MyScaleDB
v1.8.0

Permita que cada desenvolvedor crie aplicativos GenAI de nível de produção com SQL poderoso e familiar.
MyScaleDB é o banco de dados vetorial SQL que permite aos desenvolvedores criar aplicativos de IA escalonáveis e prontos para produção usando SQL familiar. Ele é construído com base no ClickHouse e otimizado para aplicativos e soluções de IA, permitindo que os desenvolvedores gerenciem e processem com eficácia grandes volumes de dados.
Os principais benefícios do uso do MyScaleDB incluem:
Totalmente compatível com SQL
Pesquisa vetorial rápida, poderosa e eficiente, pesquisa filtrada e consultas de junção de vetores SQL.
Use SQL com funções relacionadas a vetores para interagir com MyScaleDB. Não há necessidade de aprender novas ferramentas ou estruturas complexas – atenha-se ao que você conhece e adora.
Pronto para produção para aplicações de IA
Uma plataforma unificada e testada ao longo do tempo para gerenciar e processar dados estruturados, dados de texto, vetoriais, JSON, geoespaciais, dados de série temporal e muito mais. Veja tipos de dados e funções compatíveis
Precisão RAG aprimorada combinando vetores com metadados avançados, pesquisa de texto completo e realizando pesquisa filtrada de alta precisão e eficiência em qualquer proporção 1 .
Desempenho e escalabilidade incomparáveis
MyScaleDB aproveita arquitetura de banco de dados OLAP de ponta e algoritmos vetoriais avançados para operações vetoriais extremamente rápidas.
Dimensione seus aplicativos de maneira fácil e econômica à medida que seus dados crescem.
MyScale Cloud fornece MyScaleDB totalmente gerenciado com recursos premium em dados em escala de bilhões 2 . Em comparação com bancos de dados vetoriais especializados que usam APIs personalizadas, o MyScale é mais poderoso, tem melhor desempenho e é mais econômico, ao mesmo tempo em que permanece mais simples de usar. Isso o torna adequado para uma grande comunidade de programadores. Além disso, quando comparado a bancos de dados vetoriais integrados como PostgreSQL com pgvector ou ElasticSearch com extensões vetoriais, o MyScale consome menos recursos e alcança melhor precisão e velocidade para consultas estruturadas e conjuntas de vetores, como pesquisas filtradas.
Totalmente compatível com SQL
Gerenciamento unificado de dados estruturados e vetorizados
Pesquisa de milissegundos em vetores em escala de bilhões
Altamente confiável e linearmente escalável
Funções poderosas de pesquisa de texto e pesquisa híbrida de texto/vetor
Consultas vetoriais SQL complexas
Observabilidade LLM com Telemetria MyScale
MyScale unifica três sistemas: banco de dados SQL/data warehouse, banco de dados vetorial, bem como mecanismo de pesquisa de texto completo em um sistema de maneira altamente eficiente. Ele não apenas economiza custos de infraestrutura e manutenção, mas também permite consultas e análises conjuntas de dados.
