marqo ecommerce embeddings
1.0.0
Neste trabalho, apresentamos dois modelos de incorporação de última geração para produtos de comércio eletrônico: Marqo-Ecommerce-B e Marqo-Ecommerce-L.
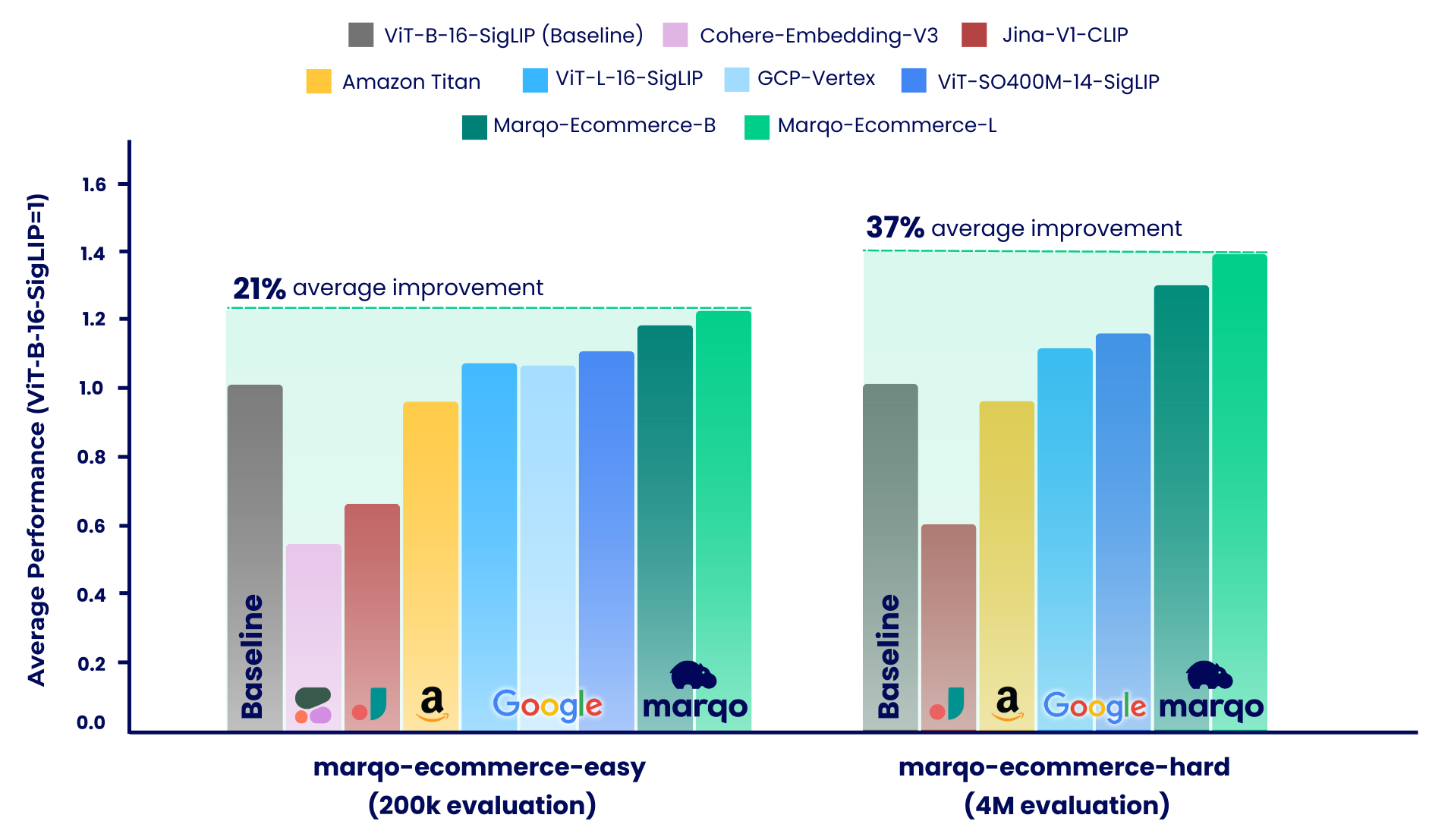
Os resultados do benchmarking mostram que os modelos Marqo-Ecommerce superaram consistentemente todos os outros modelos em várias métricas. Especificamente, marqo-ecommerce-L alcançou uma melhoria média de 17,6% no MRR e 20,5% no nDCG@10 quando comparado com o melhor modelo de código aberto atual, ViT-SO400M-14-SigLIP em todas as três tarefas no marqo-ecommerce-hard conjunto de dados marqo-ecommerce-hard . Quando comparado com o melhor modelo privado, Amazon-Titan-Multimodal , vimos uma melhoria média de 38,9% em MRR e 45,1% em nDCG@10 em todas as três tarefas, e 35,9% em Recall em todas as tarefas de texto para imagem em o conjunto de dados marqo-ecommerce-hard .
