tiny cuda nn
Version 1.6
Esta é uma estrutura pequena e independente para treinar e consultar redes neurais. Mais notavelmente, ele contém um perceptron multicamadas "totalmente fundido" extremamente rápido (artigo técnico), uma codificação hash multirresolução versátil (artigo técnico), bem como suporte para várias outras codificações de entrada, perdas e otimizadores.
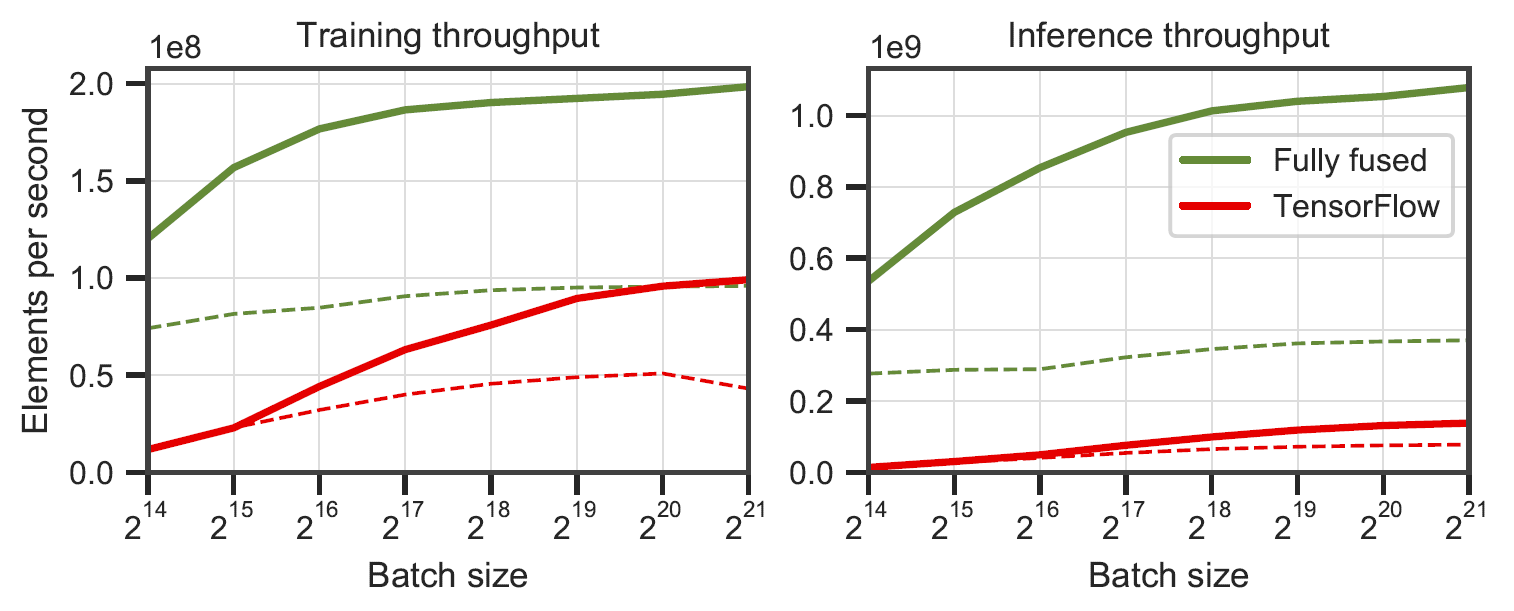 Redes totalmente fundidas vs. TensorFlow v2.5.0 com XLA. Medido em perceptrons multicamadas de largura de 64 (linha sólida) e 128 (linha tracejada) neurônios em um RTX 3090. Gerado por
Redes totalmente fundidas vs. TensorFlow v2.5.0 com XLA. Medido em perceptrons multicamadas de largura de 64 (linha sólida) e 128 (linha tracejada) neurônios em um RTX 3090. Gerado por benchmarks/bench_ours.cu e benchmarks/bench_tensorflow.py usando data/config_oneblob.json .
