Este guia o ajudará a montar e testar uma versão prévia do desenvolvedor do produto RHEL AI.
Bem-vindo à Prévia do Desenvolvedor de IA do Red Hat Enterprise Linux! Este guia tem como objetivo apresentar os recursos do RHEL AI Developer Preview. Tal como acontece com outras prévias do desenvolvedor, espere mudanças nesses fluxos de trabalho, automação e simplificação adicionais, bem como uma ampliação de recursos, versões de suporte de hardware e software, melhorias de desempenho (e outras otimizações) antes do GA.
RHEL AI é um produto de código aberto que inclui:
Observação
RHEL AI é direcionado a plataformas de servidores e estações de trabalho com GPUs discretas. Para laptops, use o InstructLab upstream.
Aqui está uma lista de servidores validados pelos engenheiros da Red Hat para trabalhar com o RHEL AI Developer Preview. Prevemos que os sistemas recentes certificados para executar o RHEL 9, com GPUs de datacenter recentes, como os listados abaixo, funcionarão com este Developer Preview.
| Fornecedor / especificações de GPU | Pré-visualização do RHEL AI Dev |
|---|---|
| Dell (4) NVIDIA H100 | Sim |
Instâncias IBM GX3 | Sim |
| Lenovo (8) AMD MI300x | Sim |
| Instâncias AWS p4 e p5 (NVIDIA) | Em andamento |
| Informações | Em andamento |
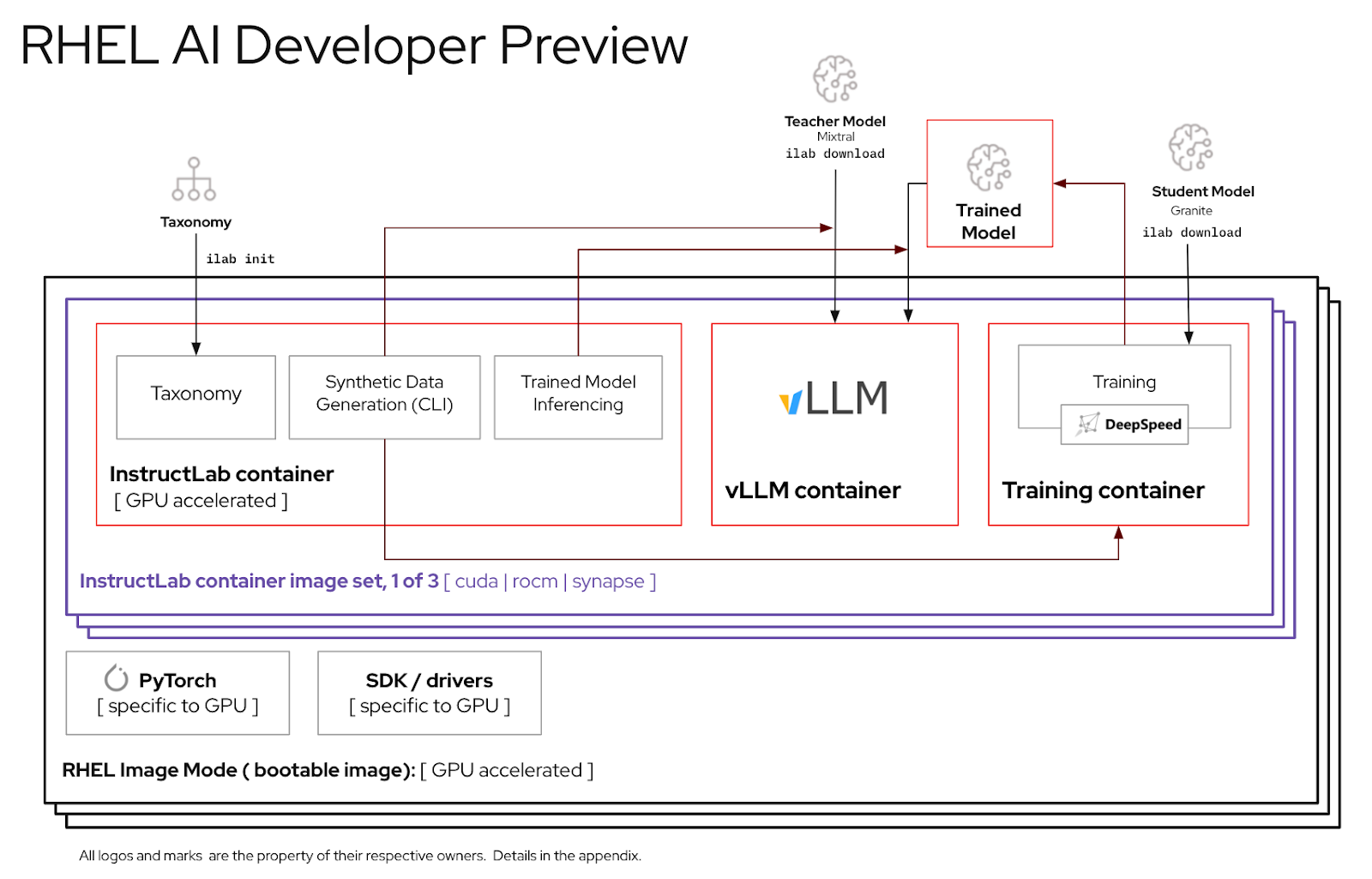
Para a melhor experiência usando o período de visualização do desenvolvedor RHEL AI, incluímos uma árvore de taxonomia podada dentro do contêiner InstructLab. Isso permitirá que o treinamento de validação seja concluído em um prazo razoável em um único servidor.
