

Novo robô na cidade: SO-100

Acabamos de adicionar um novo tutorial sobre como construir um robô mais acessível, ao preço de US$ 110 por braço!
Ensine novas habilidades mostrando alguns movimentos com apenas um laptop.
Então observe seu robô caseiro agir de forma autônoma?
Siga o link para o tutorial completo do SO-100.
LeRobot: IA de última geração para robótica do mundo real
? LeRobot tem como objetivo fornecer modelos, conjuntos de dados e ferramentas para robótica do mundo real em PyTorch. O objetivo é diminuir a barreira de entrada na robótica para que todos possam contribuir e se beneficiar do compartilhamento de conjuntos de dados e modelos pré-treinados.
? LeRobot contém abordagens de última geração que demonstraram ser transferidas para o mundo real, com foco na aprendizagem por imitação e na aprendizagem por reforço.
? LeRobot já fornece um conjunto de modelos pré-treinados, conjuntos de dados com demonstrações coletadas por humanos e ambientes de simulação para começar sem montar um robô. Nas próximas semanas, o plano é adicionar cada vez mais suporte para a robótica do mundo real nos robôs mais acessíveis e capazes que existem.
? LeRobot hospeda modelos e conjuntos de dados pré-treinados nesta página da comunidade Hugging Face: huggingface.co/lerobot
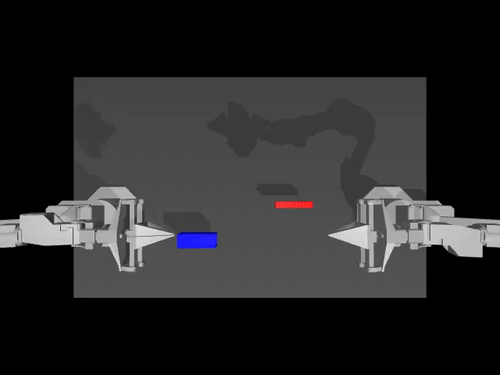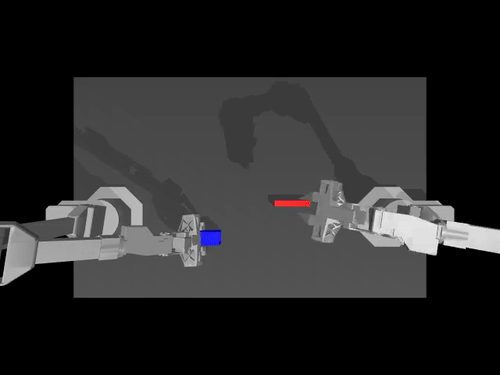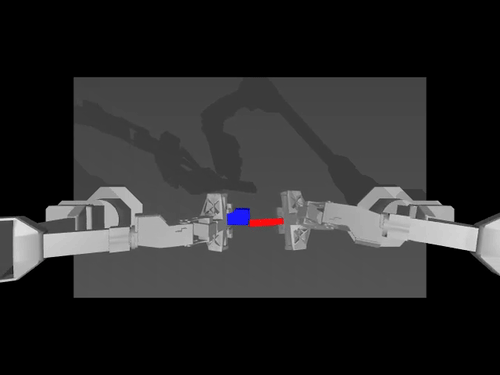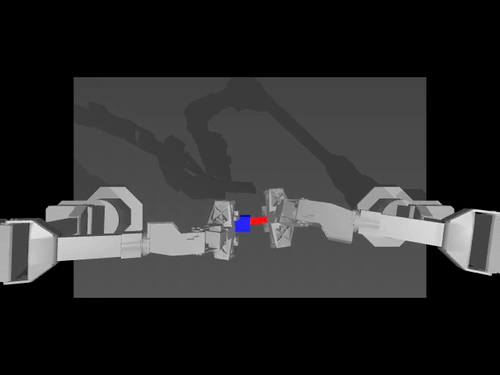 |  |  |
| Política ACT no ambiente ALOHA | Política TDMPC no ambiente SimXArm | Política de difusão no ambiente PushT |
Baixe nosso código fonte:
git clone https://github.com/huggingface/lerobot.git
cd lerobot Crie um ambiente virtual com Python 3.10 e ative-o, por exemplo, com miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobotInstalar? LeRobot:
pip install -e .NOTA: Dependendo da sua plataforma, se você encontrar algum erro de construção durante esta etapa, pode ser necessário instalar
cmakeebuild-essentialpara construir algumas de nossas dependências. No Linux:sudo apt-get install cmake build-essential
Para simulações, ? LeRobot vem com ambientes de ginásio que podem ser instalados como extras:
Por exemplo, para instalar ? LeRobot com aloha e pusht, use:
pip install -e " .[aloha, pusht] "Para usar pesos e preconceitos para rastreamento de experimentos, faça login com
wandb login(nota: você também precisará habilitar o WandB na configuração. Veja abaixo.)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
Confira o exemplo 1 que ilustra como usar nossa classe de conjunto de dados que baixa automaticamente os dados do hub Hugging Face.
