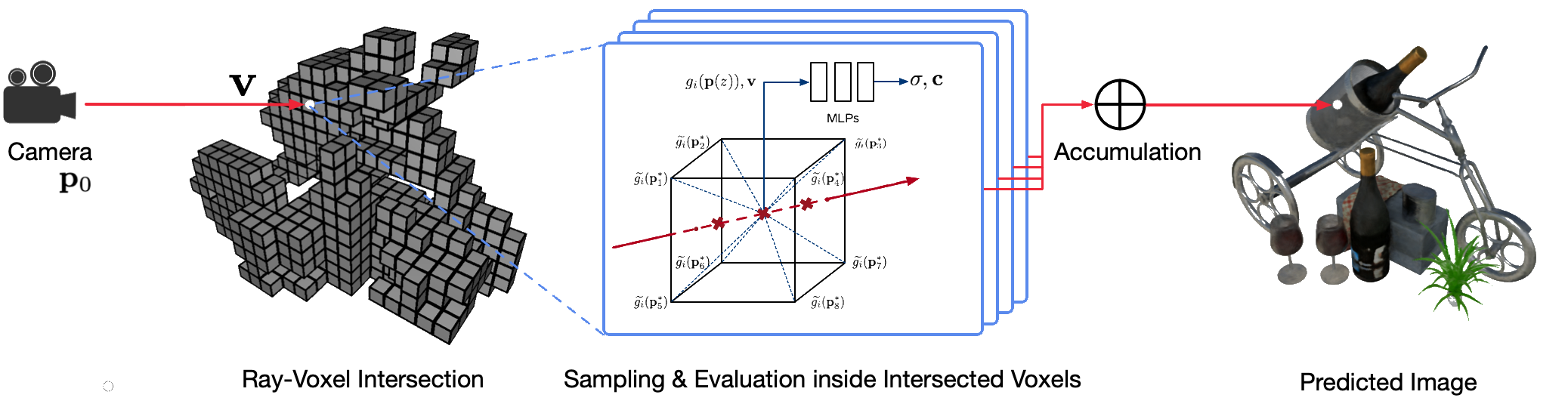
A renderização fotorrealística de pontos de vista livres de cenas do mundo real usando técnicas clássicas de computação gráfica é um problema desafiador porque requer a difícil etapa de capturar modelos detalhados de aparência e geometria. A renderização neural é um campo emergente que emprega redes neurais profundas para aprender implicitamente representações de cena que encapsulam geometria e aparência a partir de observações 2D com ou sem geometria grosseira. No entanto, as abordagens existentes neste campo muitas vezes mostram renderizações borradas ou sofrem de processos de renderização lentos. Propomos Neural Sparse Voxel Fields (NSVF), uma nova representação de cena neural para renderização de ponto de vista livre rápida e de alta qualidade.
Aqui está o repositório oficial do artigo:
Também fornecemos nossa implementação não oficial para:
Este código é implementado em PyTorch usando a estrutura fairseq.
O código foi testado no seguinte sistema:
Somente aprendizado e renderização em GPUs são suportados.
Para instalar, primeiro clone este repositório e instale todas as dependências:
pip install -r requirements.txtEntão, corra
pip install --editable ./Ou se quiser instalar o código localmente, execute:
python setup.py build_ext --inplaceVocê pode baixar os conjuntos de dados sintéticos e reais pré-processados usados em nosso artigo. Por favor, cite também os artigos originais se você usar algum deles em seu trabalho.