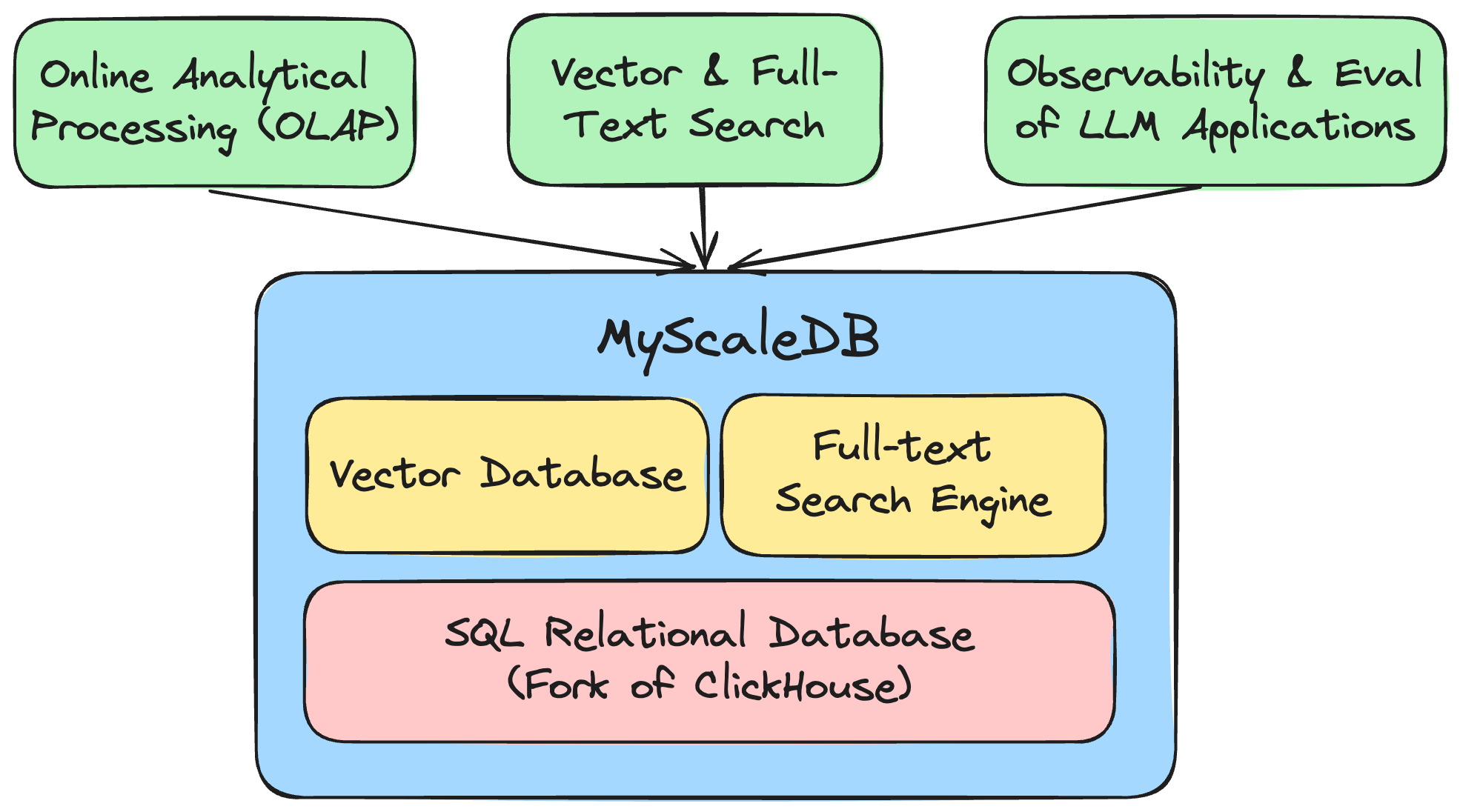
Consulte nossa documentação e blogs para saber mais sobre os recursos e vantagens exclusivos do MyScale. Nosso benchmark de código aberto fornece comparação detalhada com outros produtos de banco de dados vetoriais.
ClickHouse é um banco de dados analítico de código aberto popular que se destaca no processamento e análise de big data devido ao seu armazenamento colunar com compactação avançada, indexação de salto e processamento SIMD. Ao contrário de bancos de dados transacionais como PostgreSQL e MySQL, que usam armazenamento de linha e otimizações principais para processamento transacional, ClickHouse tem velocidades analíticas e de varredura de dados significativamente mais rápidas.
Uma das principais operações na combinação de pesquisa estruturada e vetorial é a pesquisa filtrada, que envolve filtrar primeiro por outros atributos e depois realizar a pesquisa vetorial nos dados restantes. O armazenamento colunar e a pré-filtragem são cruciais para garantir alta precisão e alto desempenho na pesquisa filtrada, e é por isso que escolhemos construir o MyScaleDB sobre o ClickHouse.
Embora tenhamos modificado o mecanismo de execução e armazenamento do ClickHouse de várias maneiras para garantir consultas de vetor SQL rápidas e econômicas, muitos dos recursos (#37893, #38048, #37859, #56728, #58223) relacionados ao processamento SQL geral foram contribuiu de volta para a comunidade de código aberto ClickHouse.