Fórmula: uma única GPU pode treinar aproximadamente 250 amostras por minuto. Se você tiver 8 GPUs e 10.000 amostras, espere que demore
Ao final deste exercício, você terá:
bootc é um sistema operacional transacional local que provisiona e atualiza usando imagens de contêiner OCI/Docker. bootc é o componente chave em uma missão mais ampla de contêineres inicializáveis.
O modelo original de contêiner do Docker de usar "camadas" para modelar aplicativos tem sido extremamente bem-sucedido. Este projeto visa aplicar a mesma técnica para sistemas host inicializáveis - usando contêineres OCI/Docker padrão como formato de transporte e entrega para atualizações do sistema operacional básico.
A imagem do contêiner inclui um kernel Linux (por exemplo, /usr/lib/modules ), que é usado para inicializar. No tempo de execução em um sistema de destino, o espaço do usuário base não está em execução em um contêiner por padrão. Por exemplo, supondo que systemd esteja em uso, systemd atua como pid1 normalmente - não há processo "externo".
No exemplo a seguir, o contêiner bootc é rotulado como Node Base Image :
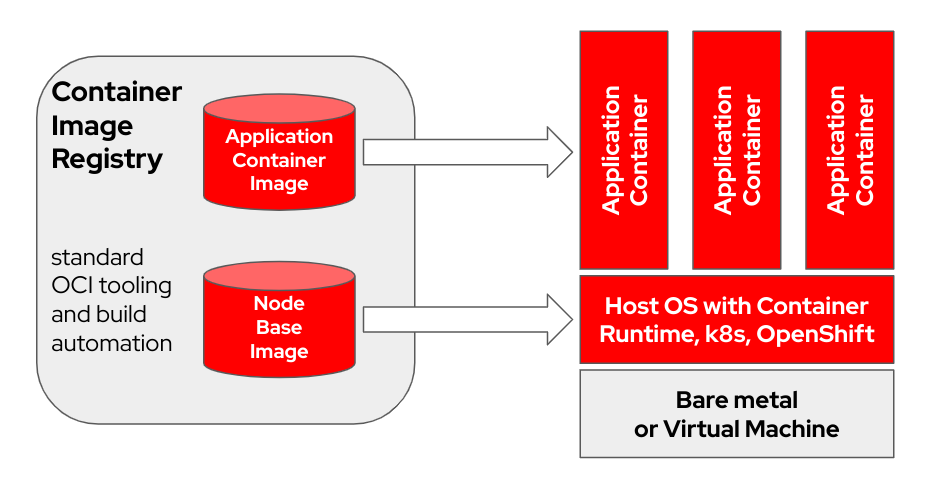
Dependendo do hardware do host de compilação e da velocidade da conexão com a Internet, a criação e o upload de imagens de contêiner podem levar até duas horas.
m5.xlarge usando armazenamento GP3)quay.io ou outro registro de imagem. Registre o host (Como registrar e assinar um sistema RHEL no Portal do Cliente Red Hat usando o Red Hat Subscription-Manager?)