Mais resultados de benchmarking podem ser encontrados abaixo.
Conteúdo liberado :
| Modelo de incorporação | #Params (m) | Dimensão | Abraçando o rosto | Baixe .pt | Inferência de texto em lote único (A10g) | Inferência de imagem em lote único (A10g) |
|---|---|---|---|---|---|---|
| Marqo-Ecommerce-B | 203 | 768 | Marqo/marqo-ecommerce-embeddings-B | link | 5,1ms | 5,7ms |
| Marqo-Ecommerce-L | 652 | 1024 | Marqo/marqo-ecommerce-embeddings-L | link | 10,3ms | 11,0ms |
Para carregar os modelos no OpenCLIP, veja abaixo. Os modelos são hospedados no Hugging Face e carregados usando OpenCLIP. Você também pode encontrar esse código dentro de run_models.py .
pip install open_clip_torch
from PIL import Image
import open_clip
import requests
import torch
# Specify model from Hugging Face Hub
model_name = 'hf-hub:Marqo/marqo-ecommerce-embeddings-L'
model , preprocess_train , preprocess_val = open_clip . create_model_and_transforms ( model_name )
tokenizer = open_clip . get_tokenizer ( model_name )
# Preprocess the image and tokenize text inputs
# Load an example image from a URL
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw )
image = preprocess_val ( img ). unsqueeze ( 0 )
text = tokenizer ([ "dining chairs" , "a laptop" , "toothbrushes" ])
# Perform inference
with torch . no_grad (), torch . cuda . amp . autocast ():
image_features = model . encode_image ( image , normalize = True )
text_features = model . encode_text ( text , normalize = True )
# Calculate similarity probabilities
text_probs = ( 100.0 * image_features @ text_features . T ). softmax ( dim = - 1 )
# Display the label probabilities
print ( "Label probs:" , text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12]Para carregar os modelos em Transformers, veja abaixo. Os modelos são hospedados no Hugging Face e carregados usando Transformers.
from transformers import AutoModel , AutoProcessor
import torch
from PIL import Image
import requests
model_name = 'Marqo/marqo-ecommerce-embeddings-L'
# model_name = 'Marqo/marqo-ecommerce-embeddings-B'
model = AutoModel . from_pretrained ( model_name , trust_remote_code = True )
processor = AutoProcessor . from_pretrained ( model_name , trust_remote_code = True )
img = Image . open ( requests . get ( 'https://raw.githubusercontent.com/marqo-ai/marqo-ecommerce-embeddings/refs/heads/main/images/dining-chairs.png' , stream = True ). raw ). convert ( "RGB" )
image = [ img ]
text = [ "dining chairs" , "a laptop" , "toothbrushes" ]
processed = processor ( text = text , images = image , padding = 'max_length' , return_tensors = "pt" )
processor . image_processor . do_rescale = False
with torch . no_grad ():
image_features = model . get_image_features ( processed [ 'pixel_values' ], normalize = True )
text_features = model . get_text_features ( processed [ 'input_ids' ], normalize = True )
text_probs = ( 100 * image_features @ text_features . T ). softmax ( dim = - 1 )
print ( text_probs )
# [1.0000e+00, 8.3131e-12, 5.2173e-12] A Aprendizagem Contrastiva Generalizada (GCL) é usada para a avaliação. O código a seguir também pode ser encontrado em scripts .
git clone https://github.com/marqo-ai/GCL
Instale os pacotes exigidos pela GCL.