A maneira mais simples de usar MyScaleDB é criar uma instância no serviço MyScale Cloud. Você pode começar a partir de um pod gratuito com suporte para vetores 5M 768D. Inscreva-se aqui e verifique o MyScaleDB QuickStart para obter mais instruções.
Para colocar rapidamente uma instância MyScaleDB em funcionamento, basta extrair e executar a imagem mais recente do Docker:
docker run --name myscaledb --net=host myscale/myscaledb:1.8.0
Nota: A configuração padrão do Myscale permite apenas acesso IP do host local. Para o método docker run startup, você precisa especificar
--net=hostpara acessar serviços implantados no modo docker no nó atual.
Isso iniciará uma instância MyScaleDB com usuário default e sem senha. Você pode então se conectar ao banco de dados usando clickhouse-client :
docker exec -it myscaledb clickhouse-client
Use a seguinte estrutura de diretório recomendada e o local do arquivo docker-compose.yaml :
> árvore myscaledb
myscaledb
├── docker-compose.yaml
└── volumes
└── configuração
└── usuários.d
└── custom_users_config.xml
3 diretórios, 2 arquivos Defina a configuração para sua implantação. Recomendamos começar com a seguinte configuração em seu arquivo docker-compose.yaml , que você pode ajustar com base em seus requisitos específicos:
versão: '3.7'serviços: myscaledb:image: myscale/myscaledb:1.8.0tty: trueports:
- '8123:8123' - '9000:9000' - '8998:8998' - '9363:9363' - '9116:9116'redes: myscaledb_network:ipv4_address: 10.0.0.2volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/data:/var/lib/clickhouse - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/log:/var/log/clickhouse-server - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config/users.d/custom_users_config.xml:/etc/clickhouse-server/users.d/custom_users_config.xmldeploy: resources:limits: cpus: "16.00" memória: 32Gbredes: myscaledb_network: driver: bridgeipam: driver: configuração padrão:
- sub-rede: 10.0.0.0/24 custom_users_config.xml :
<clickhouse>
<usuários>
<padrão>
<senha></senha>
<redes>
<ip>::1</ip>
<ip>127.0.0.1</ip>
<ip>10.0.0.0/24</ip>
</redes>
<perfil>padrão</perfil>
<quota>padrão</quota>
<access_management>1</access_management>
</padrão>
</usuários>
</clickhouse>Nota: A configuração custom_users_config permite usar o usuário padrão para acessar o banco de dados no nó onde o serviço de banco de dados é implementado usando docker compose. Caso queira acessar o serviço de banco de dados em outros nós, é recomendado criar um usuário que possa ser acessado através de outros IPs. Para configurações detalhadas, consulte: MyScaleDB Criar usuário. Você também pode personalizar o arquivo de configuração do MyScaleDB. Copie o diretório
/etc/clickhouse-serverdo contêinermyscaledbpara a unidade local, modifique a configuração e adicione um mapeamento de diretório ao arquivodocker-compose.yamlpara que a configuração tenha efeito:- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/config:/etc/clickhouse-server
Use o seguinte comando para executá-lo:
cd myscaledb docker compor -d
Acesse a interface de linha de comando MyScaleDB usando o comando a seguir.
docker exec -it myscaledb-myscaledb-1 clickhouse-client
Agora você pode executar instruções SQL. Consulte Executando consultas SQL.
O ambiente de compilação compatível é Ubuntu 22.04 com LLVM 15.0.7.
Por favor, veja a pasta de scripts.
Exemplo de uso:
LLVM_VERSION=15 sudo -E scripts bash/install_deps.sh sudo apt-get -y instalar ferrugem carga yasm scripts bash/config_on_linux.sh scripts bash/build_on_linux.sh
Os executáveis resultantes estarão em MyScaleDB/build/programs/* .
Consulte a documentação da pesquisa vetorial para saber como criar uma tabela SQL com índice vetorial e realizar pesquisa vetorial. É recomendado especificar TYPE SCANN ao criar um índice vetorial no MyScaleDB de código aberto.
