QuillGPT
1.0.0

QuillGPT é uma implementação do bloco decodificador GPT baseado na arquitetura do artigo Attention is All You Need de Vaswani et. al. implementado em PyTorch. Além disso, este repositório contém dois modelos pré-treinados – Shakespearean GPT e Harpoon GPT – junto com seus pesos treinados. Para facilitar a experimentação e implantação, um Streamlit Playground é fornecido para exploração interativa desses modelos e um microsserviço FastAPI implementado com conteinerização Docker para implantação escalonável. Você também encontrará scripts Python para treinar novos modelos GPT e realizar inferências sobre eles, além de notebooks apresentando modelos treinados. Para facilitar a codificação e decodificação de texto, um tokenizer simples é implementado. Explore o QuillGPT para utilizar essas ferramentas e aprimorar seus projetos de processamento de linguagem natural!
Existem dois modelos e pesos pré-treinados incluídos neste repositório.
| Recurso | GPT shakespeariano | Arpão GPT |
|---|---|---|
| Parâmetros | 10,7 milhões | 226 milhões |
| Pesos | Pesos | Pesos |
| Configuração do modelo | Configuração | Configuração |
| Dados de treinamento | Texto de peças de Shakespeare (input.txt) | Texto aleatório de livros (corpus.txt) |
| Tipo de incorporação | Incorporações de personagens | Incorporações de personagens |
| Caderno de Treinamento | Caderno | Caderno |
| Hardware | NVIDIA T4 | NVIDIA A100 |
| Perda de treinamento e validação | 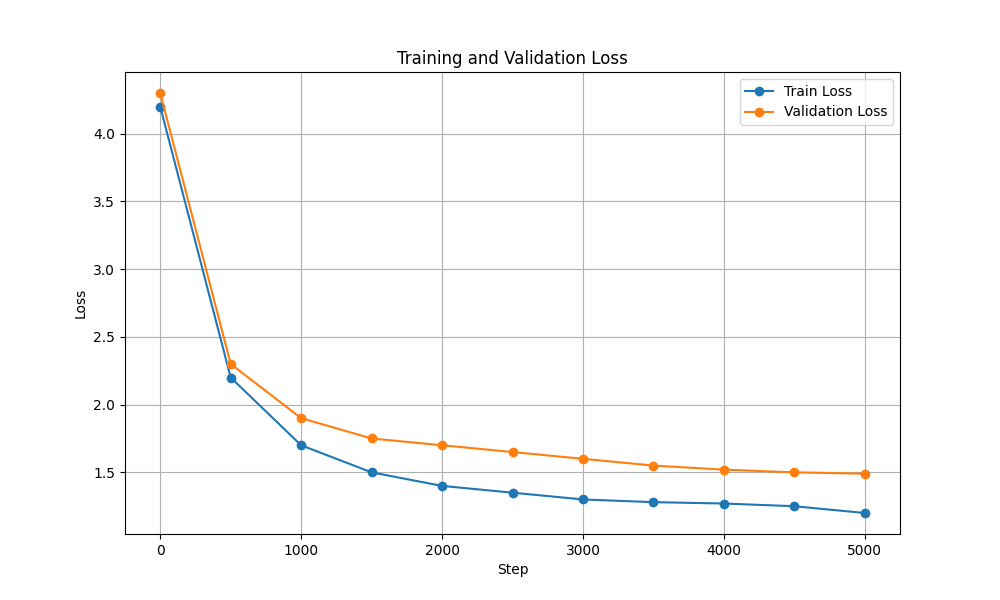 | 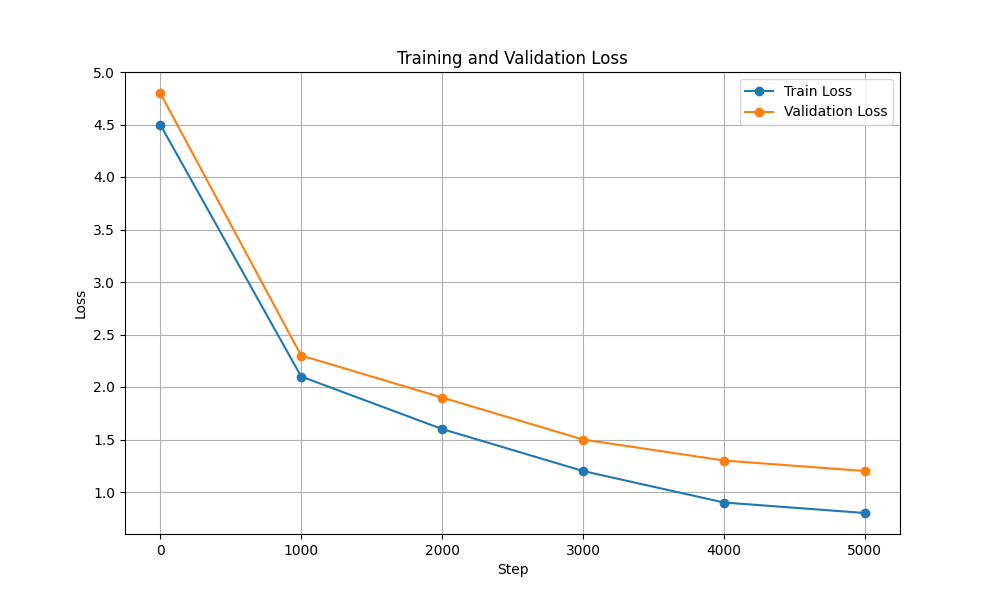 |
Para executar os scripts de treinamento e inferência, siga estas etapas:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtCertifique-se de baixar os pesos do Harpoon GPT aqui antes de continuar!