sudo subscription-manager register --username < username > --password < password >Instale os pacotes necessários
sudo dnf install git make podman buildah lorax -yClone o repositório git RHEL AI Developer Preview
git clone https://github.com/RedHatOfficial/rhelai-dev-preview Autentique-se no registro Red Hat (Red Hat Container Registry Authentication) usando sua conta redhat.com .
podman login registry.redhat.io --username < username > --password < password >
podman login --get-login registry.redhat.io
Your_login_here Certifique-se de ter uma chave SSH no host de compilação. Isso é usado durante a construção da imagem do kit de ferramentas do driver. (Usando ssh-keygen e compartilhamento para autenticação baseada em chave no Linux | Habilitar Sysadmin)
RHEL AI inclui um conjunto de Makefiles para facilitar a criação de imagens de contêiner. Dependendo do hardware do host de compilação e da velocidade da conexão com a Internet, isso pode levar até uma hora.
Crie a imagem do contêiner NVIDIA do InstructLab.
make instruct-nvidia Crie a imagem do contêiner vllm .
make vllm Crie a imagem do contêiner deepspeed .
make deepspeed Por último, construa a imagem do contêiner RHEL AI NVIDIA bootc . Este é o contêiner “inicializável” do modo de imagem RHEL. Incorporamos as 3 imagens acima neste contêiner.
make nvidia FROM=registry.redhat.io/rhel9/rhel-bootc:9.4 REGISTRY= < your-registry > REGISTRY_ORG= < your-org-name > A imagem resultante é marcada como ${REGISTRY}/${REGISTRY_ORG}/nvidia-bootc:latest . Para mais variáveis e exemplos, consulte o treinamento/README.
Envie a imagem resultante para o seu registro. Você fará referência a esse URL em um arquivo kickstart em uma próxima etapa.
podman push ${REGISTRY} / ${REGISTRY_ORG} /nvidia-bootc:latest
e.g. podman push quay.io/ < your-user-name > /nvidia-bootc.latestNeste ponto você tem uma imagem de contêiner inicializável RHEL AI pronta para ser instalada em um host físico ou virtual.
Anaconda é o instalador do Red Hat Enterprise Linux e está incorporado em todas as imagens ISO para download do RHEL. O principal método de automatizar a instalação do RHEL é por meio de scripts chamados Kickstart. Para obter mais informações sobre o Anaconda e o Kickstart, leia estes documentos.
Um comando kickstart recente chamado ostreecontainer foi introduzido com RHEL 9.4. Usamos ostreecontainer para provisionar o contêiner nvidia-bootc inicializável que você acabou de enviar para o seu registro pela rede.
Aqui está um exemplo de arquivo kickstart. Copie-o para um arquivo chamado rhelai-dev-preview-bootc.ks e personalize-o para seu ambiente:
# text
## customize this for your target system
# network --bootproto=dhcp --device=link --activate
## Basic partitioning
## customize this for your target system
# clearpart --all --initlabel --disklabel=gpt
# reqpart --add-boot
# part / --grow --fstype xfs
# ostreecontainer --url quay.io/<your-user-name>/nvidia-bootc:latest
# firewall --disabled
# services --enabled=sshd
## optionally add a user
# user --name=cloud-user --groups=wheel --plaintext --password
# sshkey --username cloud-user "ssh-ed25519 AAAAC3Nza....."
## if desired, inject an SSH key for root
# rootpw --iscrypted locked
# sshkey --username root "ssh-ed25519 AAAAC3Nza..."
# reboot
Baixe o RHEL 9.4 “Boot ISO” e use o comando mkksiso para incorporar o kickstart no ISO de inicialização do RHEL.
mkksiso rhelai-dev-preview-bootc.ks rhel-9.4-x86_64-boot.iso rhelai-dev-preview-bootc-ks.isoNeste ponto você deve ter:
nvidia-bootc:latest : uma imagem de contêiner inicializável com suporte para GPUs NVIDIArhelai-dev-preview-bootc.ks : um arquivo kickstart personalizado para provisionar o RHEL do seu registro de contêiner para o seu sistema de destino.rhelai-dev-preview-bootc-ks.iso : um RHEL 9.4 ISO inicializável com o kickstart incorporado. Inicialize seu sistema de destino usando o arquivo rhelai-dev-preview-bootc-ks.iso . O anaconda extrairá a imagem nvidia-bootc:latest do seu registro e provisionará o RHEL de acordo com o seu arquivo kickstart.
