LVBench
1.0.0
[Página do projeto] [Artigo arXiv] [Conjunto de dados][? Tabela de classificação][? Tabela de classificação Huggingface]
LVBench é um benchmark desenvolvido para avaliar e aprimorar as capacidades de modelos multimodais na compreensão e extração de informações de vídeos longos de até duas horas de duração.
2024.08.2 Configuramos a tabela de classificação do LVBench no Huggingface Spaces! Dê uma olhada na tabela de classificação.
2024.06.11 Lançamos o LVBench, um novo benchmark para compreensão de vídeos longos!
LVBench é um benchmark desenvolvido para avaliar as capacidades dos modelos na compreensão de vídeos longos. Coletamos extensos dados de vídeos longos de fontes públicas, anotados por meio de uma combinação de esforço manual e assistência de modelo. Nosso benchmark fornece uma base robusta para testar modelos em contextos temporais estendidos, garantindo avaliação de alta qualidade por meio de anotações humanas meticulosas e controle de qualidade em vários estágios.
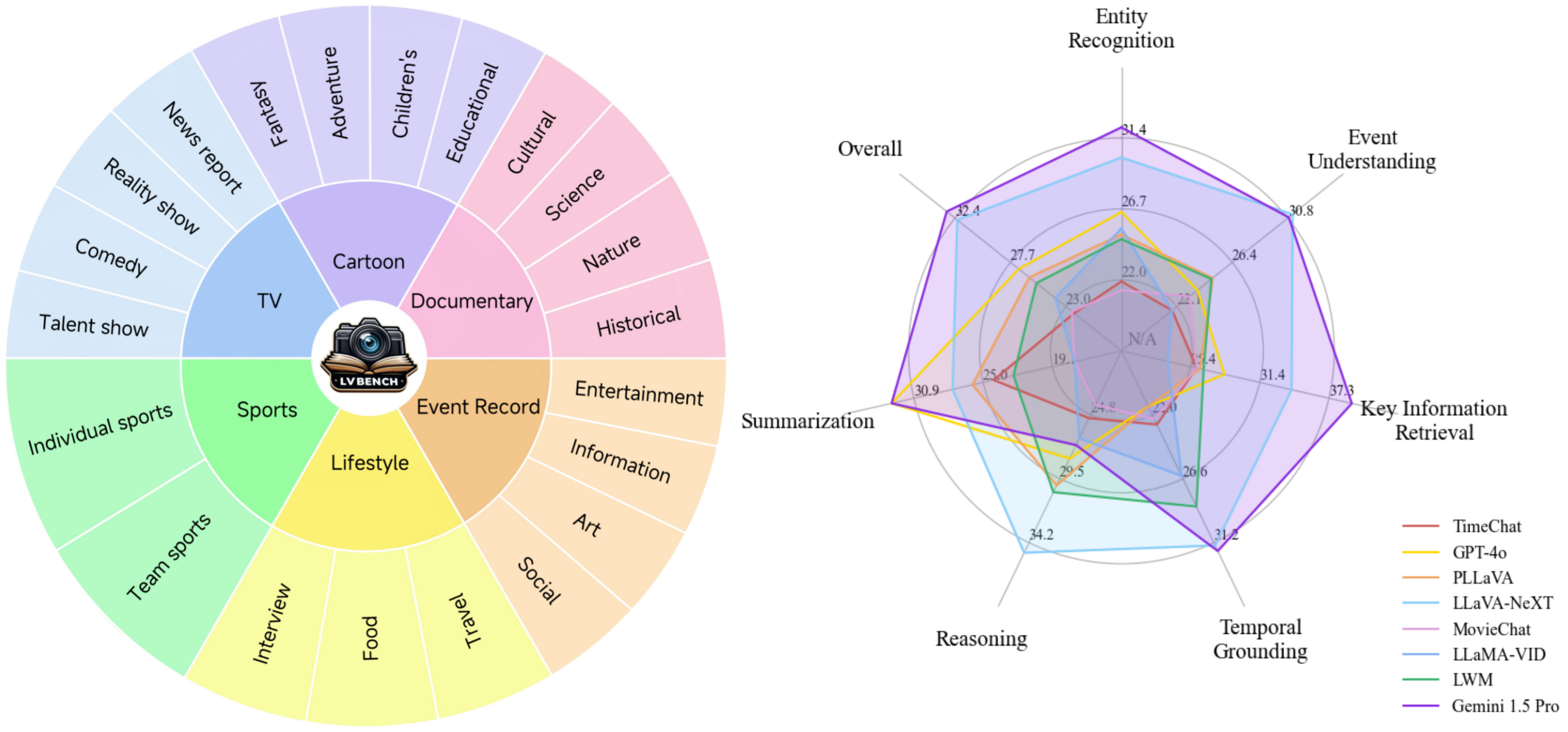
Capacidades principais : Seis capacidades principais para compreensão de vídeos longos, permitindo a criação de perguntas complexas e desafiadoras para avaliação abrangente do modelo.
