Este código foi construído sobre um modelo de aprendizagem profunda de imagem para BEV pré-existente, baseado no artigo Traduzindo imagens em mapas. Este código foi escrito usando python 3.7. e foi treinado no conjunto de dados nuScenes. Consulte o ReadMe do repositório para dependências e conjuntos de dados a serem instalados.
O primeiro passo é criar uma pasta chamada “translating-images-into-maps-main” e baixar todos os arquivos nela. Então, devido ao grande tamanho do arquivo, os pontos de verificação mais recentes do nosso treinamento e o conjunto de dados mini nuScenes usado para validação podem ser baixados deste Google Drive. Essas pastas devem ser adicionadas diretamente no diretório "translating-images-into-maps-main".
Abaixo está a lista de bibliotecas necessárias para este repositório:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
Para usar as funções deste repositório, os seguintes argumentos de linha de comando podem precisar ser alterados:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
Quanto ao treinamento do modelo, estes argumentos de linha de comando podem ser modificados:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
Os conjuntos de dados NuScenes Mini e Full podem ser encontrados nos seguintes locais:
NuSceneMini:
NuScenes completo dos EUA:
Como os conjuntos de dados mini e completo do NuScene não possuem o mesmo formato de entrada de imagem (lmdb ou png), algumas modificações precisam ser aplicadas no código para usar um ou outro:
mini argumento para false para usar o mini conjunto de dados, bem como os caminhos e divisões de argumentos nos arquivos train.py , validation.py e inference.py . data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')Os pontos de verificação pré-treinados podem ser encontrados aqui:
Os pontos de verificação precisam ser mantidos em /pretrained_models/27_04_23_11_08 do diretório raiz deste repositório. Caso queira carregá-los de outro diretório, altere os seguintes argumentos:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"Para treinar no scitas, você precisa iniciar o seguinte script no diretório raiz:
sbatch job.script.sh
Para treinar localmente na CPU:
python3 train.py
Certifique-se de adaptar o script com seus argumentos de linha de comando.
Para validar o desempenho de um modelo no scitas:
sbatch job.validate.sh
Para treinar localmente na CPU:
python3 validate.py
Certifique-se de adaptar o script com seus argumentos de linha de comando.
Para inferir sobre um vídeo no scitas:
sbatch job.evaluate.sh
Para treinar localmente na CPU:
python3 inference.py
Certifique-se de adaptar o script com seus argumentos de linha de comando, especialmente:
--batch-size // 1 for the test videos
--video-name
--video-root
Este projeto foi realizado no contexto do curso Deep Learning for Autonomous Vehicles CIVIL-459, ministrado pelo professor Alexandre Alahi na EPFL. Fomos supervisionados pelo estudante de doutorado Yuejiang Liu. O principal objetivo do projeto do curso é desenvolver um modelo de aprendizagem profunda que possa ser utilizado a bordo de um sistema de piloto automático Tesla. Quanto ao nosso grupo, temos estudado a transformação de imagens de câmeras monoculares para vistas aéreas. Isso pode ser feito usando segmentação semântica para classificar elementos como carros, calçada, pedestres e horizonte.
Durante nossa pesquisa sobre imagens monoculares para modelos de aprendizagem profunda BEV, notamos que as informações relativas aos pedestres foram perdidas durante a segmentação, resultando em uma classificação ruim. Conforme pode ser visto na imagem abaixo, quando avaliado, o modelo que selecionamos atinge uma média de 25,7% IoU (Intersection over Union) em 14 classes de objetos no conjunto de dados nuScenes. A precisão da previsão para veículos dirigíveis é boa (74,5%), bastante fraca para bicicletas, barreiras e reboques. No entanto, a precisão da previsão para os peões (9,5%) é demasiado baixa. Uma precisão tão baixa poderia causar acidentes se alguém atravessasse a rua sem estar no cruzamento.

Mais informações sobre nossa pesquisa podem ser encontradas no Drive.
Como a má detecção de pedestres parecia ser o problema mais imediato do modelo treinado atual, nosso objetivo era melhorar a precisão examinando funções de perda mais adequadas e treinando o novo modelo no conjunto de dados nuScenes.