Alternativa : o arquivo kickstart pode ser servido via HTTP. Na instalação via linha de comando do kernel e um servidor HTTP externo – adicione inst.ks=http(s)://kickstart/url/rhelai-dev-preview-bootc.ks
Antes de usar o ambiente RHEL AI, você deve baixar dois modelos, cada um adaptado para uma função chave no processo de ajuste de alta fidelidade. O granito é utilizado como modelo de aluno e é responsável por facilitar o treinamento de uma nova modalidade afinada. Mixtral é usado como modelo de professor e é responsável por auxiliar na fase de geração do processo LAB, onde habilidades e conhecimento são usados em conjunto para produzir um rico conjunto de dados de treinamento.
Settings .Access Tokens . Clique no botão New token e forneça um nome. O novo token requer apenas o uso de permissões Read , pois está sendo usado apenas para buscar modelos. Nesta tela você poderá gerar o conteúdo do token e salvar e copiar o texto para autenticar. 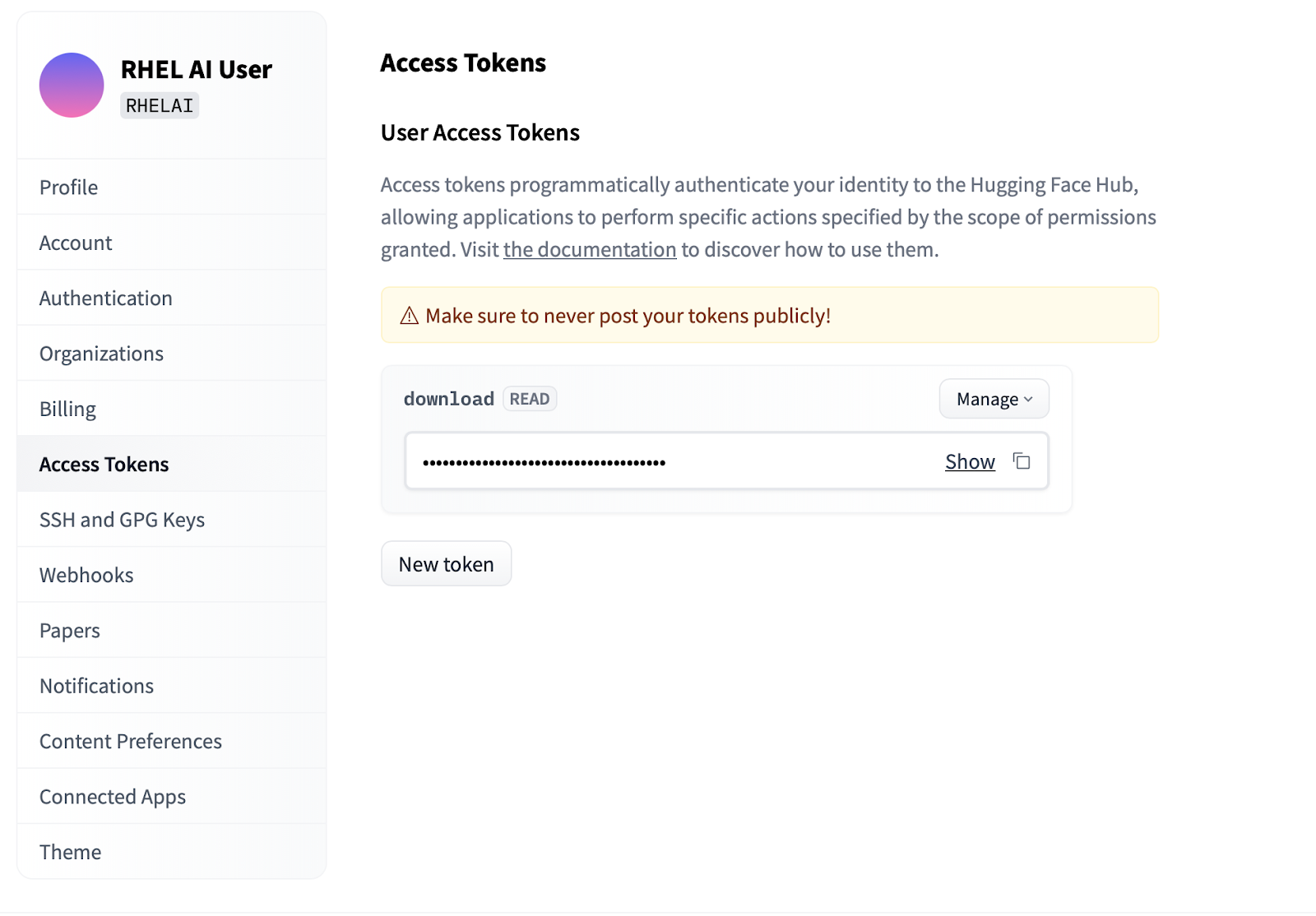
A interface de linha de comando ilab que faz parte do projeto InstructLab concentra-se na execução de modelos quantizados leves em dispositivos de computação pessoal, como laptops. Em contraste, o RHEL AI permite o uso de treinamento de alta fidelidade usando modelos de precisão total. Para maior familiaridade, o comando e os parâmetros refletem os do comando ilab do InstructLab; no entanto, a implementação do apoio é muito diferente.
