DALLE2 pytorch
1.15.6
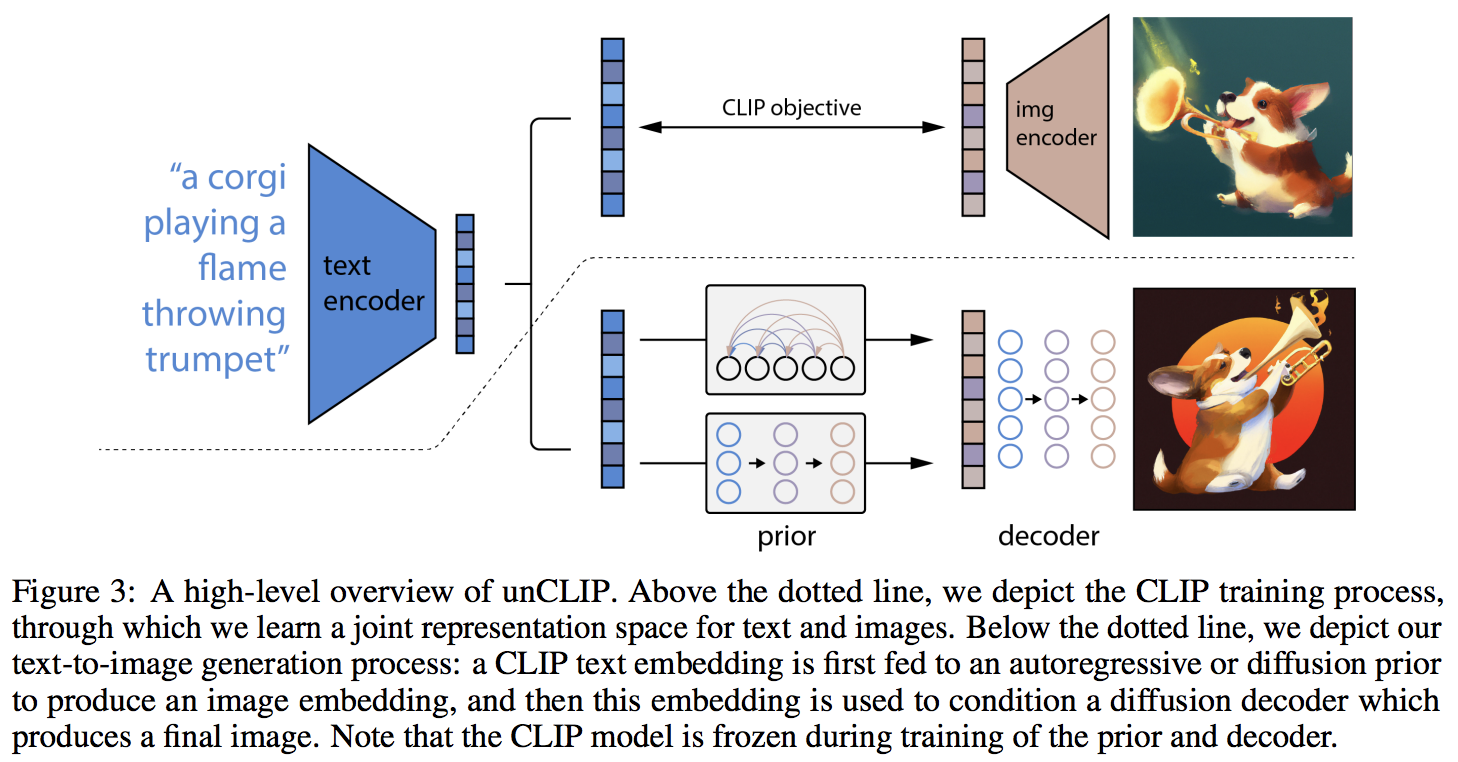
Implementação de DALL-E 2, rede neural de síntese de texto para imagem atualizada da OpenAI, em Pytorch.
Resumo de Yannic Kilcher | Explicador AssemblyAI
A principal novidade parece ser uma camada extra de indireção com a rede anterior (seja um transformador autorregressivo ou uma rede de difusão), que prevê uma incorporação de imagem baseada na incorporação de texto do CLIP. Especificamente, este repositório construirá apenas a rede de difusão anterior, pois é a variante de melhor desempenho (mas que, aliás, envolve um transformador causal como a rede de eliminação de ruído?)
Este modelo é SOTA para texto para imagem por enquanto.
Participe se estiver interessado em ajudar na replicação com a comunidade LAION | Entrevista com Yannic
A partir de 23/05/22, não é mais SOTA. SOTA estará aqui. As versões Jax, bem como o projeto de texto para vídeo, serão transferidos para a arquitetura Imagen, por ser muito mais simples.