Ele está hospedado no Streamlit Cloud Service. Você pode visitá-lo através do link aqui.
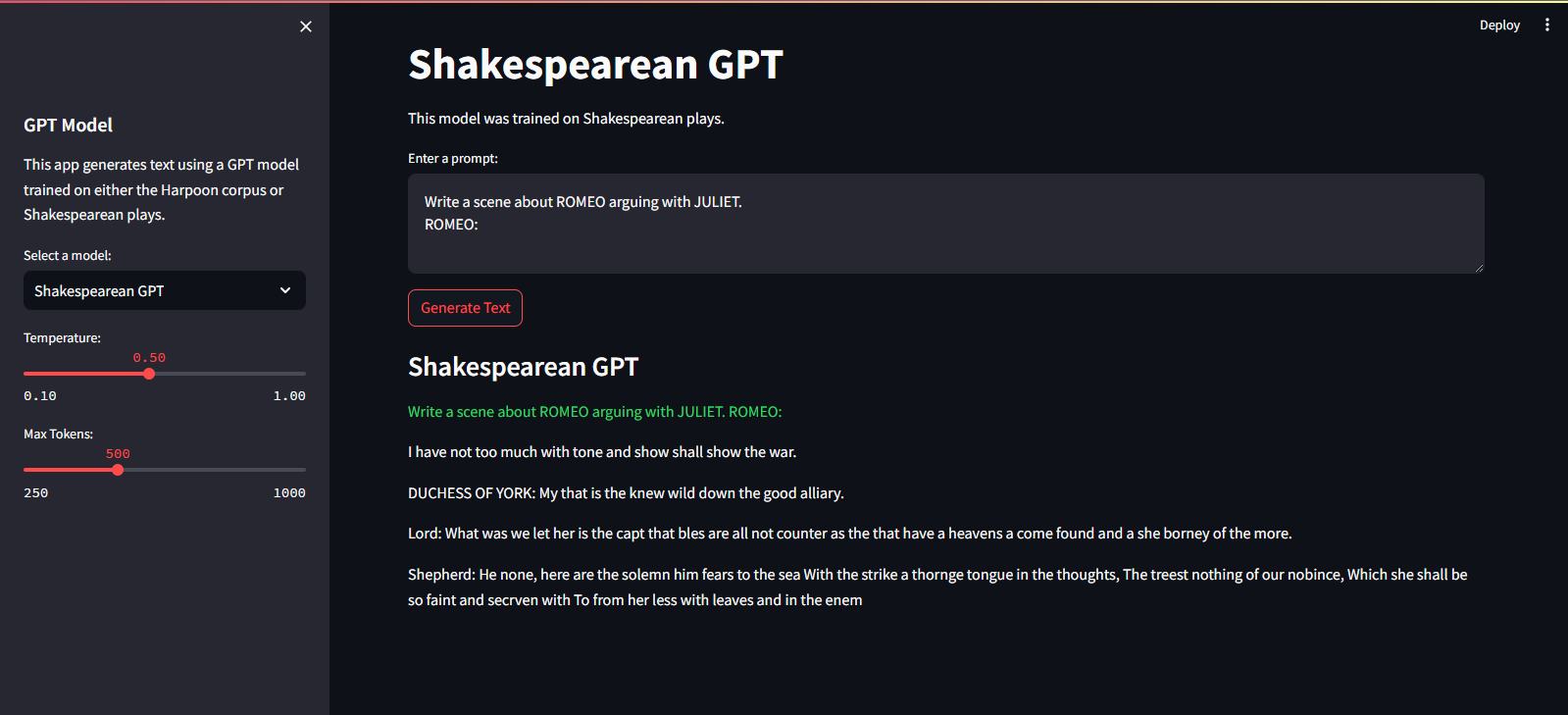
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devPara treinar o modelo GPT, siga estas etapas:
Prepare dados. Coloque todos os dados do texto em um único arquivo .txt e salve-o.