Redes neurais minúsculas CUDA têm uma API C++/CUDA simples:
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);Fornecemos um aplicativo de exemplo onde uma função de imagem (x,y) -> (R,G,B) é aprendida. Pode ser executado através
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.jsonproduzindo uma imagem a cada duas etapas de treinamento. Cada 1.000 etapas deve levar um pouco mais de 1 segundo com a configuração padrão em um RTX 4090.
| 10 passos | 100 passos | 1000 passos | Imagem de referência |
|---|---|---|---|
 |  |  |  |
n_neurons ou usar o CutlassMLP (melhor compatibilidade, mas mais lento).Se você estiver usando Linux, instale os seguintes pacotes
sudo apt-get install build-essential git Também recomendamos instalar o CUDA em /usr/local/ e adicionar a instalação do CUDA ao seu PATH. Por exemplo, se você tiver CUDA 11.4, adicione o seguinte ao seu ~/.bashrc
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " Comece clonando este repositório e todos os seus submódulos usando o seguinte comando:
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nnEm seguida, use o CMake para construir o projeto: (no Windows, isso deve estar em um prompt de comando do desenvolvedor)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j Se a compilação falhar inexplicavelmente ou demorar mais de uma hora, você poderá estar ficando sem memória. Tente executar o comando acima sem -j nesse caso.
tiny-cuda-nn vem com uma extensão PyTorch que permite usar MLPs rápidos e codificações de entrada de dentro de um contexto Python. Essas ligações podem ser significativamente mais rápidas do que implementações completas do Python; em particular para a codificação hash multiresolução.
Mesmo assim, as despesas gerais do Python/PyTorch podem ser extensas se o tamanho do lote for pequeno. Por exemplo, com um tamanho de lote de 64k, o exemplo
mlp_learning_an_imageincluído é cerca de 2x mais lento por meio do PyTorch do que o CUDA nativo. Com um tamanho de lote de 256k e superior (padrão), o desempenho é muito mais próximo.
Comece configurando um ambiente Python 3.X com uma versão recente do PyTorch habilitada para CUDA. Então, invoque
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torchAlternativamente, se você quiser instalar a partir de um clone local de tiny-cuda-nn , invoque
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py installApós o sucesso, você pode usar modelos tiny-cuda-nn como no exemplo a seguir:
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) Consulte samples/mlp_learning_an_image_pytorch.py para obter um exemplo.
A seguir está um resumo dos componentes desta estrutura. A documentação JSON lista opções de configuração.
| Redes | ||
|---|---|---|
| MLP totalmente fundido | src/fully_fused_mlp.cu | Implementação extremamente rápida de pequenos perceptrons multicamadas (MLPs). |
| MLP DE CORTE | src/cutlass_mlp.cu | MLP baseado nas rotinas GEMM do CUTLASS. Mais lento que o totalmente fundido, mas lida com redes maiores e ainda é razoavelmente rápido. |
| Codificações de entrada | ||
|---|---|---|
| Composto | include/tiny-cuda-nn/encodings/composite.h | Permite compor múltiplas codificações. Pode ser, por exemplo, usado para montar a codificação Neural Radiance Caching [Müller et al. 2021]. |
| Freqüência | include/tiny-cuda-nn/encodings/frequency.h | NeRF [Mildenhall et al. 2020] codificação posicional aplicada igualmente a todas as dimensões. |
| Grade | include/tiny-cuda-nn/encodings/grid.h | Codificação baseada em grades multirresolução treináveis. Usado para primitivos gráficos neurais instantâneos [Müller et al. 2022]. As grades podem ser apoiadas por hashtables, armazenamento denso ou armazenamento lado a lado. |
| Identidade | include/tiny-cuda-nn/encodings/identity.h | Deixa os valores intocados. |
| Uma gota | include/tiny-cuda-nn/encodings/oneblob.h | Da amostragem de importância neural [Müller et al. 2019] e Variáveis de Controle Neural [Müller et al. 2020]. |
| Harmônicos Esféricos | include/tiny-cuda-nn/encodings/spherical_harmonics.h | Uma codificação de espaço de frequência que é mais adequada para vetores de direção do que para vetores de componentes. |
| TriânguloOnda | include/tiny-cuda-nn/encodings/triangle_wave.h | Alternativa de baixo custo à codificação NeRF. Usado em cache de radiação neural [Müller et al. 2021]. |
| Perdas | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | Perda L1 padrão. |
| Relativo L1 | include/tiny-cuda-nn/losses/l1.h | Perda relativa de L1 normalizada pela previsão da rede. |