O modelo que construímos foi treinado usando um
Outro problema com
O
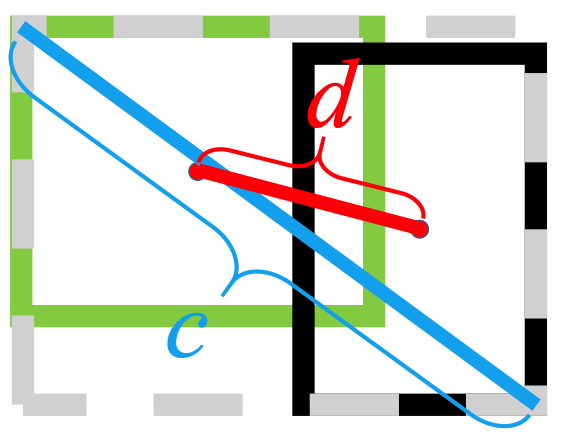
Ele usa a norma L2 para minimizar a distância entre as caixas previstas e alvo, e converge muito mais rápido do que

Alongamento horizontal

Alongamento Vertical
Além disso, a perda DIoU introduz um termo de regularização que incentiva uma convergência suave.
Como pode ser visto na imagem a seguir, o
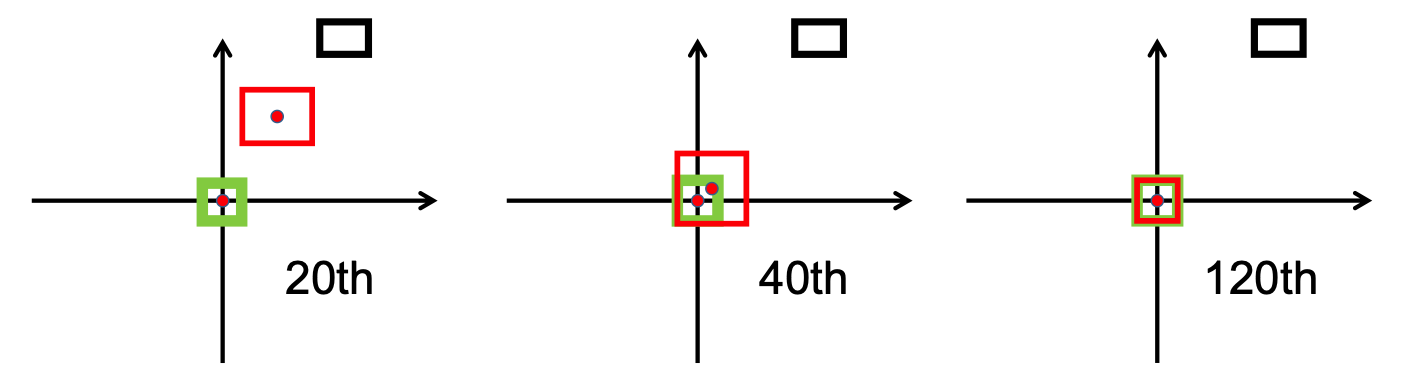
Após a fase de pesquisa, implementamos o bbox_overlaps_diou no arquivo /src/utils.py , usando o
Esta função é então usada para calcular multiescala compute_multiscale_iou do mesmo arquivo. Para cada aula, o iou ) é calculado sobre o tamanho do lote. A saída da função é um dicionário iou_dict contendo o multiescala
Em seguida, usamos esses valores em train.py , onde o val-interval . Esses valores também foram usados em validation.py onde foram usados para exibir as perdas e
Treinamos o modelo no conjunto de dados NuScenes começando com o checkpoint-008.pth.gz , uma vez com o
Outra contribuição é o novo formato de visualização para distinguir melhor as classes com todos os rótulos e valores de IoU correspondentes. Isso foi implementado no arquivo visualization.py .
Por último, trabalhamos para implementar um modo que receberia vídeos .mp4 como entrada e os decomporia em quadros de imagem individuais. Estes seriam então avaliados pelo modelo e poderíamos visualizar o resultado da segmentação no arquivo inference.py .
Para ter uma ideia preliminar da estratégia de treinamento deste modelo, decidimos primeiro treiná-lo nos miniconjuntos de dados NuScenes. A partir de checkpoint-008.pth.gz , conseguimos treinar dois modelos diferentes na métrica IoU usada (IoU para um e DIoU para o outro). Os resultados obtidos em um minilote NuScenes após 10 épocas de treinamento são apresentados na tabela abaixo.

Após a análise desses resultados, observamos que a classe de pedestres, na qual baseamos nossa hipótese, não apresentou nenhum resultado conclusivo. Concluímos, portanto, que o minidataset não era suficiente para as nossas necessidades e decidimos migrar nosso treinamento para o conjunto de dados completo no Scitas.