Um grupo de pesquisa usou o código deste repositório para treinar uma difusão funcional antes de suas gerações CLIP. Compartilharão seu trabalho assim que lançarem sua pré-impressão. Isso, e os próprios experimentos de Katherine, validam a descoberta da OpenAI de que o anterior adicional aumenta o número de gerações.
O decodificador agora está funcionando para geração incondicional em minha configuração experimental para flores Oxford. Dois pesquisadores também confirmaram que o Decoder está funcionando para eles.

em andamento em 21k passos
Justin Pinkney treinou com sucesso a difusão antes no repositório para seu aplicativo de texto para imagem CLIP to Stylegan2
Romain ampliou o treinamento para 800 GPUs com os scripts disponíveis sem problemas
Esta biblioteca não teria chegado a este estado de funcionamento sem a ajuda de
... e muitos outros. Obrigado!
$ pip install dalle2-pytorchTreinar o DALLE-2 é um processo de 3 etapas, sendo o treinamento do CLIP o mais importante
Para treinar o CLIP, você pode usar o pacote x-clip ou ingressar no discord LAION, onde muitos esforços de replicação já estão em andamento.
Este repositório demonstrará a integração com x-clip para iniciantes
import torch
from dalle2_pytorch import CLIP
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 1 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 1 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
use_all_token_embeds = True , # whether to use fine-grained contrastive learning (FILIP)
decoupled_contrastive_learning = True , # use decoupled contrastive learning (DCL) objective function, removing positive pairs from the denominator of the InfoNCE loss (CLOOB + DCL)
extra_latent_projection = True , # whether to use separate projections for text-to-image vs image-to-text comparisons (CLOOB)
use_visual_ssl = True , # whether to do self supervised learning on images
visual_ssl_type = 'simclr' , # can be either 'simclr' or 'simsiam', depending on using DeCLIP or SLIP
use_mlm = False , # use masked language learning (MLM) on text (DeCLIP)
text_ssl_loss_weight = 0.05 , # weight for text MLM loss
image_ssl_loss_weight = 0.05 # weight for image self-supervised learning loss
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train
loss = clip (
text ,
images ,
return_loss = True # needs to be set to True to return contrastive loss
)
loss . backward ()
# do the above with as many texts and images as possible in a loopEm seguida, você precisará treinar o decodificador, que aprende a gerar imagens com base na incorporação de imagens provenientes do CLIP treinado acima
import torch
from dalle2_pytorch import Unet , Decoder , CLIP
# trained clip from step 1
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 1 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 1 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# unet for the decoder
unet = Unet (
dim = 128 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 )
). cuda ()
# decoder, which contains the unet and clip
decoder = Decoder (
unet = unet ,
clip = clip ,
timesteps = 100 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
# mock images (get a lot of this)
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into decoder
loss = decoder ( images )
loss . backward ()
# do the above for many many many many steps
# then it will learn to generate images based on the CLIP image embeddingsPor fim, a principal contribuição do artigo. O repositório oferece a rede anterior de difusão. Ele pega os embeddings de texto CLIP e tenta gerar os embeddings de imagem CLIP. Novamente, você precisará do CLIP treinado desde a primeira etapa
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior , CLIP
# get trained CLIP from step one
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
). cuda ()
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed text and images into diffusion prior network
loss = diffusion_prior ( text , images )
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddingsNo artigo, eles usaram uma técnica recentemente descoberta, do próprio Jonathan Ho (autor original de DDPMs, a técnica central usada no DALL-E v2) para síntese de imagens de alta resolução.
Isso pode ser facilmente usado dentro desta estrutura, assim
import torch
from dalle2_pytorch import Unet , Decoder , CLIP
# trained clip from step 1
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# 2 unets for the decoder (a la cascading DDPM)
unet1 = Unet (
dim = 32 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 )
). cuda ()
unet2 = Unet (
dim = 32 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
# decoder, which contains the unet(s) and clip
decoder = Decoder (
clip = clip ,
unet = ( unet1 , unet2 ), # insert both unets in order of low resolution to highest resolution (you can have as many stages as you want here)
image_sizes = ( 256 , 512 ), # resolutions, 256 for first unet, 512 for second. these must be unique and in ascending order (matches with the unets passed in)
timesteps = 1000 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
# mock images (get a lot of this)
images = torch . randn ( 4 , 3 , 512 , 512 ). cuda ()
# feed images into decoder, specifying which unet you want to train
# each unet can be trained separately, which is one of the benefits of the cascading DDPM scheme
loss = decoder ( images , unet_number = 1 )
loss . backward ()
loss = decoder ( images , unet_number = 2 )
loss . backward ()
# do the above for many steps for both unets Finalmente, para gerar as imagens DALL-E2 a partir do texto. Insira o DiffusionPrior treinado, bem como o Decoder (que envolve CLIP , o transformador causal e unet(s))
from dalle2_pytorch import DALLE2
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
# send the text as a string if you want to use the simple tokenizer from DALLE v1
# or you can do it as token ids, if you have your own tokenizer
texts = [ 'glistening morning dew on a flower petal' ]
images = dalle2 ( texts ) # (1, 3, 256, 256)É isso!