No RHEL AI, o comando
ilabé um wrapper que atua como front-end para uma arquitetura de contêiner pré-empacotada no sistema RHEL AI.
ilabA primeira etapa é criar um novo diretório de trabalho para o seu projeto. Tudo será relativo a este diretório de trabalho. Ele conterá seus modelos, logs e dados de treinamento.
mkdir my-project
cd my-project O primeiro comando ilab que você executará configura o ambiente base, incluindo o download do repositório de taxonomia, se desejar. Isso será necessário para etapas posteriores, por isso é recomendável fazê-lo.
ilab initDefina uma variável de ambiente usando o token HF que você criou na seção acima em Tokens de acesso.
export HF_TOKEN= < paste token value here > Em seguida, faça download do modelo base do IBM Granite. Importante: Não baixe as versões “laboratório” do modelo. O modelo de base de granito é mais eficaz ao realizar treinamentos de alta fidelidade.
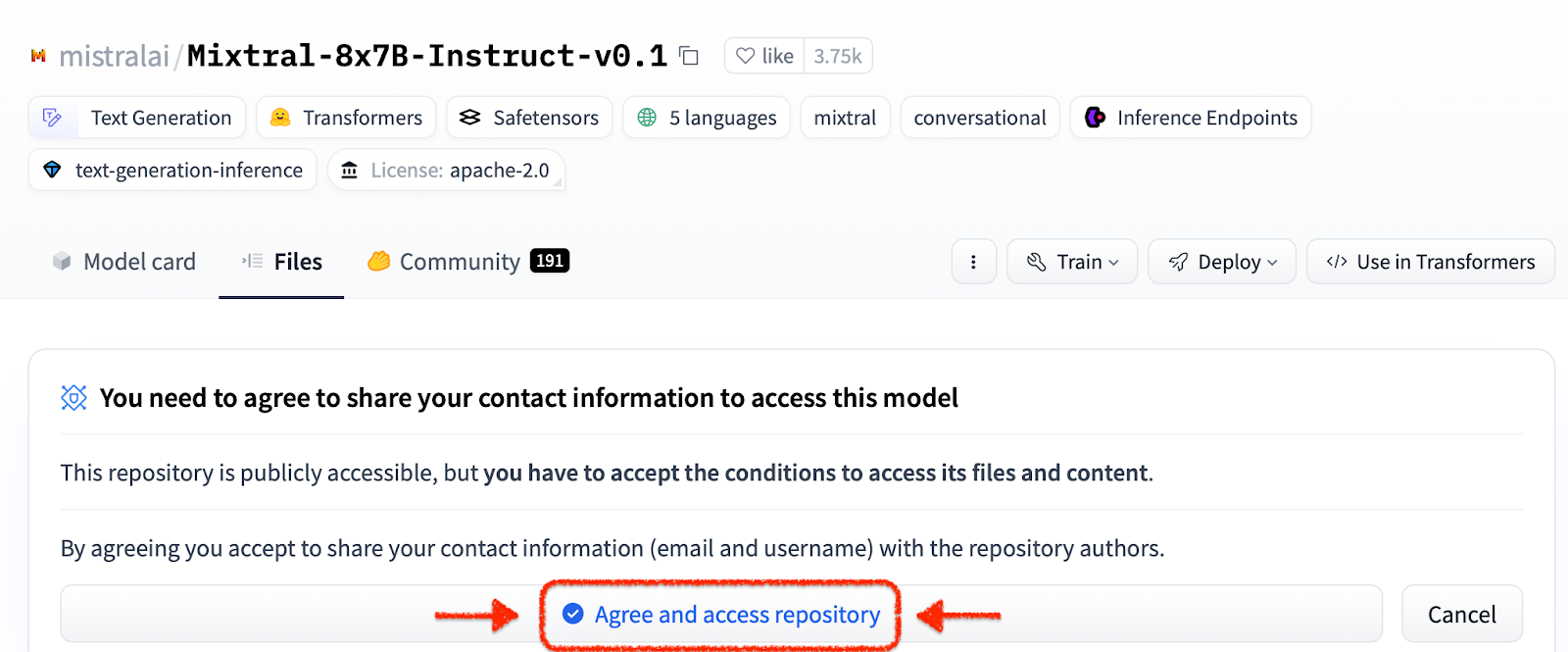
ilab download --repository ibm/granite-7b-baseSiga o mesmo processo para baixar o modelo Mixtral.
ilab download --repository mistralai/Mixtral-8x7B-Instruct-v0.1Agora que você inicializou seu projeto e baixou seus primeiros modelos, observe a estrutura de diretórios do seu projeto
my-project/
├─ models/
├─ generated/
├─ taxonomy/
├─ training/
├─ training_output/
├─ cache/
| Pasta | Propósito |
|---|---|
| modelos | Contém todos os modelos de linguagem, incluindo a saída salva daqueles que você gera com RHEL AI |
| gerado | Saída de dados gerada a partir da fase de geração, baseada em modificações no repositório de taxonomia |
| taxonomia | Dados de habilidade ou conhecimento usados pelo método LAB para gerar dados sintéticos para treinamento |
| treinamento | Dados iniciais convertidos para facilitar o processo de treinamento |
| treinamento_saída | Todos os resultados transitórios do processo de treinamento, incluindo registros e pontos de verificação de amostras em voo |
| esconderijo | Um cache interno usado pelos dados do modelo |
