self instruct
1.0.0
Este repositório contém código e dados para o artigo Self-Instruct, um método para alinhar modelos de linguagem pré-treinados com instruções.
Self-Instruct é uma estrutura que ajuda os modelos de linguagem a melhorar sua capacidade de seguir instruções em linguagem natural. Isso é feito usando as próprias gerações do modelo para criar uma grande coleção de dados instrucionais. Com o Self-Instruct, é possível melhorar os recursos de acompanhamento de instruções dos modelos de linguagem sem depender de extensas anotações manuais.
Nos últimos anos, tem havido um interesse crescente na construção de modelos que possam seguir instruções de linguagem natural para executar uma ampla gama de tarefas. Esses modelos, conhecidos como modelos de linguagem "ajustados à instrução", demonstraram a capacidade de generalização para novas tarefas. No entanto, o seu desempenho depende fortemente da qualidade e quantidade dos dados de instrução escritos por humanos utilizados para os treinar, que podem ser limitados em termos de diversidade e criatividade. Para superar estas limitações, é importante desenvolver abordagens alternativas para supervisionar modelos sintonizados com instruções e melhorar as suas capacidades de seguimento de instruções.
O processo Self-Instruct é um algoritmo de inicialização iterativo que começa com um conjunto inicial de instruções escritas manualmente e as utiliza para solicitar ao modelo de linguagem que gere novas instruções e instâncias de entrada-saída correspondentes. Essas gerações são então filtradas para remover aquelas de baixa qualidade ou semelhantes, e os dados resultantes são adicionados de volta ao pool de tarefas. Este processo pode ser repetido várias vezes, resultando em uma grande coleção de dados instrucionais que podem ser usados para ajustar o modelo de linguagem para seguir as instruções de forma mais eficaz.
Aqui está uma visão geral do Autoinstrução:
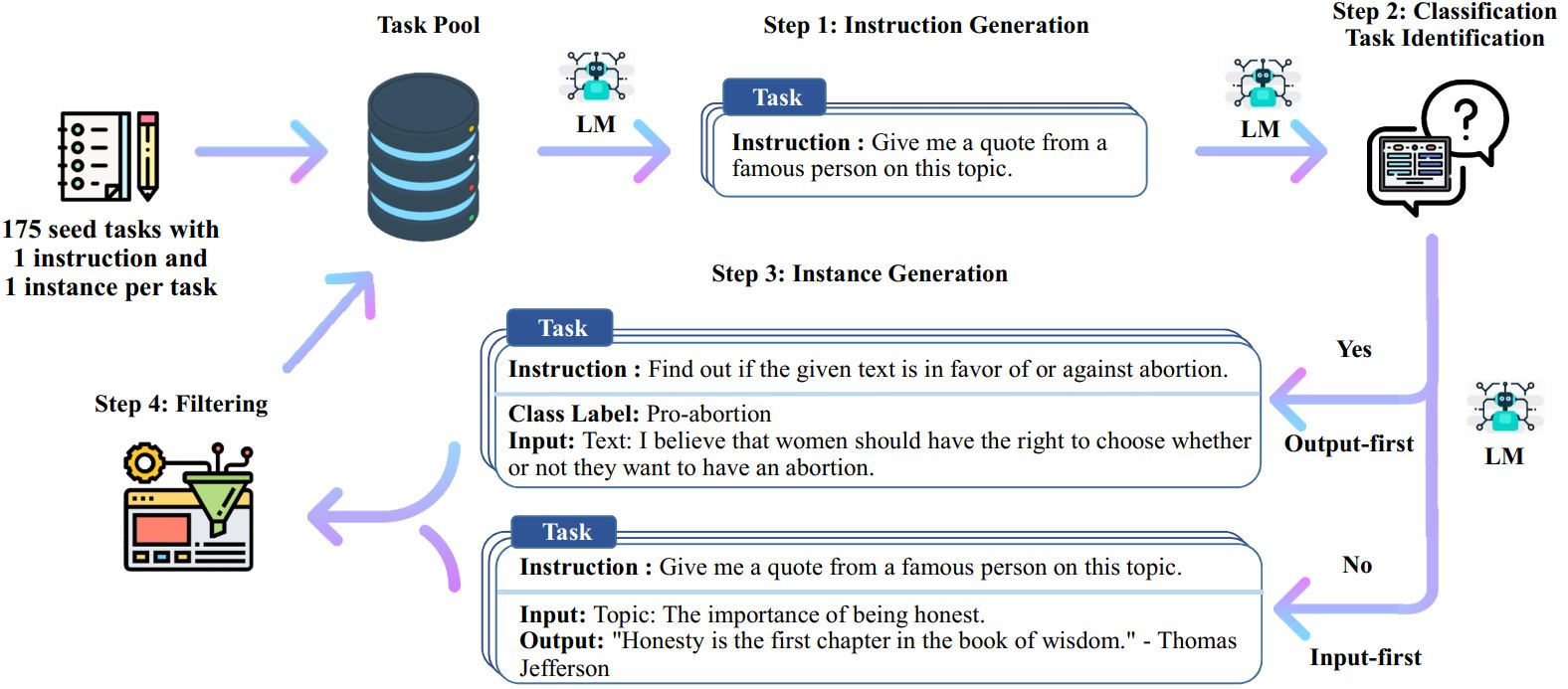
* Este trabalho ainda está em andamento. Podemos atualizar o código e os dados à medida que avançamos. Tenha cuidado com o controle de versão.