-- Crie uma tabela com body_vector de comprimento 384CREATE TABLE default.wiki_abstract (`id` UInt64,`body` String,`title` String,`url` String,`body_vector` Array(Float32),CONSTRAINT check_length CHECK length(body_vector) = 384) MOTOR = MergeTreeORDER BY id;
-- Inserir dados de arquivos parquet em S3INSERT INTO default.wiki_abstract SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_with_vector.parquet','Parquet'); -- Construa um índice vetorial SCANN com a métrica Cosine no body_vectorALTER TABLE default.wiki_abstract ADD VECTOR INDEX vec_idx body_vector TYPE SCANN('metric_type=Cosine');-- Consulte o progresso de construção do índice na tabela `vector_indices`-- Aguarde até que o o progresso do índice torna-se `Built`SELECT * FROM system.vector_indices;- Execute a pesquisa vetorial e retorne os 5 principais resultadosSELECT eu ia, título, distância (corpo_vetor, [-0,052, -0,0146, -0,0677, -0,0256, -0,0395, -0,0381, -0,025, 0,0911, -0,0429, -0,0592, 0,0017, -0,0358, -0,0464, -0,0189, -0,0192, 0,0544, -0,0022, -0,0292, -0,0474, -0,0286, 0,0746, -0,013, -0,0217, -0,0246, -0,0169, 0,0495, -0,0947, 0,0139, 0,0445, -0,0262, -0,0049, 0,0506, 0,004, 0,0276, 0,0063, -0,0643, 0,0059, -0,0229, -0,0315, 0,0549, 0,1427, 0,0079, 0,011, -0,0036, -0,0617, 0,0155, -0,0607, 0,0258, -0,0205, 0,0008, -0,0547, 0,0329, -0,0522, -0,0347, 0,0921, 0,0139, -0,013, 0,0716, -0,0165, 0,0257, -0,0071, 0,0084, -0,0653, 0,0091, 0,0544, -0,0192, -0,0169, -0,0017, -0,0304, 0,0427, -0,0389, 0,0921, -0,0622, -0,0196, 0,0025, 0,0214, 0,0259, -0,0493, -0,0211, -0,119, -0,0736, -0,1545, -0,0578, -0,0145, 0,0138, 0,0478, -0,0451, -0,0332, 0,0799, 0,0001, -0,0737, 0,0427, 0,0517, 0,0102, 0,0386, 0,0233, 0,0425, -0,0279, -0,0529, 0,0744, -0,0305, -0,026, 0,1229, -0,002, 0,0038, -0,0491, 0,0352, 0,0027, -0,056, -0,1044, 0,123, -0,0184, 0,1148, -0,0189, 0,0412, -0,0347, -0,0569, -0,0119, 0,0098, -0,0016, 0,0451, 0,0273, 0,0436, 0,0082, 0,0166, -0,0989, 0,0747, -0,0, 0,0306, -0,0717, -0,007, 0,0665, 0,0452, 0,0123, -0,0238, 0,0512, -0,0116, 0,0517, 0,0288, -0,0013, 0,0176, 0,0762, 0,1284, -0,031, 0,0891, -0,0286, 0,0132, 0,003, 0,0433, 0,0102, -0,0209, -0,0459, -0,0312, -0,0387, 0,0201, -0,027, 0,0243, 0,0713, 0,0359, -0,0674, -0,0747, -0,0147, 0,0489, -0,0092, -0,018, 0,0236, 0,0372, -0,0071, -0,0513, -0,0396, -0,0316, -0,0297, -0,0385, -0,062, 0,0465, 0,0539, -0,033, 0,0643, 0,061, 0,0062, 0,0245, 0,0868, 0,0523, -0,0253, 0,0157, 0,0266, 0,0124, 0,1382, -0,0107, 0,0835, -0,1057, -0,0188, -0,0786, 0,057, 0,0707, -0,0185, 0,0708, 0,0189, -0,0374, -0,0484, 0,0089, 0,0247, 0,0255, -0,0118, 0,0739, 0,0114, -0,0448, -0,016, -0,0836, 0,0107, 0,0067, -0,0535, -0,0186, -0,0042, 0,0582, -0,0731, -0,0593, 0,0299, 0,0004, -0,0299, 0,0128, -0,0549, 0,0493, 0,0, -0,0419, 0,0549, -0,0315, 0,1012, 0,0459, -0,0628, 0,0417, -0,0153, 0,0471, -0,0301, -0,0615, 0,0137, -0,0219, 0,0735, 0,083, 0,0114, -0,0326, -0,0272, 0,0642, -0,0203, 0,0557, -0,0579, 