Você também pode visualizar episódios localmente de um conjunto de dados no hub executando nosso script na linha de comando:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 ou de um conjunto de dados em uma pasta local com a variável de ambiente raiz DATA_DIR (no caso a seguir, o conjunto de dados será pesquisado em ./my_local_data_dir/lerobot/pusht )
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 Ele abrirá rerun.io e exibirá os fluxos da câmera, estados e ações do robô, assim:
Nosso script também pode visualizar conjuntos de dados armazenados em um servidor distante. Consulte python lerobot/scripts/visualize_dataset.py --help para obter mais instruções.
LeRobotDataset Um conjunto de dados no formato LeRobotDataset é muito simples de usar. Ele pode ser carregado de um repositório no hub Hugging Face ou de uma pasta local simplesmente com, por exemplo, dataset = LeRobotDataset("lerobot/aloha_static_coffee") e pode ser indexado como qualquer conjunto de dados Hugging Face e PyTorch. Por exemplo, dataset[0] recuperará um único quadro temporal do conjunto de dados contendo observações e uma ação como tensores PyTorch prontos para serem alimentados em um modelo.
Uma especificidade do LeRobotDataset é que, em vez de recuperar um único quadro pelo seu índice, podemos recuperar vários quadros com base na sua relação temporal com o quadro indexado, definindo delta_timestamps para uma lista de tempos relativos em relação ao quadro indexado. Por exemplo, com delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} pode-se recuperar, para um determinado índice, 4 quadros: 3 quadros "anteriores" de 1 segundo, 0,5 segundos e 0,2 segundos antes do quadro indexado e do próprio quadro indexado (correspondente à entrada 0). Consulte o exemplo 1_load_lerobot_dataset.py para obter mais detalhes sobre delta_timestamps .
Nos bastidores, o formato LeRobotDataset faz uso de várias maneiras de serializar dados que podem ser úteis para entender se você planeja trabalhar mais de perto com esse formato. Tentamos fazer um formato de conjunto de dados flexível, mas simples, que abrangesse a maioria dos tipos de características e especificidades presentes na aprendizagem por reforço e na robótica, na simulação e no mundo real, com foco em câmeras e estados de robôs, mas facilmente estendido a outros tipos de dados sensoriais. entradas, desde que possam ser representadas por um tensor.
Aqui estão os detalhes importantes e a organização da estrutura interna de um LeRobotDataset típico instanciado com dataset = LeRobotDataset("lerobot/aloha_static_coffee") . Os recursos exatos mudarão de conjunto de dados para conjunto de dados, mas não os aspectos principais:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
Um LeRobotDataset é serializado usando vários formatos de arquivo difundidos para cada uma de suas partes, a saber:
safetensorsafetensor O conjunto de dados pode ser carregado/baixado do hub HuggingFace perfeitamente. Para trabalhar em um conjunto de dados local, você pode definir a variável de ambiente DATA_DIR para a pasta raiz do conjunto de dados, conforme ilustrado na seção acima sobre visualização do conjunto de dados.
Confira o exemplo 2 que ilustra como baixar uma política pré-treinada do hub Hugging Face e executar uma avaliação em seu ambiente correspondente.
Também fornecemos um script mais capaz para paralelizar a avaliação em vários ambientes durante a mesma implementação. Aqui está um exemplo com um modelo pré-treinado hospedado em lerobot/diffusion_pusht:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10Observação: depois de treinar sua própria política, você poderá reavaliar os pontos de verificação com:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model Consulte python lerobot/scripts/eval.py --help para obter mais instruções.
Confira o exemplo 3 que ilustra como treinar um modelo usando nossa biblioteca principal em python e o exemplo 4 que mostra como usar nosso script de treinamento na linha de comando.
