione a inovação no cenário em constante evolução da IA generativa.
Consulte CONTRIBUINDO para obter mais informações.
Esta biblioteca está licenciada sob a licença MIT-0. Veja o arquivo LICENÇA.