0,0883, 0,0719, 0,0007, 0,0598, -0,0431, -0,0189, -0,0593, -0,0334, 0,02, -0,0371, -0,0441, 0,0407, -0,0805, 0,0058, 0,1039, 0,0534, 0,0495, -0,0325, 0,0782, -0,0403, 0,0108, -0,0068, -0,0525, 0,0801, 0,0256, -0,0183, -0,0619, -0,0063, -0,0605, 0,0377, -0,0281, -0,0097, -0,0029, -0,106, 0,0465, -0,0033, -0,0308, 0,0357, 0,0156, -0,0406, -0,0308, 0,0013, 0,0458, 0,0231, 0,0207, -0,0828, -0,0573, 0,0298, -0,0381, 0,0935, -0,0498, -0,0979, -0,1452, 0,0835, -0,0973, -0,0172, 0,0003, 0,09, -0,0931, -0,0252, 0,008, -0,0441, -0,0938, -0,0021, 0,0885, 0,0088, 0,0034, -0,0049, 0,0217, 0,0584, -0,012, 0,059, 0,0146, -0,0, -0,0045, 0,0663, 0,0017, 0,0015, 0,0569, -0,0089, -0,0232, 0,0065, 0,0204, -0,0253, 0,1119, -0,036, 0,0125, 0,0531, 0,0584, -0,0101, -0,0593, -0,0577, -0,0656, -0,0396, 0,0525, -0,006, -0,0149, 0,003, -0,1009, -0,0281, 0,0311, -0,0088, 0,0441, -0,0056, 0,0715, 0,051, 0,0219, -0,0028, 0,0294, -0,0969, -0,0852, 0,0304, 0,0374, 0,1078, -0,0559, 0,0805, -0,0464, 0,0369, 0,0874, -0,0251, 0,0075, -0,0502, -0,0181, -0,1059, 0,0111, 0,0894, 0,0021, 0,0838, 0,0497, -0,0183, 0,0246, -0,004, -0,0828, 0,06, -0,1161, -0,0367, 0,0475, 0,0317]) AS distânciaFROM default.wiki_abstractORDER BY distância ASCLIMIT 5;
Estamos comprometidos em melhorar e evoluir continuamente o MyScaleDB para atender às necessidades em constante mudança da indústria de IA. Junte-se a nós nesta jornada emocionante e faça parte da revolução no gerenciamento de dados de IA!
Discórdia
Apoiar
Receba as últimas notícias ou atualizações do MyScaleDB
Siga @MyScaleDB no Twitter
Siga @MyScale no LinkedIn
Leia o blog MyScale
Índice invertido e pesquisa híbrida de palavra-chave/vetor de alto desempenho (suportado desde 1.5)
Suporta mais mecanismos de armazenamento, por exemplo, ReplacingMergeTree (suportado desde 1.6)
Observabilidade LLM com MyScaleDB e MyScale Telemetry
LLM centrado em dados
Ciência de dados automática com MyScaleDB
MyScaleDB é licenciado sob a licença Apache, versão 2.0. Veja uma cópia do arquivo de licença.
Damos agradecimentos especiais por estes projetos de código aberto, sobre os quais desenvolvemos o MyScaleDB:
ClickHouse – Um SGBD analítico gratuito para big data.
Faiss - Uma biblioteca para busca eficiente de similaridade e agrupamento de vetores densos, da Meta's Fundamental AI Research.
hnswlib - Biblioteca C++/python somente de cabeçalho para vizinhos mais próximos aproximados rapidamente.
ScaNN - biblioteca escalável de vizinhos mais próximos do Google Research.
Tantivy - Uma biblioteca de mecanismo de busca de texto completo inspirada no Apache Lucene e escrita em Rust.
Veja aqui por que a filtragem de metadados é crucial para melhorar a precisão do RAG. ↩
O algoritmo MSTG (Multi-scale Tree Graph) é fornecido através do MyScale Cloud, alcançando alta densidade de dados com armazenamento baseado em disco e melhor desempenho de indexação e pesquisa em dados vetoriais em escala de bilhões. ↩