A próxima etapa é contribuir com novos conhecimentos ou habilidades para o repositório de taxonomia. Consulte a documentação do InstructLab para obter mais informações e exemplos de como fazer isso. Também temos um conjunto de exercícios de laboratório aqui.
Com os dados adicionais de taxonomia adicionados, agora é possível gerar novos dados sintéticos para eventualmente treinar um novo modelo. Embora, antes que a geração possa começar, um modelo de professor precise primeiro ser iniciado para auxiliar o gerador na construção de novos dados. Em uma sessão de terminal separada, execute o comando “servir” e aguarde a conclusão da inicialização do VLLM. Observe que este processo pode levar vários minutos para ser concluído
ilab serve
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit) Agora que o VLLM está servindo o modo professor, o processo de geração pode ser iniciado usando o comando ilab generate. Este processo levará algum tempo para ser concluído e produzirá continuamente o número total de instruções geradas à medida que for atualizado. O padrão é 5.000 instruções, mas você pode ajustar isso com a opção --num-instructions .
ilab generate Q> How do cytokines influence the outcome of certain diseases involving tonsils?
A> The outcome of infectious, autoimmune, or malignant diseases affecting tonsils may be influenced by the overall balance of production profiles of pro-inflammatory and anti-inflammatory cytokines. Determining cytokine profiles in tonsil studies is essential for understanding the causes and underlying mechanisms of these disorders.
35%|████████████████████████████████████████▉
Além dos dados atuais impressos na tela durante a geração, uma saída completa é gravada na pasta gerada. Antes do treinamento, recomenda-se revisar este resultado para verificar se ele atende às expectativas. Se não for satisfatório, tente modificar ou criar novos exemplos na taxonomia e reexecutar.
less generated/generated_Mixtral * .jsonAssim que os dados gerados forem satisfatórios, o processo de treinamento pode começar. Embora primeiro feche a instância do VLLM na sessão do terminal que foi iniciada para geração.
CTRL+C
INFO: Application shutdown complete.
