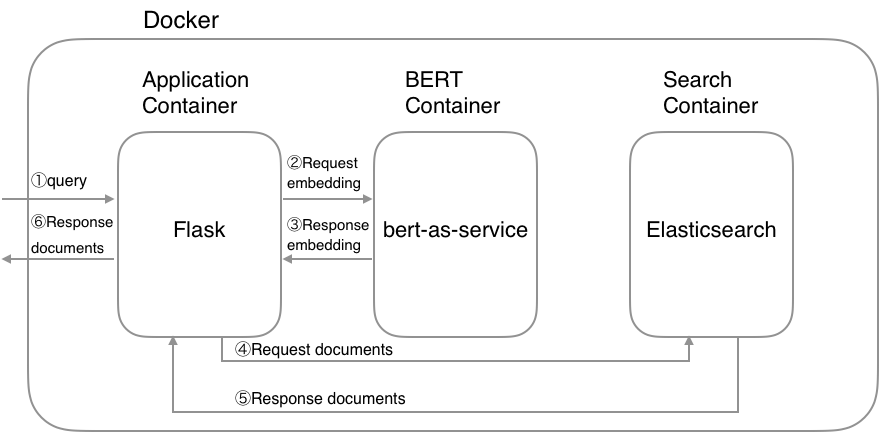
bertsearch
1.0.0
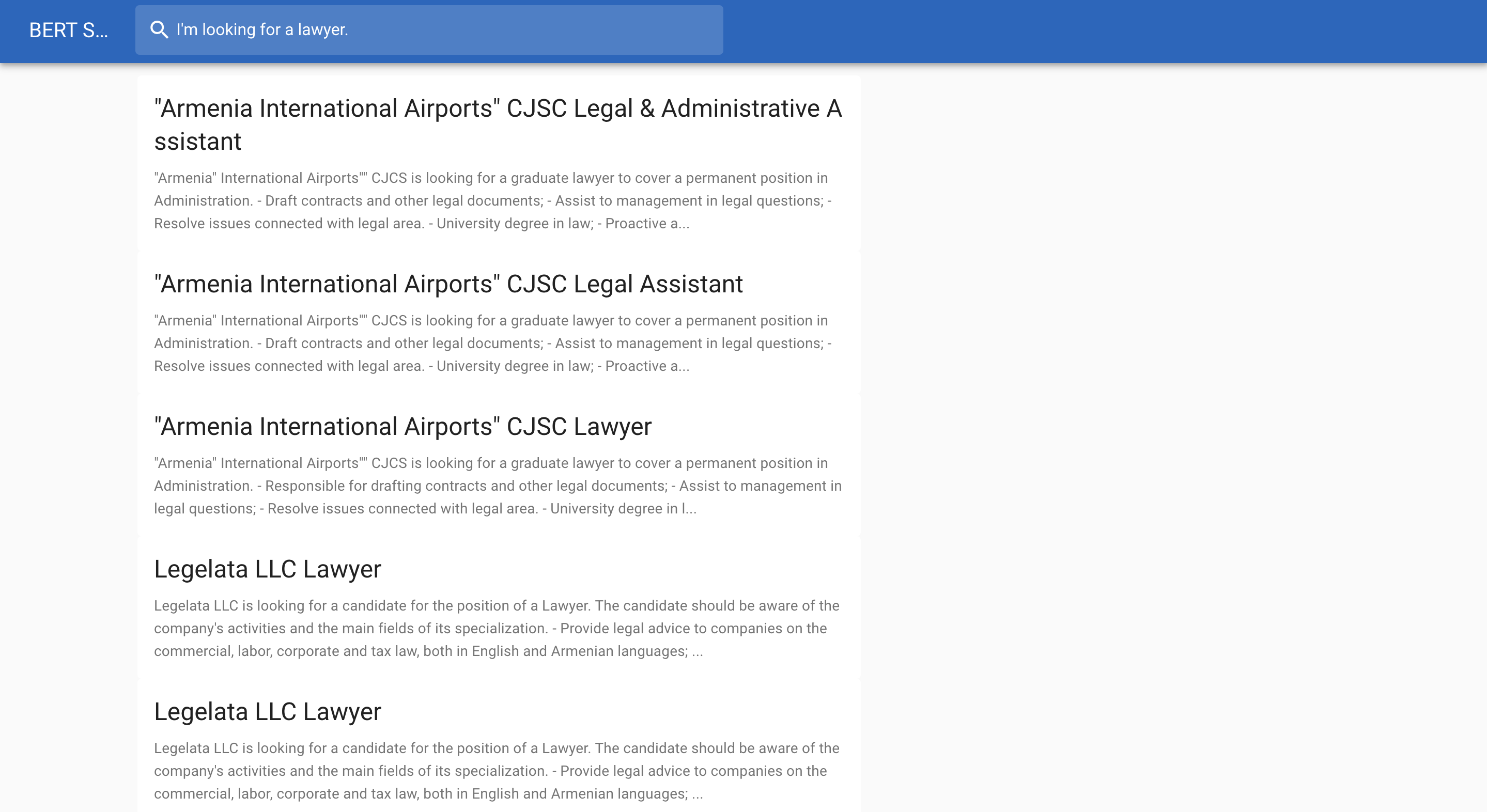
Abaixo está um exemplo de procura de emprego:
| Base BERT, sem caixa | Parâmetros de 12 camadas, 768 ocultos, 12 cabeças, 110M |
| BERT-Grande, sem caixa | Parâmetros de 24 camadas, 1024 ocultos, 16 cabeças, 340M |
| BERT-Base, Caseado | Parâmetros de 12 camadas, 768 ocultos, 12 cabeças, 110M |
| BERT-Grande, Invólucro | Parâmetros de 24 camadas, 1024 ocultos, 16 cabeças, 340M |
| BERT-Base, Caixa Multilíngue (Novo) | 104 idiomas, 12 camadas, 768 ocultos, 12 cabeças, 110M de parâmetros |
| Base BERT, caixa multilíngue (antiga) | 102 idiomas, 12 camadas, 768 ocultos, 12 cabeças, parâmetros de 110M |
| BERT-Base, chinês | Chinês simplificado e tradicional, 12 camadas, 768 ocultos, 12 cabeças, parâmetros 110M |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zipVocê precisa definir um modelo BERT pré-treinado e o nome do índice do Elasticsearch como variáveis de ambiente:
$ export PATH_MODEL=./cased_L-12_H-768_A-12
$ export INDEX_NAME=jobsearch$ docker-compose up CUIDADO : Se possível, atribua muita memória (mais de 8GB ) à configuração de memória do Docker porque o contêiner BERT precisa de muita memória.
Você pode usar a API de criação de índice para adicionar um novo índice a um cluster Elasticsearch. Ao criar um índice, você pode especificar o seguinte:
Por exemplo, se você deseja criar um índice jobsearch com os campos title , text e text_vector , você pode criar o índice com o seguinte comando:
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
} CUIDADO : O valor dims de text_vector deve corresponder aos dims de um modelo BERT pré-treinado.
Depois de criar um índice, você estará pronto para indexar algum documento. O objetivo aqui é converter seu documento em um vetor usando BERT. O vetor resultante é armazenado no campo text_vector . Vamos converter seus dados em um documento JSON:
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "Depois de terminar o script, você pode obter um documento JSON como segue:
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...Depois de converter seus dados em JSON, você pode adicionar um documento JSON ao índice especificado e torná-lo pesquisável.
$ python example/index_documents.pyVá para http://127.0.0.1:5000.


