test arranger
v1.6.3
No TDD existem 3 fases: organizar, agir e afirmar (dado, quando, então no BDD). A fase assert tem ótimo suporte de ferramentas, você deve estar familiarizado com AssertJ, FEST-Assert ou Hamcrest. Está em contraste com a fase de organização. Embora a organização de dados de teste seja muitas vezes desafiadora e uma parte significativa do teste seja normalmente dedicada a ela, é difícil apontar uma ferramenta que apoie isso.
O Test Arranger tenta preencher essa lacuna organizando instâncias de classes necessárias para os testes. As instâncias são preenchidas com valores pseudoaleatórios que simplificam o processo de criação de dados de teste. O testador declara apenas os tipos dos objetos necessários e obtém novas instâncias. Quando um valor pseudo-aleatório para um determinado campo não é bom o suficiente, apenas este campo deve ser definido manualmente:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Ocado" );< dependency >
< groupId >com.ocadotechnology.gembus</ groupId >
< artifactId >test-arranger</ artifactId >
< version >1.6.3</ version >
</ dependency >testImplementation ' com.ocadotechnology.gembus:test-arranger:1.6.3 ' A classe Arranger possui vários métodos estáticos para gerar valores pseudo-aleatórios de tipos simples. Cada um deles possui uma função de encapsulamento para simplificar as chamadas para Kotlin. Algumas das chamadas possíveis estão listadas abaixo:
| Java | Kotlin | resultado |
|---|---|---|
Arranger.some(Product.class) | some<Product>() | uma instância de Produto com todos os campos preenchidos com valores |
Arranger.some(Product.class, "brand") | some<Product>("brand") | uma instância de Produto sem valor para o campo marca |
Arranger.someSimplified(Category.class) | someSimplified<Category>() | uma instância de Categoria, os campos do tipo coleção têm o tamanho reduzido para 1 e a profundidade da árvore de objetos é limitada a 3 |
Arranger.someObjects(Product.class, 7) | someObjects<Product>(7) | um fluxo de tamanho 7 de instâncias de Produto |
Arranger.someEmail() | someEmail() | uma string contendo endereço de e-mail |
Arranger.someLong() | someLong() | um número pseudoaleatório do tipo long |
Arranger.someFrom(listOfCategories) | someFrom(listOfCategories) | uma entrada do listOfCategories |
Arranger.someText() | someText() | uma string gerada a partir de uma cadeia de Markov; por padrão, é uma cadeia muito simples, mas pode ser reconfigurada colocando outro arquivo 'enMarkovChain' no classpath de teste com definição alternativa, você pode encontrar um treinado em um corpus em inglês aqui; consulte o arquivo 'enMarkovChain' incluído no projeto para o formato do arquivo |
| - | some<Product> {name = "not so random"} | uma instância de Produto com todos os campos preenchidos com valores aleatórios, exceto name que está definido como "não tão aleatório", esta sintaxe pode ser usada para definir quantos campos do objeto forem necessários, mas cada um dos objetos deve ser mutável |
Dados completamente aleatórios podem não ser adequados para todos os casos de teste. Freqüentemente, há pelo menos um campo que é crucial para o objetivo do teste e precisa de um determinado valor. Quando a classe organizada é mutável, ou é uma classe de dados Kotlin, ou há uma maneira de criar uma cópia alterada (por exemplo, @Builder(toBuilder = true) do Lombok), basta usar o que está disponível. Felizmente, mesmo que não seja ajustável, você pode usar o Test Arranger. Existem versões dedicadas dos métodos some() e someObjects() que aceitam um parâmetro do tipo Map<String,Supplier> . As chaves neste mapa representam nomes de campos, enquanto os fornecedores correspondentes fornecem valores que o Test Arranger definirá para você nesses campos, por exemplo:
Product product = Arranger . some ( Product . class , Map . of ( "name" , () -> value ));Por padrão, os valores aleatórios são gerados de acordo com o tipo de campo. Valores aleatórios nem sempre correspondem bem aos invariantes de classe. Quando uma entidade sempre precisa ser organizada de acordo com algumas regras relativas aos valores dos campos, você pode fornecer um organizador personalizado:
class ProductArranger extends CustomArranger < Product > {
@ Override
protected Product instance () {
Product product = enhancedRandom . nextObject ( Parent . class );
product . setPrice ( BigDecimal . valueOf ( Arranger . somePositiveLong ( 9_999L )));
return product ;
}
} Para ter controle sobre o processo de instanciação Product precisamos substituir o método instance() . Dentro do método podemos criar a instância do Product como quisermos. Especificamente, podemos gerar alguns valores aleatórios. Por conveniência, temos um campo enhancedRandom na classe CustomArranger . No exemplo dado, geramos uma instância de Product com todos os campos possuindo valores pseudo-aleatórios, mas depois alteramos o preço para algo aceitável em nosso domínio. Isso não é negativo e é menor que o número 10k.