1. Recuperação de GoogleShopping-Text2Image.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-title2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
2. Recuperação de imagens do GoogleShopping-Category2Image.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/gs-cat2image
mkdir -p $outdir
hfdataset=Marqo/google-shopping-general-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['query']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
3. Recuperação AmazonProducts-Category2Image.
cd ./GCL
MODEL=hf-hub:Marqo/marqo-ecommerce-B
outdir=MarqoModels/GE/marqo-ecommerce-B/ap-title2image
mkdir -p $outdir
hfdataset=Marqo/amazon-products-eval
python evals/eval_hf_datasets_v1.py
--model_name $MODEL
--hf-dataset $hfdataset
--output-dir $outdir
--batch-size 1024
--num_workers 8
--left-key "['title']"
--right-key "['image']"
--img-or-txt "[['txt'], ['img']]"
--left-weight "[1]"
--right-weight "[1]"
--run-queries-cpu
--top-q 4000
--doc-id-key item_ID
--context-length "[[64], [0]]"
Nosso processo de benchmarking foi dividido em dois regimes distintos, cada um usando diferentes conjuntos de dados de listagens de produtos de comércio eletrônico: marqo-ecommerce-hard e marqo-ecommerce-easy. Ambos os conjuntos de dados continham imagens e texto de produtos e diferiam apenas em tamanho. O conjunto de dados "fácil" é aproximadamente 10-30 vezes menor (produtos 200k vs 4M) e projetado para acomodar modelos com taxa limitada, especificamente Cohere-Embeddings-v3 e GCP-Vertex (com limites de 0,66 rps e 2 rps respectivamente). O conjunto de dados “difícil” representa o verdadeiro desafio, pois contém quatro milhões de listagens de produtos de comércio eletrônico e é mais representativo dos cenários de pesquisa de comércio eletrônico do mundo real.
Em ambos os cenários, os modelos foram comparados com três tarefas diferentes:
Marqo-Ecommerce-Hard analisa a avaliação abrangente conduzida usando o conjunto completo de 4 milhões de dados, destacando o desempenho robusto de nossos modelos em um contexto do mundo real.
Recuperação de GoogleShopping-Text2Image.
| Modelo de incorporação | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,682 | 0,878 | 0,683 | 0,726 |
| Marqo-Ecommerce-B | 0,623 | 0,832 | 0,624 | 0,668 |
| ViT-SO400M-14-SigLip | 0,573 | 0,763 | 0,574 | 0,613 |
| ViT-L-16-SigLip | 0,540 | 0,722 | 0,540 | 0,577 |
| ViT-B-16-SigLip | 0,476 | 0,660 | 0,477 | 0,513 |
| Amazon-Titan-MultiModal | 0,475 | 0,648 | 0,475 | 0,509 |
| Jina-V1-CLIP | 0,285 | 0,402 | 0,285 | 0,306 |
Recuperação de imagens do GoogleShopping-Category2.
| Modelo de incorporação | mapa | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,463 | 0,652 | 0,822 | 0,666 |
| Marqo-Ecommerce-B | 0,423 | 0,629 | 0,810 | 0,644 |
| ViT-SO400M-14-SigLip | 0,352 | 0,516 | 0,707 | 0,529 |
| ViT-L-16-SigLip | 0,324 | 0,497 | 0,687 | 0,509 |
| ViT-B-16-SigLip | 0,277 | 0,458 | 0,660 | 0,473 |
| Amazon-Titan-MultiModal | 0,246 | 0,429 | 0,642 | 0,446 |
| Jina-V1-CLIP | 0,123 | 0,275 | 0,504 | 0,294 |
Recuperação AmazonProducts-Text2Image.