Escreva as configurações do transformador e salve o arquivo.
Por exemplo: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
Treinar modelo usando script scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (Você pode alterar config_path , data_path e output_dir conforme seus requisitos.)
output_dir especificado no comando.Após o treinamento, você pode usar o modelo GPT treinado para geração de texto. Aqui está um exemplo de uso do modelo treinado para inferência:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 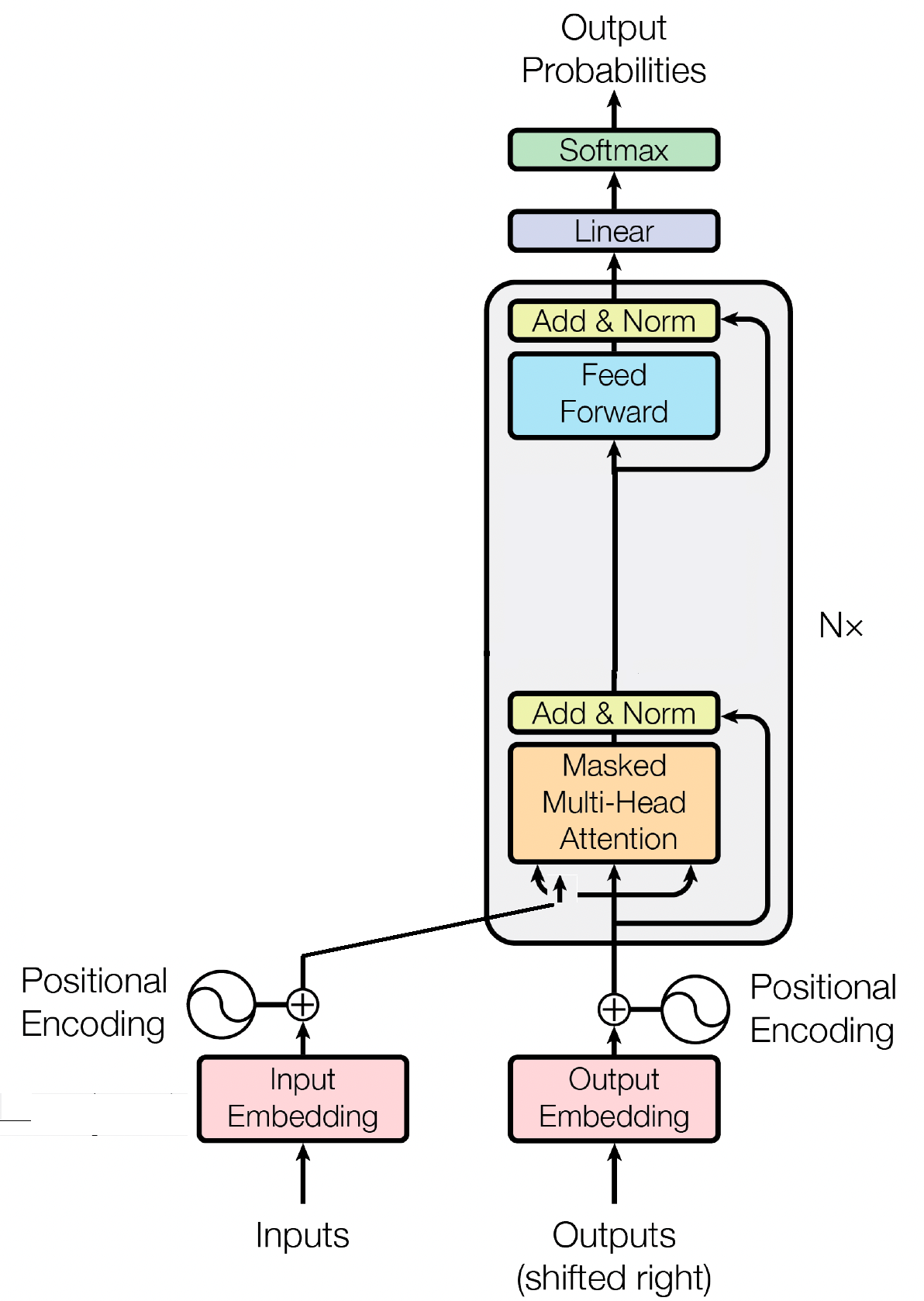
O bloco decodificador é um componente crucial do modelo GPT (Generative Pre-trained Transformer), é onde o GPT realmente gera o texto. Ele aproveita o mecanismo de autoatenção para processar sequências de entrada e gerar resultados coerentes. Cada bloco decodificador consiste em múltiplas camadas, incluindo camadas de autoatenção, redes neurais feed-forward e normalização de camadas. As camadas de autoatenção permitem que o modelo avalie a importância de diferentes palavras em uma sequência, capturando contexto e dependências independentemente de suas posições. Isso permite que o modelo GPT gere texto contextualmente relevante.