O ProductArranger é automaticamente (usando reflexão) capturado pelo Arranger e usado sempre que uma nova instância de Product é solicitada. Não se trata apenas de chamadas diretas como Arranger.some(Product.class) , mas também indiretas. Supondo que exista a classe Shop com campo products do tipo List<Product> . Ao chamar Arranger.some(Shop.class) , o arranjador usará ProductArranger para criar todos os produtos armazenados em Shop.products .
O comportamento do organizador de teste pode ser configurado usando propriedades. Se você criar o arquivo arranger.properties e salvá-lo na raiz do classpath (geralmente será o diretório src/test/resources/ ), ele será selecionado e as seguintes propriedades serão aplicadas:
arranger.root Os arranjadores personalizados são escolhidos usando reflexão. Todas as classes que estendem CustomArranger são consideradas arranjadores personalizados. A reflexão está focada em um determinado pacote que por padrão é com.ocado . Isso não é necessariamente conveniente para você. No entanto, com arranger.root=your_package pode ser alterado para your_package . Tente ter o pacote o mais específico possível, pois ter algo genérico (por exemplo, apenas com , que é o pacote raiz em muitas bibliotecas), resultará na verificação de centenas de classes, o que levará um tempo considerável.arranger.randomseed Por padrão, sempre a mesma semente é usada para inicializar o gerador de valores pseudoaleatórios subjacente. Como consequência, as execuções subsequentes gerarão os mesmos valores. Para obter aleatoriedade entre as execuções, ou seja, para sempre começar com outros valores aleatórios, é necessário definir arranger.randomseed=true .arranger.cache.enable O processo de organização de instâncias aleatórias requer algum tempo. Se você criar um grande número de instâncias e não precisar que elas sejam completamente aleatórias, habilitar o cache pode ser a melhor opção. Quando ativado, o cache armazena referência a cada instância aleatória e, em algum momento, o organizador de testes para de criar novas e, em vez disso, reutiliza as instâncias armazenadas em cache. Por padrão, o cache está desabilitado.arranger.overridedefaults O Test-arranger respeita a inicialização padrão do campo, ou seja, quando existe um campo inicializado com uma string vazia, a instância retornada pelo test-arranger possui a string vazia neste campo. Nem sempre é o que você precisa nos testes, principalmente, quando existe uma convenção no projeto para inicializar campos com valores vazios. Felizmente, você pode forçar o test-arranger a substituir os padrões por valores aleatórios. Defina arranger.overridedefaults como true para substituir a inicialização padrão.arranger.maxRandomizationDepth Algumas estruturas de dados de teste podem gerar cadeias de objetos de qualquer comprimento que fazem referência entre si. No entanto, para utilizá-los efetivamente em um caso de teste, é crucial controlar o comprimento dessas cadeias. Por padrão, o Test-arranger para de criar novos objetos no 4º nível de profundidade de aninhamento. Se esta configuração padrão não for adequada aos casos de teste do seu projeto, ela poderá ser ajustada usando este parâmetro. Quando você tem um registro Java que pode ser usado como dados de teste, mas precisa alterar um ou dois de seus campos, a classe Data com seu método copy fornece uma solução. Isto é particularmente útil ao lidar com registros imutáveis que não possuem uma maneira óbvia de alterar seus campos diretamente.
O método Data.copy permite criar uma cópia superficial de um registro enquanto modifica seletivamente os campos desejados. Ao fornecer um mapa de substituições de campos, você pode especificar os campos que precisam ser alterados e seus novos valores. O método copy se encarrega de criar uma nova instância do registro com os valores dos campos atualizados.
Essa abordagem evita que você crie manualmente um novo objeto de registro e configure os campos individualmente, fornecendo uma maneira conveniente de gerar dados de teste com pequenas variações dos registros existentes.