| Modelo de incorporação | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,658 | 0,854 | 0,663 | 0,703 |
| Marqo-Ecommerce-B | 0,592 | 0,795 | 0,597 | 0,637 |
| ViT-SO400M-14-SigLip | 0,560 | 0,742 | 0,564 | 0,599 |
| ViT-L-16-SigLip | 0,544 | 0,715 | 0,548 | 0,580 |
| ViT-B-16-SigLip | 0,480 | 0,650 | 0,484 | 0,515 |
| Amazon-Titan-MultiModal | 0,456 | 0,627 | 0,457 | 0,491 |
| Jina-V1-CLIP | 0,265 | 0,378 | 0,266 | 0,285 |
Conforme mencionado, nosso processo de benchmarking foi dividido em dois cenários distintos: marqo-ecommerce-hard e marqo-ecommerce-easy. Esta seção cobre o último, que apresenta um corpus 10 a 30 vezes menor e foi projetado para acomodar modelos com taxa limitada. Analisaremos a avaliação abrangente conduzida usando todos os 200 mil produtos nos dois conjuntos de dados. Além dos modelos já avaliados acima, esses benchmarks também incluem Cohere-embedding-v3 e GCP-Vertex.
Recuperação de GoogleShopping-Text2Image.
| Modelo de incorporação | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,879 | 0,971 | 0,879 | 0,901 |
| Marqo-Ecommerce-B | 0,842 | 0,961 | 0,842 | 0,871 |
| ViT-SO400M-14-SigLip | 0,792 | 0,935 | 0,792 | 0,825 |
| GCP-Vértice | 0,740 | 0,910 | 0,740 | 0,779 |
| ViT-L-16-SigLip | 0,754 | 0,907 | 0,754 | 0,789 |
| ViT-B-16-SigLip | 0,701 | 0,870 | 0,701 | 0,739 |
| Amazon-Titan-MultiModal | 0,694 | 0,868 | 0,693 | 0,733 |
| Jina-V1-CLIP | 0,480 | 0,638 | 0,480 | 0,511 |
| Cohere-incorporação-v3 | 0,358 | 0,515 | 0,358 | 0,389 |
Recuperação de imagens do GoogleShopping-Category2.
| Modelo de incorporação | mapa | P@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,515 | 0,358 | 0,764 | 0,590 |
| Marqo-Ecommerce-B | 0,479 | 0,336 | 0,744 | 0,558 |
| ViT-SO400M-14-SigLip | 0,423 | 0,302 | 0,644 | 0,487 |
| GCP-Vértice | 0,417 | 0,298 | 0,636 | 0,481 |
| ViT-L-16-SigLip | 0,392 | 0,281 | 0,627 | 0,458 |
| ViT-B-16-SigLip | 0,347 | 0,252 | 0,594 | 0,414 |
| Amazon-Titan-MultiModal | 0,308 | 0,231 | 0,558 | 0,377 |
| Jina-V1-CLIP | 0,175 | 0,122 | 0,369 | 0,229 |
| Cohere-incorporação-v3 | 0,136 | 0,110 | 0,315 | 0,178 |
Recuperação AmazonProducts-Text2Image.
| Modelo de incorporação | mapa | R@10 | MRR | nDCG@10 |
|---|---|---|---|---|
| Marqo-Ecommerce-L | 0,92 | 0,978 | 0,928 | 0,940 |
| Marqo-Ecommerce-B | 0,897 | 0,967 | 0,897 | 0,914 |
| ViT-SO400M-14-SigLip | 0,860 | 0,954 | 0,860 | 0,882 |
| ViT-L-16-SigLip | 0,842 | 0,940 | 0,842 | 0,865 |
| GCP-Vértice | 0,808 | 0,933 | 0,808 | 0,837 |
| ViT-B-16-SigLip | 0,797 | 0,917 | 0,797 | 0,825 |
| Amazon-Titan-MultiModal | 0,762 | 0,889 | 0,763 | 0,791 |
| Jina-V1-CLIP | 0,530 | 0,699 | 0,530 | 0,565 |
| Cohere-incorporação-v3 | 0,433 | 0,597 | 0,433 | 0,465 |
@software{zhu2024marqoecommembed_2024,
author = {Tianyu Zhu and and Jesse Clark},
month = oct,
title = {{Marqo Ecommerce Embeddings - Foundation Model for Product Embeddings}},
url = {https://github.com/marqo-ai/marqo-ecommerce-embeddings/},
version = {1.0.0},
year = {2024}
}