| MAPE | include/tiny-cuda-nn/losses/mape.h | Erro percentual médio absoluto (MAPE). O mesmo que Relativo L1, mas normalizado pelo alvo. |
| SMPE | include/tiny-cuda-nn/losses/smape.h | Erro percentual absoluto médio simétrico (SMAPE). O mesmo que Relativo L1, mas normalizado pela média da previsão e do alvo. |
| L2 | include/tiny-cuda-nn/losses/l2.h | Perda L2 padrão. |
| L2 relativo | include/tiny-cuda-nn/losses/relative_l2.h | Perda relativa de L2 normalizada pela previsão da rede [Lehtinen et al. 2018]. |
| Luminância relativa L2 | include/tiny-cuda-nn/losses/relative_l2_luminance.h | O mesmo que acima, mas normalizado pela luminância da previsão da rede. Aplicável apenas quando a previsão da rede é RGB. Usado em cache de radiação neural [Müller et al. 2021]. |
| Entropia Cruzada | include/tiny-cuda-nn/losses/cross_entropy.h | Perda de entropia cruzada padrão. Aplicável apenas quando a previsão da rede é um PDF. |
| Variância | include/tiny-cuda-nn/losses/variance_is.h | Perda de variação padrão. Aplicável apenas quando a previsão da rede é um PDF. |
| Otimizadores | ||
|---|---|---|
| Adão | include/tiny-cuda-nn/optimizers/adam.h | Implementação de Adam [Kingma e Ba 2014], generalizado para AdaBound [Luo et al. 2019]. |
| Novogrado | include/tiny-cuda-nn/optimizers/lookahead.h | Implementação de Novogrado [Ginsburg et al. 2019]. |
| SGD | include/tiny-cuda-nn/optimizers/sgd.h | Descida gradiente estocástica padrão (SGD). |
| Xampu | include/tiny-cuda-nn/optimizers/shampoo.h | Implementação do otimizador Shampoo de 2ª ordem [Gupta et al. 2018] com otimizações caseiras, bem como aquelas de Anil et al. [2020]. |
| Média | include/tiny-cuda-nn/optimizers/average.h | Envolve outro otimizador e calcula uma média linear dos pesos nas últimas N iterações. A média é usada apenas para inferência (não retroalimenta o treinamento). |
| Em lote | include/tiny-cuda-nn/optimizers/batched.h | Envolve outro otimizador, invocando o otimizador aninhado uma vez a cada N etapas no gradiente médio. Tem o mesmo efeito que aumentar o tamanho do lote, mas requer apenas uma quantidade constante de memória. |
| Composto | include/tiny-cuda-nn/optimizers/composite.h | Permite usar vários otimizadores em diferentes parâmetros. |
| EMA | include/tiny-cuda-nn/optimizers/average.h | Envolve outro otimizador e calcula uma média móvel exponencial dos pesos. A média é usada apenas para inferência (não retroalimenta o treinamento). |
| Decadência Exponencial | include/tiny-cuda-nn/optimizers/exponential_decay.h | Envolve outro otimizador e executa decaimento da taxa de aprendizado exponencial constante por partes. |
| Antecipar | include/tiny-cuda-nn/optimizers/lookahead.h | Envolve outro otimizador, implementando o algoritmo lookahead [Zhang et al. 2019]. |
Esta estrutura está licenciada sob a licença BSD de 3 cláusulas. Consulte LICENSE.txt para obter detalhes.
Se você usá-lo em sua pesquisa, agradeceríamos uma citação via
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}Para consultas comerciais, visite nosso site e envie o formulário: NVIDIA Research Licensing
Entre outras, esta estrutura alimenta as seguintes publicações:
Primitivos gráficos neurais instantâneos com codificação hash multiresolução
Thomas Müller, Alex Evans, Christoph Schied, Alexander Keller
Transações ACM em gráficos ( SIGGRAPH ), julho de 2022
Site / Artigo / Código / Vídeo / BibTeX
Extraindo modelos 3D triangulares, materiais e iluminação de imagens
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler
CVPR (Oral) , junho de 2022
Site / Artigo / Vídeo / BibTeX
Cache de radiação neural em tempo real para rastreamento de caminho
Thomas Müller, Fabrice Rousselle, Jan Novák, Alexander Keller
Transações ACM em gráficos ( SIGGRAPH ), agosto de 2021
Artigo / Palestra GTC / Vídeo / Visualizador de resultados interativo / BibTeX
Bem como os seguintes softwares:
NerfAcc: uma caixa de ferramentas geral de aceleração NeRF
Ruilong Li, Matthew Tancik, Angjoo Kanazawa
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio: uma estrutura para desenvolvimento de campo de radiação neural
Matthew Tancik*, Ethan Weber*, Evonne Ng*, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, Angjoo Kanazawa
https://github.com/nerfstudio-project/nerfstudio
Sinta-se à vontade para fazer uma solicitação pull se sua publicação ou software não estiver listado.
Agradecimentos especiais aos autores do NRC pelas discussões úteis e a Nikolaus Binder por fornecer parte da infraestrutura desta estrutura, bem como pela ajuda na utilização do TensorCores dentro do CUDA.