No geral, a classe Data e seu método copy resgatam a situação ao permitir a criação de cópias superficiais de registros com campos selecionados alterados, proporcionando flexibilidade e conveniência ao trabalhar com tipos de registros imutáveis:
Data . copy ( myRecord , Map . of ( "recordFieldName" , () -> "altered value" ));Ao passar pelos testes de um projeto de software raramente se tem a impressão de que ele não pode ser feito melhor. No âmbito da organização de dados de teste, há duas áreas que estamos tentando melhorar com o Test Arranger.
Os testes são muito mais fáceis de entender quando se conhece a intenção do criador, ou seja, por que o teste foi escrito e que tipo de problemas ele deve detectar. Infelizmente, não é extraordinário ver testes tendo na seção de organização (dada) instruções como a seguinte:
Product product = Product . builder ()
. withName ( "Some name" )
. withBrand ( "Some brand" )
. withPrice ( new BigDecimal ( "12.99" ))
. withCategory ( "Water, Juice & Drinks / Juice / Fresh" )
...
. build ();Ao analisar esse código, é difícil dizer quais valores são relevantes para o teste e quais são fornecidos apenas para satisfazer alguns requisitos não nulos. Se o teste é sobre a marca, por que não escrever assim:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );Agora é óbvio que a marca é importante. Vamos tentar dar um passo adiante. Todo o teste pode ser o seguinte:
//arrange
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( "Some brand" ) Estamos testando agora que o relatório foi criado para a marca “Alguma marca”. Mas será esse o objetivo? Faz mais sentido esperar que o relatório seja gerado para a mesma marca à qual o produto está atribuído. Então o que queremos testar é:
//arrange
Product product = Arranger . some ( Product . class );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( product . getBrand ()) Caso o campo marca seja mutável e tenhamos medo que o sut possa modificá-lo, podemos armazenar seu valor em uma variável antes de entrar na fase de ato e posteriormente utilizá-lo para a afirmação. O teste será mais longo, mas a intenção permanece clara.
Vale ressaltar que o que acabamos de fazer é uma aplicação dos padrões de Valor Gerado e, até certo ponto, do Método de Criação descritos em xUnit Test Patterns: Refactoring Test Code de Gerard Meszaros.
Você já mudou alguma coisa no código de produção e acabou com erros em dezenas de testes? Alguns deles relatando falha na afirmação, alguns talvez até se recusando a compilar. Este é um cheiro de código de cirurgia de espingarda que acabou de atingir seus testes inocentes. Bem, talvez não tão inocentes, pois poderiam ser concebidos de forma diferente, para limitar os danos colaterais causados por pequenas mudanças. Vamos analisá-lo usando um exemplo. Suponha que temos em nosso domínio a seguinte classe:
class TimeRange {
private LocalDateTime start ;
private long durationinMs ;
public TimeRange ( LocalDateTime start , long durationInMs ) {
... e que é usado em muitos lugares. Principalmente nos testes, sem Test Arranger, usando instruções como esta: new TimeRange(LocalDateTime.now(), 3600_000L); O que acontecerá se por algum motivo importante formos forçados a mudar a classe para:
class TimeRange {
private LocalDateTime start ;
private LocalDateTime end ;
public TimeRange ( LocalDateTime start , LocalDateTime end ) {
... É bastante desafiador criar uma série de refatorações que transformem a versão antiga na nova sem quebrar todos os testes dependentes. O mais provável é um cenário em que os testes sejam ajustados à nova API da classe um por um. Isso significa muito trabalho não exatamente emocionante, com muitas perguntas sobre o valor desejado de duração (devo convertê-lo cuidadosamente para o end do tipo LocalDateTime ou era apenas um valor aleatório conveniente). A vida seria muito mais fácil com o Test Arranger. Quando em todos os lugares que exigem apenas TimeRange não nulo temos Arranger.some(TimeRange.class) , é tão bom para a nova versão do TimeRange quanto era para a antiga. Isso nos deixa com aqueles poucos casos que não exigem TimeRange aleatório, mas como já usamos Test Arranger para revelar a intenção do teste, em cada caso sabemos exatamente qual valor deve ser usado para TimeRange .