INFO: Finished server process [1]
Você pode receber uma exceção Python KeyboardInterrupt e rastreamento de pilha. Isso pode ser ignorado com segurança.
Com o VLLM parado e os novos dados gerados, o processo de treinamento pode ser iniciado usando o comando ilab train . Por padrão, o processo de treinamento salva um ponto de verificação do modelo a cada 4.999 amostras. Você pode ajustar isso usando o parâmetro --num-samples . Além disso, o treinamento padrão é executado por 10 épocas, o que também pode ser ajustado com o parâmetro --num-epochs . Geralmente, mais épocas são melhores, mas depois de um certo ponto, mais épocas resultarão em overfitting. Normalmente, é recomendado permanecer dentro de 10 épocas ou menos e observar diferentes pontos de amostra para encontrar o melhor resultado.
ilab train --num-epochs 9 RunningAvgSamplesPerSec=149.4829861942806, CurrSamplesPerSec=161.99957513920629, MemAllocated=22.45GB, MaxMemAllocated=29.08GB
throughput: 161.84935045724643 samples/s, lr: 1.3454545454545455e-05, loss: 0.840185821056366 cuda_mem_allocated: 22.45188570022583 GB cuda_malloc_retries: 0 num_loss_counted_tokens: 8061.0 batch_size: 96.0 total loss: 0.8581467866897583
Epoch 1: 100%|█████████████████████████████████████████████████████████| 84/84 [01:09<00:00, 1.20it/s]
total length: 2527 num samples 15 - rank: 6 max len: 187 min len: 149
Assim que o processo de treinamento for concluído, as novas entradas do modelo serão armazenadas no diretório de modelos com locais impressos no terminal
Generated model in /root/workspace/models/tuned-0504-0051:
.
./samples_4992
./samples_9984
./samples_14976
./samples_19968
./samples_24960
./samples_29952
./samples_34944
./samples_39936
./samples_44928
./samples_49920
O mesmo comando ilab serve pode ser usado para servir o novo modelo, passando a opção –model com o nome e amostra
ilab serve --model tuned-0504-0051/samples_49920 Depois que o VLLM for iniciado com o novo modelo, uma sessão de chat poderá ser iniciada criando uma nova sessão de terminal e passando o mesmo parâmetro --model para chat (observe que se isso não corresponder, você receberá uma mensagem de erro 404). Faça uma pergunta relacionada às suas contribuições para a taxonomia.
ilab chat --model tuned-0504-0051/samples_49920╭─────────────────────────────── system ────────────────────────────────╮
│ Welcome to InstructLab Chat w/ │
│ /INSTRUCTLAB/MODELS/TUNED-0504-0051/SAMPLES_49920 (type /h for help) │
╰───────────────────────────────────────────────────────────────────────╯
>>> What are tonsils ?
╭────────── /instructlab/models/tuned-0504-0051/samples_49920 ──────────╮
│ │
│ Tonsils are a type of mucosal lymphatic tissue found in the │
│ aerodigestive tracts of various mammals, including humans. In the │
│ human body, the tonsils play a crucial role in protecting the body │
│ from infections, particularly those caused by bacteria and viruses. │
╰─────────────────────────────────────────────── elapsed 0.469 seconds ─╯Para sair da sessão, digite
exit
É isso! O objetivo de uma prévia do desenvolvedor é divulgar algo aos nossos usuários para feedback antecipado. Percebemos que pode haver bugs. E agradecemos seu tempo e esforço se você chegou até aqui. Provavelmente, você encontrou alguns problemas ou precisou solucioná-los. Incentivamos você a enviar relatórios de bugs, solicitações de recursos e nos fazer perguntas. Veja as informações de contato abaixo para saber como fazer isso. Obrigado!
$ sudo subscription-manager config --rhsm.manage_repos=1nvidia-smi para garantir que os drivers funcionem e possam ver as GPUsnvtop (disponível em EPEL) para ver se as GPUs estão sendo usadas (alguns caminhos de código possuem substituto de CPU, o que não queremos aqui)make prune no subdiretório de treinamento. Isso limpará artefatos de construção antigos.--no-cache para o processo de construção make nvidia-bootc CONTAINER_TOOL_EXTRA_ARGS= " --no-cache "TMPDIR : make < platform > TMPDIR=/path/to/tmp