Vamos ver o script completo abaixo
import torch
from dalle2_pytorch import DALLE2 , DiffusionPriorNetwork , DiffusionPrior , Unet , Decoder , CLIP
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train
loss = clip (
text ,
images ,
return_loss = True
)
loss . backward ()
# do above for many steps ...
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 1000 ,
sample_timesteps = 64 ,
cond_drop_prob = 0.2
). cuda ()
loss = diffusion_prior ( text , images )
loss . backward ()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet (
dim = 128 ,
image_embed_dim = 512 ,
text_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
cond_on_text_encodings = True # set to True for any unets that need to be conditioned on text encodings
). cuda ()
unet2 = Unet (
dim = 16 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
decoder = Decoder (
unet = ( unet1 , unet2 ),
image_sizes = ( 128 , 256 ),
clip = clip ,
timesteps = 100 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
for unet_number in ( 1 , 2 ):
loss = decoder ( images , text = text , unet_number = unet_number ) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss . backward ()
# do above for many steps
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
images = dalle2 (
[ 'cute puppy chasing after a squirrel' ],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)Tudo neste leia-me deve ser executado sem erros
Você também pode treinar o decodificador em imagens maiores que o tamanho (digamos 512x512) no qual o CLIP foi treinado (256x256). As imagens serão redimensionadas para a resolução de imagem CLIP para os embeddings de imagens
Para o leigo, não se preocupe, o treinamento será todo automatizado em uma ferramenta CLI, pelo menos para treinamentos em pequena escala.
É provável que, ao aumentar a escala, você primeiro pré-processe suas imagens e texto em incorporações correspondentes antes de treinar a rede anterior. Você pode fazer isso facilmente simplesmente passando image_embed , text_embed e, opcionalmente, text_encodings
Exemplo de trabalho abaixo
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior , CLIP
# get trained CLIP from step one
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
). cuda ()
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2 ,
condition_on_text_encodings = False # this probably should be true, but just to get Laion started
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# precompute the text and image embeddings
# here using the diffusion prior class, but could be done with CLIP alone
clip_image_embeds = diffusion_prior . clip . embed_image ( images ). image_embed
clip_text_embeds = diffusion_prior . clip . embed_text ( text ). text_embed
# feed text and images into diffusion prior network
loss = diffusion_prior (
text_embed = clip_text_embeds ,
image_embed = clip_image_embeds
)
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddings Você também pode ficar completamente sem CLIP ; nesse caso, você precisará passar image_embed_dim para DiffusionPrior na inicialização
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
image_embed_dim = 512 , # this needs to be set
timesteps = 100 ,
cond_drop_prob = 0.2 ,
condition_on_text_encodings = False # this probably should be true, but just to get Laion started
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# precompute the text and image embeddings
# here using the diffusion prior class, but could be done with CLIP alone
clip_image_embeds = torch . randn ( 4 , 512 ). cuda ()
clip_text_embeds = torch . randn ( 4 , 512 ). cuda ()
# feed text and images into diffusion prior network
loss = diffusion_prior (
text_embed = clip_text_embeds ,
image_embed = clip_image_embeds
)
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddings Embora exista a possibilidade de eles estarem usando um CLIP inédito e mais poderoso, você pode usar um dos lançados, se não quiser treinar seu próprio CLIP do zero. Isto também permitirá que a comunidade valide mais rapidamente as conclusões do artigo.
Para usar um OpenAI CLIP pré-treinado, basta importar OpenAIClipAdapter e passá-lo para o DiffusionPrior ou Decoder assim
import torch
from dalle2_pytorch import DALLE2 , DiffusionPriorNetwork , DiffusionPrior , Unet , Decoder , OpenAIClipAdapter
# openai pretrained clip - defaults to ViT-B/32
clip = OpenAIClipAdapter ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2
). cuda ()
loss = diffusion_prior ( text , images )
loss . backward ()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet (
dim = 128 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
text_embed_dim = 512 ,
cond_on_text_encodings = True # set to True for any unets that need to be conditioned on text encodings (ex. first unet in cascade)
). cuda ()
unet2 = Unet (
dim = 16 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
decoder = Decoder (
unet = ( unet1 , unet2 ),
image_sizes = ( 128 , 256 ),
clip = clip ,
timesteps = 1000 ,
sample_timesteps = ( 250 , 27 ),
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
for unet_number in ( 1 , 2 ):
loss = decoder ( images , text = text , unet_number = unet_number ) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss . backward ()
# do above for many steps
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
images = dalle2 (
[ 'a butterfly trying to escape a tornado' ],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)Alternativamente, você também pode usar Open Clip
$ pip install open-clip-torchEx. usando o modelo SOTA Open Clip treinado por Romain