Dados diversos : uma gama diversificada de dados de vídeo longos, com duração média cinco vezes maior que os conjuntos de dados mais longos existentes, abrangendo diversas categorias.
Anotações de alta qualidade : Referência confiável com anotações humanas meticulosas e processos de controle de qualidade em vários estágios.

Nosso conjunto de dados está sob a licença CC-BY-NC-SA-4.0.
LVBench é usado apenas para pesquisas acadêmicas. O uso comercial sob qualquer forma é proibido. Não possuímos os direitos autorais de nenhum arquivo de vídeo bruto.
Se houver alguma violação no LVBench, entre em contato com [email protected] ou levante um problema diretamente e nós o removeremos imediatamente.
Instale video2dataset primeiro:
pip instalar video2dataset pip desinstalar o motor do transformador
Então você deve baixar video_info.meta.jsonl do Huggingface e colocá-lo no diretório data .
Cada entrada no arquivo video_info.meta.jsonl possui um campo-chave correspondente ao ID de um vídeo do YouTube. Os usuários podem baixar o vídeo correspondente usando este ID. Como alternativa, os usuários podem usar o script de download que fornecemos, download.sh, para fazer download:
scripts de CD bash download.sh
Após a execução, os arquivos de vídeo serão armazenados no diretório script/videos .
pip instalar -e.
(Observação: se quiser tentar a avaliação rapidamente, você pode usar scripts/construct_random_answers.py para preparar um arquivo de resposta aleatório.)
scripts de CD python test_acc.py