A incorporação de entrada desempenha um papel crucial em modelos baseados em transformadores como o GPT, transformando tokens de entrada em representações numéricas significativas. Esses embeddings servem como entrada inicial para o modelo, capturando informações semânticas sobre as palavras na sequência. O processo envolve mapear cada token na sequência de entrada para um espaço vetorial de alta dimensão, onde tokens semelhantes são posicionados mais próximos uns dos outros. Isso permite que o modelo compreenda as relações entre diferentes palavras e aprenda efetivamente com os dados de entrada. Os embeddings de entrada são então alimentados nas camadas subsequentes do modelo para processamento posterior.
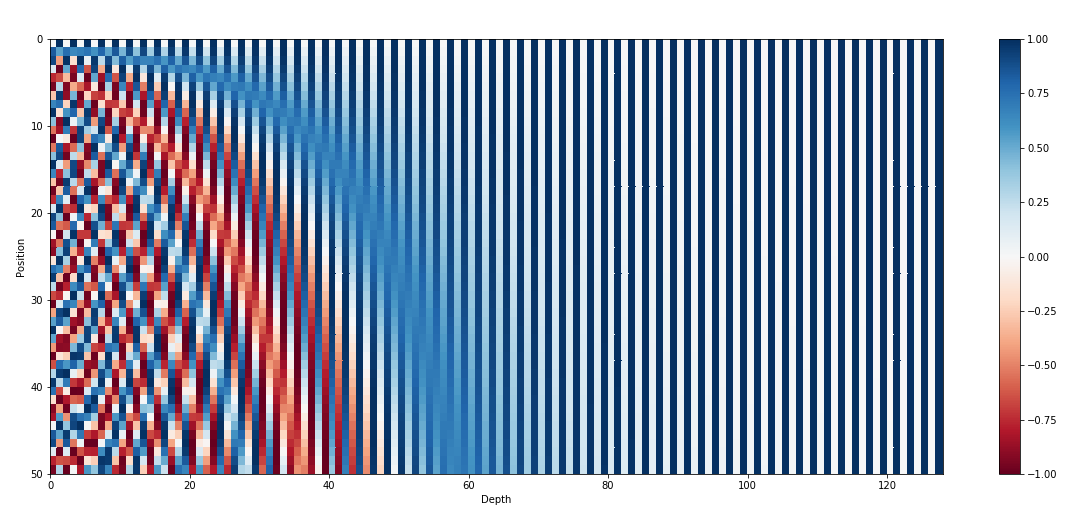
Além dos embeddings de entrada, os embeddings posicionais são outro componente vital das arquiteturas de transformadores como o GPT. Como os transformadores não possuem informações inerentes sobre a ordem dos tokens em uma sequência, incorporações posicionais são introduzidas para fornecer informações posicionais ao modelo. Esses embeddings codificam a posição de cada token dentro da sequência, permitindo ao modelo distinguir entre tokens com base em suas posições. Ao incorporar incorporações posicionais, transformadores como o GPT podem capturar com eficácia a natureza sequencial dos dados e gerar resultados coerentes que mantêm a ordem correta das palavras no texto gerado.

A autoatenção, um mecanismo fundamental em modelos baseados em transformadores como o GPT, opera atribuindo pontuações de importância a diferentes palavras em uma sequência. Este processo envolve três etapas principais: calcular pontuações de atenção, aplicar softmax para obter pesos de atenção e, finalmente, combinar esses pesos com os embeddings de entrada para gerar representações contextualmente informadas. Basicamente, a autoatenção permite que o modelo se concentre mais em palavras relevantes, ao mesmo tempo que retira a ênfase nas menos importantes, facilitando a aprendizagem eficaz das dependências contextuais nos dados de entrada. Este mecanismo é fundamental na captura de dependências de longo alcance e nuances contextuais, permitindo que modelos transformadores gerem longas sequências de texto.
MIT © Shrirang Mahajan
Sinta-se à vontade para enviar pull requests, criar problemas ou divulgar!
Apoie-me simplesmente marcando este repositório com estrela!