Lançamos um conjunto de dados que contém 52 mil instruções, emparelhadas com 82 mil entradas e saídas de instância. Esses dados de instrução podem ser usados para conduzir o ajuste de instrução para modelos de linguagem e fazer com que o modelo de linguagem siga melhor a instrução. Todos os dados gerados pelo modelo podem ser acessados em data/gpt3-generations/batch_221203/all_instances_82K.jsonl . Esses dados (+ as 175 tarefas iniciais) reformatados em formato limpo de ajuste fino GPT3 (prompt + conclusão) são colocados em data/finetuning/self_instruct_221203 . Você pode usar o script em ./scripts/finetune_gpt3.sh para ajustar o GPT3 nesses dados.
Nota : Esses dados são gerados por um modelo de linguagem (GPT3) e inevitavelmente contêm alguns erros ou preconceitos. Analisamos a qualidade dos dados em 200 instruções aleatórias em nosso artigo e descobrimos que 46% dos pontos de dados podem apresentar problemas. Encorajamos os usuários a utilizar esses dados com cautela e propomos novos métodos para filtrar ou melhorar as imperfeições.
Também lançamos um novo conjunto de 252 tarefas escritas por especialistas e suas instruções motivadas por aplicativos orientados ao usuário (em vez de tarefas de PNL bem estudadas). Esses dados são usados na seção de avaliação humana do artigo de autoinstrução. Consulte o README de avaliação humana para obter mais detalhes.
Para gerar dados de autoinstrução usando suas próprias tarefas iniciais ou outros modelos, abrimos o código-fonte de nossos scripts para todo o pipeline aqui. Nosso código atual é testado apenas no modelo GPT3 acessível por meio da API OpenAI.
Aqui estão os scripts para gerar os dados:
# 1. Gere instruções a partir das tarefas iniciais./scripts/generate_instructions.sh# 2. Identifique se a instrução representa uma tarefa de classificação ou não./scripts/is_clf_or_not.sh# 3. Gere instâncias para cada instrução./scripts/generate_instances. sh# 4. Filtragem, processamento e reformatação./scripts/prepare_for_finetuning.sh
Se você usar a estrutura ou dados do Self-Instruct, sinta-se à vontade para nos citar.
@misc{selfinstruct, title={Autoinstrução: Alinhando modelo de linguagem com instruções autogeradas}, autor={Wang, Yizhong e Kordi, Yeganeh e Mishra, Swaroop e Liu, Alisa e Smith, Noah A. e Khashabi, Daniel e Hajishirzi, Hannaneh}, diário = {pré-impressão arXiv arXiv:2212.10560}, ano={2022}} 