| Conjunto de dados | Link para baixar | Notas sobre a divisão do conjunto de dados |
|---|---|---|
| Sintético-NSVF | baixar (.zip) | 0_* (treinamento) 1_* (validação) 2_* (teste) |
| Sintético-NeRF | baixar (.zip) | 0_* (treinamento) 1_* (validação) 2_* (teste) |
| MisturadoMVS | baixar (.zip) | 0_* (treinamento) 1_* (teste) |
| Tanques e Templos | baixar (.zip) | 0_* (treinamento) 1_* (teste) |
Para preparar um novo conjunto de dados de uma única cena para treinamento e teste, siga a estrutura de dados:
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4) onde o arquivo bbox.txt contém uma linha que descreve a caixa delimitadora inicial e o tamanho do voxel:
x_min y_min z_min x_max y_max z_max initial_voxel_size Observe que os nomes dos arquivos das imagens alvo e os dos arquivos de pose da câmera correspondentes não precisam ser exatamente iguais. No entanto, as ordens destes dois tipos de arquivos (classificados por string) devem corresponder. Os conjuntos de dados são divididos com índices de visualização. Por exemplo, " train (0..100) , valid (100..200) e test (200..400) " significa as primeiras 100 visualizações para treinamento, 100-199 visualizações para validação e 200-399 visualizações para teste .
Dado o conjunto de dados de uma única cena ( {DATASET} ), usamos o seguinte comando para treinar um modelo NSVF para sintetizar novas visualizações em 800x800 pixels, com tamanho de lote de 4 imagens por GPU e 2048 raios por imagem. Por padrão, o código detectará automaticamente todas as GPUs disponíveis.
No exemplo a seguir, usamos uma arquitetura pré-definida nsvf_base com argumentos específicos:
--no-sampling-at-reader , o modelo apenas amostra pixels na região da imagem projetada de voxels esparsos para treinamento.1/8 (0.125) do tamanho do voxel, que normalmente é descrito no arquivo bbox.txt .--use-octree . Ele construirá uma octree de voxel esparsa para acelerar a interseção raio-voxel, especialmente quando o número de voxels for maior que 10000 .--pruning-every-steps como 2500 , o modelo executa a auto-reparação a cada 2500 etapas.--half-voxel-size-at e --reduce-step-size-at como 5000,25000,75000 , o tamanho do voxel e o tamanho do passo são reduzidos pela metade em 5k , 25k e 75k , respectivamente.Observe que, embora as configurações de parâmetros acima sejam usadas para a maioria dos experimentos no artigo, é possível ajustar esses parâmetros para obter melhor qualidade. Além dos parâmetros acima, outros parâmetros também podem usar configurações padrão.
Além da arquitetura nsvf_base , você pode verificar outras arquiteturas ou definir suas próprias arquiteturas no arquivo fairnr/models/nsvf.py .
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log Os pontos de verificação são salvos em {SAVE} . Você pode iniciar o tensorboard para verificar o progresso do treinamento:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000Existem mais exemplos de scripts de treinamento para reproduzir os resultados do nosso artigo nos exemplos.
Depois que o modelo é treinado, o comando a seguir é usado para avaliar a qualidade da renderização nas visualizações de teste fornecidas em {MODEL_PATH} .
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' Observe que substituímos raymarching_tolerance por 0.01 para permitir o encerramento antecipado para acelerar a renderização.
A renderização de ponto de vista livre pode ser alcançada quando um modelo é treinado e uma trajetória de renderização é especificada. Por exemplo, o comando a seguir é para renderizar com uma trajetória circular (velocidade angular 3 graus/quadro, 15 quadros por GPU). Isso gera imagens renderizadas por visualização e mescla as imagens em um vídeo .mp4 em ${SAVE}/output da seguinte maneira:

Por padrão, o código pode detectar todas as GPUs disponíveis.
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " Nosso código também oferece suporte à renderização para determinadas poses de câmera. Por exemplo, o comando a seguir é para renderizar com as poses de câmera definidas nos arquivos 200-399 na pasta ${DATASET}/pose :
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " O código também suporta renderização com poses de câmera definidas em um arquivo .txt . Consulte este exemplo.
Também oferecemos suporte à execução de cubos de marcha para extrair as iso-superfícies como malhas triangulares de um modelo NSVF treinado e salvo como {SAVE}/{NAME}.ply .
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 Também é possível exportar os voxels esparsos aprendidos configurando --format 'voxel_mesh' . O arquivo .ply de saída pode ser aberto com qualquer visualizador 3D, como o MeshLab.

NSVF é licenciado pelo MIT. A licença também se aplica aos modelos pré-treinados.
Por favor cite como
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