Em geral, você pode usar nosso script de treinamento para treinar facilmente qualquer política. Aqui está um exemplo de treinamento da política ACT em trajetórias coletadas por humanos no ambiente de simulação Aloha para a tarefa de inserção:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human O diretório do experimento é gerado automaticamente e aparecerá em amarelo no seu terminal. Parece outputs/train/2024-05-05/20-21-12_aloha_act_default . Você pode especificar manualmente um diretório de experimento adicionando este argumento ao comando train.py python:
hydra.run.dir=your/new/experiment/dir No diretório do experimento existirá uma pasta chamada checkpoints que terá a seguinte estrutura:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step Para retomar o treinamento a partir de um ponto de verificação, você pode adicioná-los ao comando train.py python:
hydra.run.dir=your/original/experiment/dir resume=trueEle carregará o modelo pré-treinado, os estados do otimizador e do agendador para treinamento. Para obter mais informações, consulte nosso tutorial sobre a retomada do treinamento aqui.
Para usar o wandb para registrar curvas de treinamento e avaliação, certifique-se de executar wandb login como uma etapa de configuração única. Então, ao executar o comando de treinamento acima, habilite o WandB na configuração adicionando:
wandb.enable=trueUm link para os logs do wandb para a execução também aparecerá em amarelo no seu terminal. Aqui está um exemplo de como eles aparecem no seu navegador. Verifique também aqui a explicação de algumas métricas comumente usadas em logs.

Nota: Para maior eficiência, durante o treinamento cada ponto de verificação é avaliado em um número baixo de episódios. Você pode usar eval.n_episodes=500 para avaliar mais episódios do que o padrão. Ou, após o treinamento, você pode reavaliar seus melhores pontos de verificação em mais episódios ou alterar as configurações de avaliação. Consulte python lerobot/scripts/eval.py --help para obter mais instruções.
Organizamos nossos arquivos de configuração (encontrados em lerobot/configs ) de forma que reproduzam os resultados SOTA de uma determinada variante do modelo em seus respectivos trabalhos originais. Simplesmente executando:
python lerobot/scripts/train.py policy=diffusion env=pushtreproduz resultados SOTA para Política de Difusão na tarefa PushT.
Políticas pré-treinadas, juntamente com detalhes de reprodução, podem ser encontradas na seção “Modelos” de https://huggingface.co/lerobot.
Se você gostaria de contribuir? LeRobot, confira nosso guia de contribuição.
Para adicionar um conjunto de dados ao hub, você precisa fazer login usando um token de acesso de gravação, que pode ser gerado nas configurações do Hugging Face:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential Em seguida, aponte para a pasta do conjunto de dados bruto (por exemplo, data/aloha_static_pingpong_test_raw ) e envie seu conjunto de dados para o hub com:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 Consulte python lerobot/scripts/push_dataset_to_hub.py --help para obter mais instruções.
Se o formato do seu conjunto de dados não for compatível, implemente o seu próprio em lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py copiando exemplos como pusht_zarr, umi_zarr, aloha_hdf5 ou xarm_pkl.
Depois de treinar uma política, você pode carregá-la no hub Hugging Face usando um ID de hub semelhante a ${hf_user}/${repo_name} (por exemplo, lerobot/diffusion_pusht).
Primeiro você precisa encontrar a pasta do ponto de verificação localizada dentro do diretório do experimento (por exemplo, outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). Dentro dele existe um diretório pretrained_model que deve conter:
config.json : uma versão serializada da configuração da política (seguindo a configuração da classe de dados da política).model.safetensors : Um conjunto de parâmetros torch.nn.Module , salvos no formato Hugging Face Safetensors.config.yaml : uma configuração consolidada de treinamento Hydra contendo as configurações de política, ambiente e conjunto de dados. A configuração da política deve corresponder exatamente config.json . A configuração do ambiente é útil para quem deseja avaliar sua política. A configuração do conjunto de dados serve apenas como um registro em papel para reprodutibilidade.Para carregá-los no hub, execute o seguinte:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_modelConsulte eval.py para ver um exemplo de como outras pessoas podem usar sua política.
Um exemplo de trecho de código para traçar o perfil da avaliação de uma política:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function Se quiser, você pode citar este trabalho com:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}Além disso, se você estiver usando qualquer arquitetura de política, modelos pré-treinados ou conjuntos de dados específicos, é recomendável citar os autores originais do trabalho conforme aparecem abaixo:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