Mas não é só isso que podemos fazer para melhorar os testes. Presumivelmente, podemos identificar algumas categorias da instância TimeRange , por exemplo, intervalos do passado, intervalos do futuro e intervalos atualmente ativos. O TimeRangeArranger é um ótimo lugar para organizar isso:
class TimeRangeArranger extends CustomArranger < TimeRange > {
private final long MAX_DISTANCE = 999_999L ;
@ Override
protected TimeRange instance () {
LocalDateTime start = enhancedRandom . nextObject ( LocalDateTime . class );
LocalDateTime end = start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
public TimeRange fromPast () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime end = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( end . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )), end );
}
public TimeRange fromFuture () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )));
}
public TimeRange currentlyActive () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
LocalDateTime end = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
} Tal método de criação não deve ser criado antecipadamente, mas sim corresponder aos casos de teste existentes. No entanto, há chances de que o TimeRangeArranger cubra todos os casos em que instâncias do TimeRange são criadas para testes. Como consequência, no lugar de chamadas de construtor com vários parâmetros misteriosos, temos um arranjador com um método bem nomeado que explica o significado do domínio do objeto criado e ajuda na compreensão da intenção do teste.
Identificamos dois níveis de criadores de dados de teste ao discutir os desafios resolvidos pelo Test Arranger. Para completar o quadro precisamos citar pelo menos mais um, que são os Fixtures. Para fins desta discussão, podemos assumir que Fixture é uma classe projetada para criar estruturas complexas de dados de teste. O organizador personalizado é sempre focado em uma classe, mas às vezes você pode observar em seus casos de teste constelações recorrentes de duas ou mais classes. Pode ser o Usuário e sua conta bancária. Pode haver um CustomArranger para cada um deles, mas por que ignorar o fato de que eles geralmente vêm juntos? É nesse momento que devemos começar a pensar em um Fixture. Ele será responsável por criar a conta do Usuário e do Banco (presumivelmente usando organizadores personalizados dedicados) e vinculá-los. As luminárias são descritas em detalhes, incluindo diversas variantes de implementação em xUnit Test Patterns: Refactoring Test Code de Gerard Meszaros.
Portanto, temos três tipos de blocos de construção nas classes de teste. Cada um deles pode ser considerado a contrapartida de um conceito (bloco de construção do Domain Driven Design) do código de produção: 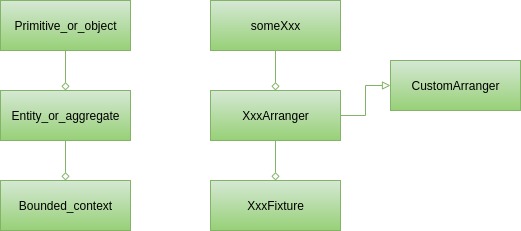
Na superfície, existem objetos primitivos e simples. Isso é algo que aparece até nos testes unitários mais simples. Você pode organizar a organização desses dados de teste com os métodos someXxx da classe Arranger .
Portanto, você pode ter serviços que exigem testes que funcionam somente em instâncias User ou em User e outras classes contidas na classe User , como uma lista de endereços. Para cobrir esses casos, normalmente é necessário um organizador personalizado, ou seja, o UserArranger . Ele criará instâncias de User respeitando todas as restrições e invariantes de classe. Além disso, irá pegar AddressArranger , quando existir, para preencher a lista de endereços com dados válidos. Quando vários casos de teste requerem um determinado tipo de usuário, por exemplo, usuários sem-teto com uma lista de endereços vazia, um método adicional pode ser criado no UserArranger. Como consequência, sempre que for necessário criar uma instância User para os testes, bastará olhar em UserArranger e selecionar um método de fábrica adequado ou apenas chamar Arranger.some(User.class) .
O caso mais desafiador diz respeito aos testes que dependem de grandes estruturas de dados. No comércio eletrônico, pode ser uma loja contendo muitos produtos, mas também contas de usuários com histórico de compras. Organizar dados para tais casos de teste geralmente não é trivial e repetir tal coisa não seria sensato. É muito melhor armazená-lo em uma classe dedicada sob um método bem nomeado, como shopWithNineProductsAndFourCustomers , e reutilizá-lo em cada um dos testes. Recomendamos fortemente o uso de uma convenção de nomenclatura para tais classes, para facilitar sua localização, nossa sugestão é usar o postfix Fixture . Eventualmente, podemos acabar com algo assim:
class ShopFixture {
Repository repo ;
public void shopWithNineProductsAndFourCustomers () {
Arranger . someObjects ( Product . class , 9 )
. forEach ( p -> repo . save ( p ));
Arranger . someObjects ( Customer . class , 4 )
. forEach ( p -> repo . save ( p ));
}
}A versão mais recente do test-arranger é compilada usando Java 17 e deve ser usada em tempo de execução Java 17+. No entanto, há também uma ramificação Java 8 para compatibilidade com versões anteriores, coberta pelas versões 1.4.x.


