Ao explorar a criptografia, encontrei um vídeo da Khan Academy que despertou meu interesse nas falhas da infame cifra de César.
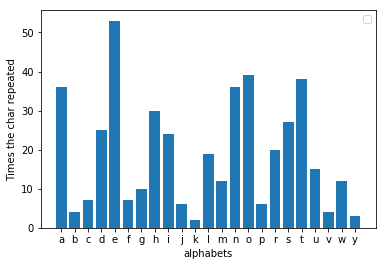
Sempre que você escreve uma carta longa ou um e-mail em inglês, você involuntariamente deixa uma impressão digital; se você examinar uma mensagem que escreveu e contar a frequência de cada letra, encontrará um padrão bastante consistente. 'e' provavelmente será a letra mais recorrente em toda a mensagem. Peguei uma fábula aleatória da internet para testar e o resultado que obtive foi o que se esperava dela. 'e' era de fato a letra mais popular. Este fato é válido para qualquer mensagem que seja longa o suficiente.
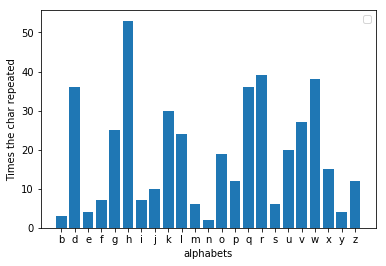
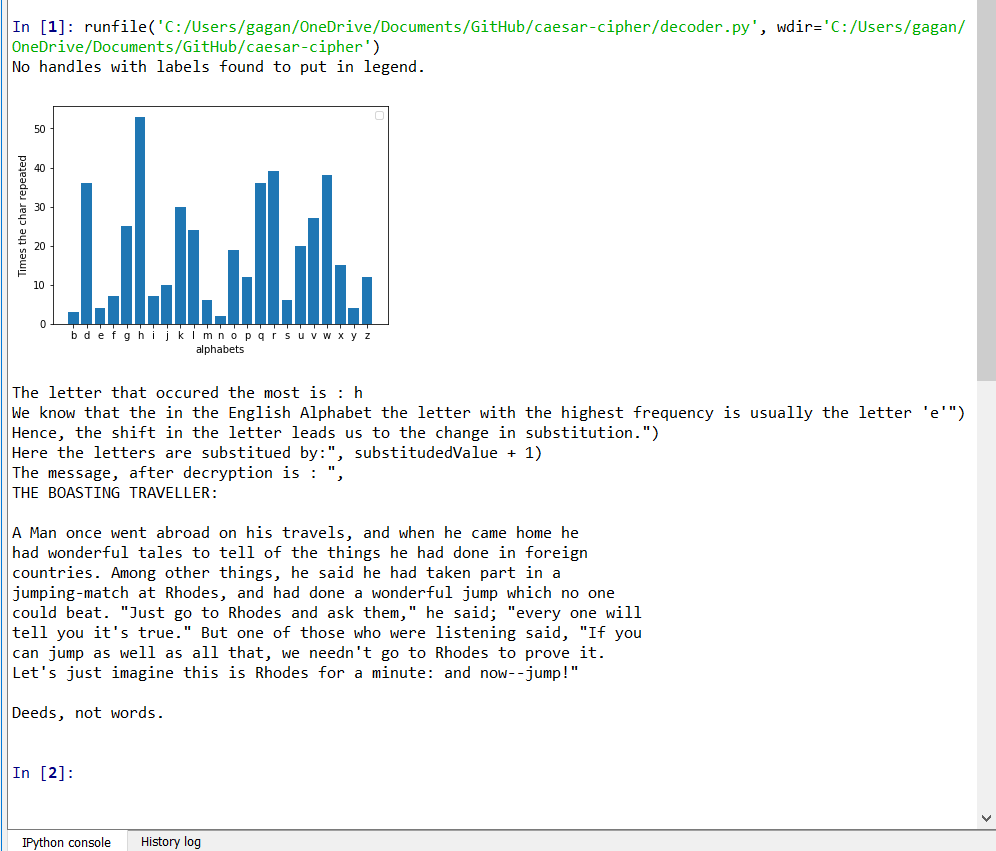
A falha que Al-kindi encontrou foi que, quando você analisa a frequência da mensagem criptografada, agora uma letra diferente é a que mais se repete. Se você verificar o quanto a letra foi deslocada de três, poderá encontrar o valor pelo qual a mensagem foi substituída. Por exemplo, se 'h' for a letra mais popular na mensagem criptografada, então a mudança provavelmente foi três. Agora, invertendo a mudança, poderíamos receber facilmente a mensagem original. No decoder.py quando você alimenta um arquivo criptografado, ele descriptografa a mensagem e a imprime. Criptografei a mesma fábula mudando os alfabetos em três letras e descobri que 'h' é de fato a letra mais popular aqui.
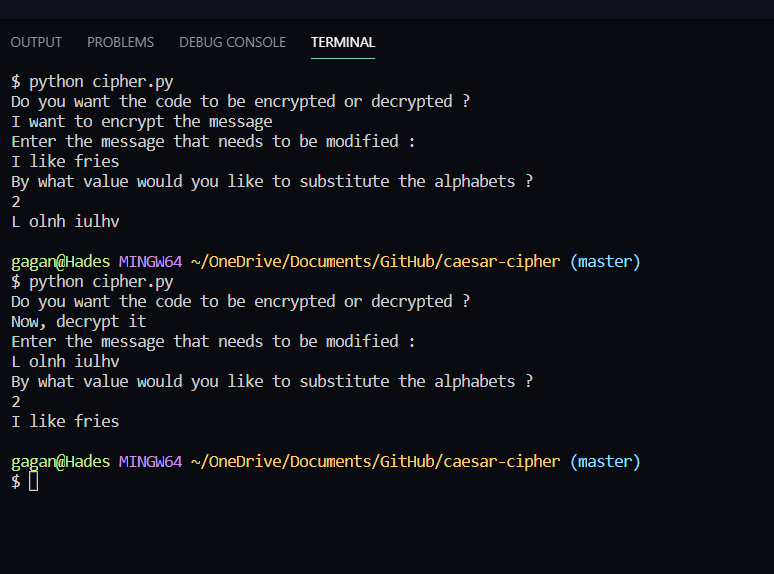
Para reproduzir os resultados da minha cifra e explorá-la com outras mensagens, além do python é necessário ter o matplotlib instalado.
pip install matplotlibLembre-se : o decodificador funciona com base no princípio da linguística e da estatística, portanto, quanto maior a mensagem, mais preciso será o resultado.
Gagan Devagiri © MIT