Após a execução, você obterá um arquivo de resultados da avaliação result.json no diretório scripts . Você pode enviar os resultados para a tabela de classificação.
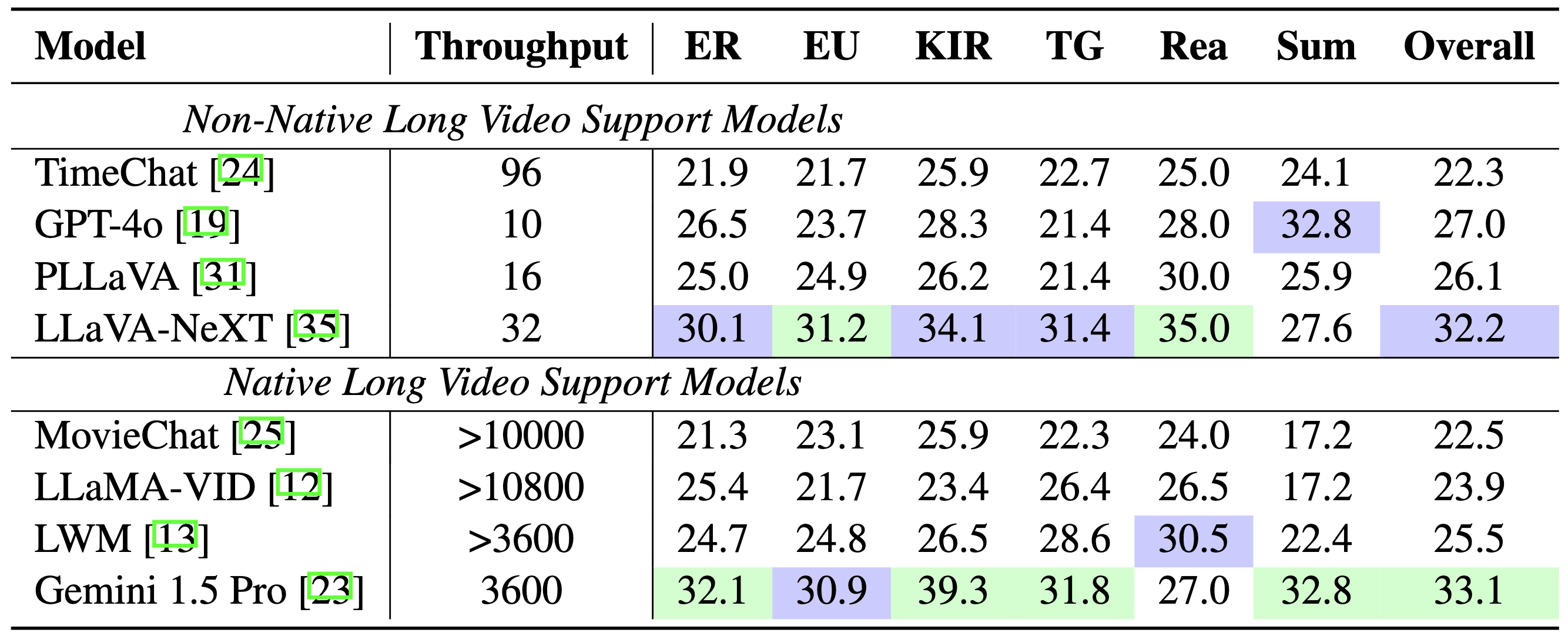
Comparação de modelos:
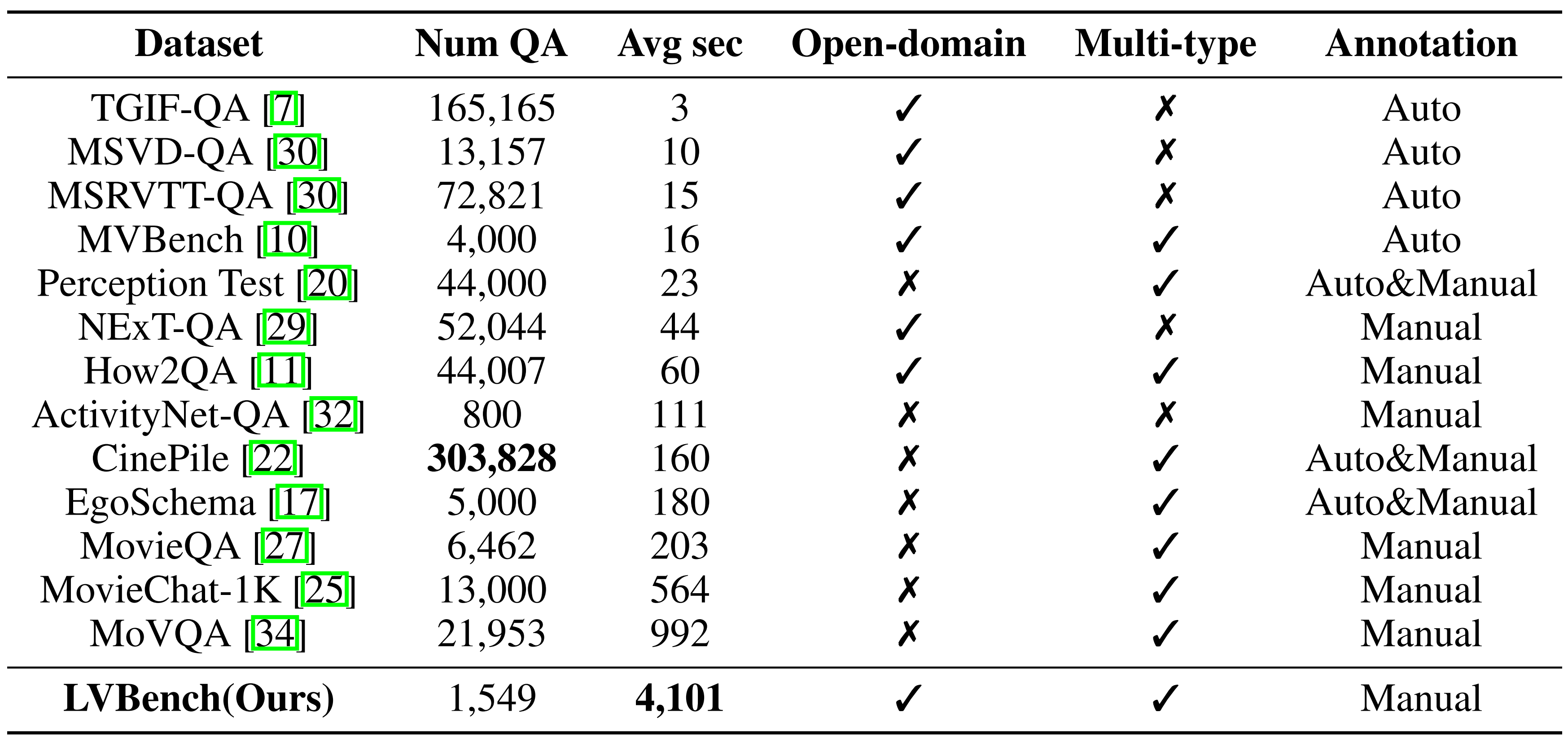
Comparação de referência:
Modelo vs Humano:

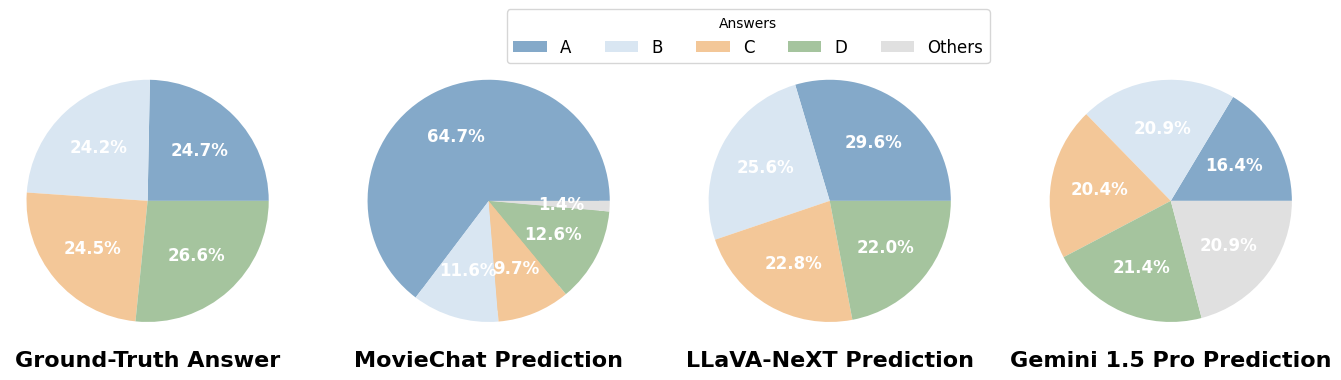
Distribuição de respostas:
Se você achar nosso trabalho útil para sua pesquisa, considere citá-lo.
@misc{wang2024lvbench, title={LVBench: um benchmark de compreensão de vídeo extremamente longo},
autor = {Weihan Wang e Zehai He e Wenyi Hong e Yean Cheng e Xiaohan Zhang e Ji Qi e Shiyu Huang e Bin Xu e Yuxiao Dong e Ming Ding e Jie Tang}, ano = {2024}, eprint = {2406.08035}, archivePrefix ={arXiv}, classeprimária={cs.CV}} 