Após treinar nossos novos modelos (com DIoU ou IoU) do checkpoint-008.pth.gz por 8 novas épocas, observamos resultados promissores. Com o objetivo de comparar o desempenho desses modelos recém-treinados, realizamos uma etapa de validação no miniconjunto de dados. Uma visualização do resultado para uma imagem deste conjunto de dados é fornecida abaixo.
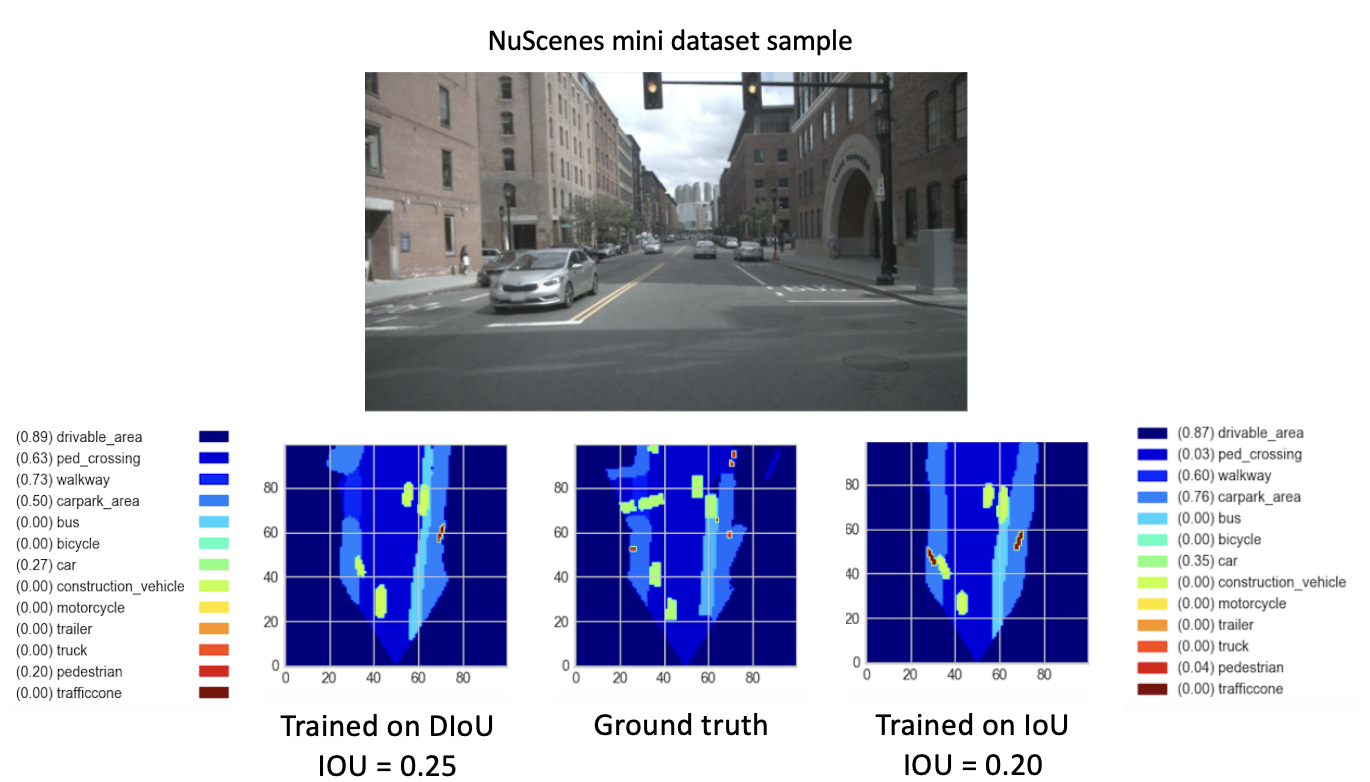
Aqui, o

Estes resultados finalmente mostram um melhor desempenho do
Agora que temos um modelo treinado, podemos usá-lo para prever o BEV usando quaisquer imagens ou vídeos de entrada. Embora nossa ambição fosse implementar nosso método na demonstração final do curso, os mapas de visão aérea inferidos infelizmente não tiveram desempenho suficiente. A figura abaixo mostra o resultado da inferência em um dos vídeos de teste fornecidos (ver vídeos de teste).

