EasyOCR
v1.7.2
OCR pronto para uso com mais de 80 idiomas suportados e todos os scripts de escrita populares, incluindo: latim, chinês, árabe, devanágari, cirílico, etc.
Experimente a demonstração em nosso site
Integrado nos espaços Huggingface? usando Gradio. Experimente a demonstração na Web:
24 de setembro de 2024 - Versão 1.7.2
Leia todas as notas de lançamento



Instalar usando pip
Para a versão estável mais recente:
pip install easyocrPara a versão de desenvolvimento mais recente:
pip install git+https://github.com/JaidedAI/EasyOCR.git Nota 1: Para Windows, instale primeiro o torch e o torchvision seguindo as instruções oficiais aqui https://pytorch.org. No site pytorch, certifique-se de selecionar a versão CUDA correta que você possui. Se você pretende executar apenas no modo CPU, selecione CUDA = None .
Nota 2: Também fornecemos um Dockerfile aqui.
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )A saída estará em formato de lista, cada item representa uma caixa delimitadora, o texto detectado e o nível de confiança, respectivamente.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] Nota 1: ['ch_sim','en'] é a lista de idiomas que você deseja ler. Você pode passar vários idiomas ao mesmo tempo, mas nem todos os idiomas podem ser usados juntos. O inglês é compatível com todos os idiomas e os idiomas que compartilham caracteres comuns geralmente são compatíveis entre si.
Nota 2: Em vez do caminho do arquivo chinese.jpg , você também pode passar um objeto de imagem OpenCV (matriz numpy) ou um arquivo de imagem como bytes. Um URL para uma imagem bruta também é aceitável.
Nota 3: A linha reader = easyocr.Reader(['ch_sim','en']) serve para carregar um modelo na memória. Demora algum tempo, mas precisa ser executado apenas uma vez.
Você também pode definir detail=0 para uma saída mais simples.
reader . readtext ( 'chinese.jpg' , detail = 0 )Resultado:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]Os pesos do modelo para o idioma escolhido serão baixados automaticamente ou você pode baixá-los manualmente do hub do modelo e colocá-los na pasta '~/.EasyOCR/model'
Caso você não tenha uma GPU ou sua GPU tenha pouca memória, você pode executar o modelo no modo somente CPU adicionando gpu=False .
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )Para obter mais informações, leia o tutorial e a documentação da API.
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=TruePara modelo de reconhecimento, leia aqui.
Para modelo de detecção (CRAFT), leia aqui.
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )A ideia é poder conectar qualquer modelo de última geração ao EasyOCR. Existem muitos gênios tentando criar melhores modelos de detecção/reconhecimento, mas não estamos tentando ser gênios aqui. Queremos apenas tornar seus trabalhos rapidamente acessíveis ao público... de graça. (bem, acreditamos que a maioria dos gênios deseja que seu trabalho crie um impacto positivo o mais rápido/grande possível). O pipeline deve ser algo como o diagrama abaixo. Os slots cinza são espaços reservados para módulos alteráveis em azul claro.
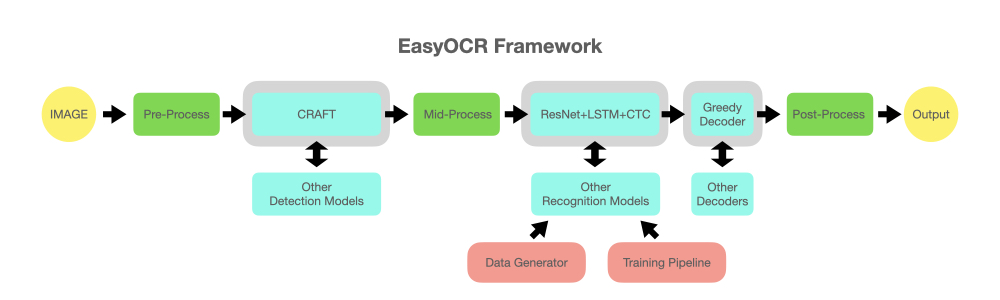
Este projeto é baseado em pesquisas e códigos de diversos artigos e repositórios de código aberto.
Toda a execução de aprendizado profundo é baseada em Pytorch. ❤️
A execução da detecção usa o algoritmo CRAFT deste repositório oficial e seu artigo (Obrigado @YoungminBaek de @clovaai). Também usamos seu modelo pré-treinado. O roteiro de treinamento é fornecido por @gmuffiness.
O modelo de reconhecimento é um CRNN (papel). É composto por 3 componentes principais: extração de características (atualmente usamos Resnet) e VGG, rotulagem de sequência (LSTM) e decodificação (CTC). O pipeline de treinamento para execução de reconhecimento é uma versão modificada da estrutura de benchmark de reconhecimento de texto profundo. (Obrigado @ku21fan de @clovaai) Este repositório é uma joia que merece mais reconhecimento.
O código de pesquisa do Beam é baseado neste repositório e em seu blog. (Obrigado @githubharald)
A síntese de dados é baseada em TextRecognitionDataGenerator. (Obrigado @Belval)
E uma boa leitura sobre CTC emstill.pub aqui.
Vamos avançar a humanidade juntos, disponibilizando a IA para todos!
3 maneiras de contribuir:
Codificador: Por favor, envie um PR para pequenos bugs/melhorias. Para os maiores, discuta conosco abrindo uma edição primeiro. Há uma lista de possíveis problemas de bugs/melhorias marcados com 'PR WELCOME'.
Usuário: Conte-nos como o EasyOCR beneficia você/sua organização para incentivar um maior desenvolvimento. Publique também casos de falha na seção de problemas para ajudar a melhorar modelos futuros.
Líder técnico/Guru: Se você achou esta biblioteca útil, divulgue! (Veja a postagem de Yann Lecun sobre EasyOCR)
Para solicitar um novo idioma, precisamos que você envie um PR com os 2 arquivos a seguir:
Se o seu idioma tiver elementos únicos (como 1. Árabe: os caracteres mudam de forma quando anexados uns aos outros + escreva da direita para a esquerda 2. Tailandês: alguns caracteres precisam estar acima da linha e outros abaixo), por favor, eduque-nos sobre o melhor de sua habilidade e/ou forneça links úteis. É importante cuidar dos detalhes para conseguir um sistema que realmente funcione.
Por último, entenda que nossa prioridade terá que ir para idiomas populares ou conjuntos de idiomas que compartilham grandes porções de seus caracteres entre si (diga-nos também se este é o caso do seu idioma). Levamos pelo menos uma semana para desenvolver um novo modelo, então talvez seja necessário esperar um pouco até que o novo modelo seja lançado.
Veja Lista de linguagens em desenvolvimento
Devido aos recursos limitados, um problema com mais de 6 meses será automaticamente encerrado. Abra um problema novamente se for crítico.
Para suporte empresarial, a Jaided AI oferece serviço completo para sistemas OCR/AI personalizados, desde implementação, treinamento/ajuste e implantação. Clique aqui para entrar em contato conosco.