Acreditamos que esta falta de desempenho para a inferência se deve aos seguintes parâmetros:
Embora a passagem de
Uma opção é implementar
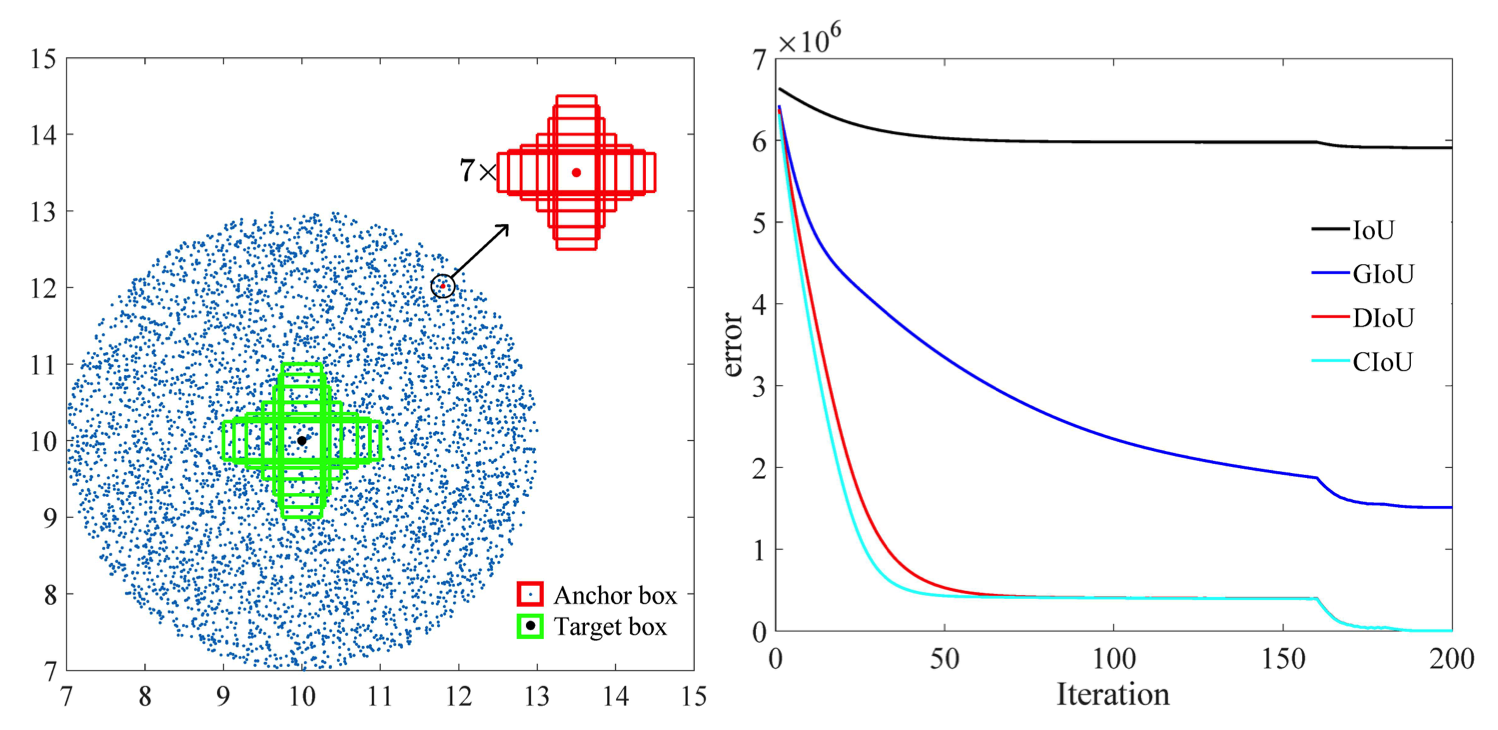
O
Além disso, de acordo com a pesquisa feita por este artigo [2], o erro de regressão para CIoU se degrada mais rapidamente do que o resto e convergirá para
Outra opção é treinar em conjuntos de dados ricos em ambientes lotados para ter uma melhor representação de pedestres e bicicletas.
Finalmente, para realmente validar nossa hipótese, uma validação no conjunto de dados completo do NuScenes poderia ser conduzida e as IoUs de pedestres dos dois modelos poderiam ser comparadas.
[1] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren (2020). Perda de IoU à distância: aprendizado melhor e mais rápido para regressão de caixa delimitadora https://arxiv.org/pdf/1911.08287.pdf
[2] Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo (2021). Aprimorando fatores geométricos no aprendizado e inferência de modelos para detecção de objetos e segmentação de instâncias https://arxiv.org/pdf/2005.03572.pdf


