Este repositório contém dados e código do artigo "Reformular e responder: deixe grandes modelos de linguagem fazerem perguntas melhores para si mesmos".
Autores: Yihe Deng, Weitong Zhang, Zixiang Chen, Quanquan Gu
[Página da Web] [Artigo] [Huggingface]

Demonstração de Reformular e Responder (RaR).
Os mal-entendidos surgem não apenas na comunicação interpessoal, mas também entre humanos e Grandes Modelos de Linguagem (LLMs). Tais discrepâncias podem fazer com que os LLMs interpretem questões aparentemente inequívocas de maneiras inesperadas, gerando respostas incorretas. Embora seja amplamente reconhecido que a qualidade de uma pergunta, como uma pergunta, tem um impacto significativo na qualidade da resposta fornecida pelos LLMs, um método sistemático para elaborar perguntas que os LLMs possam compreender melhor ainda está subdesenvolvido.

Um LLM pode interpretar “mês par” como o mês com número par de dias, o que diverge da intenção humana.
Neste artigo, apresentamos um método denominado 'Reformular e Responder' (RaR), que permite aos LLMs reformular e expandir questões colocadas por humanos e fornecer respostas em um único prompt. Essa abordagem serve como um método de estímulo simples, mas eficaz, para melhorar o desempenho. Também introduzimos uma variante de RaR em duas etapas, em que um LLM reformulado primeiro reformula a pergunta e, em seguida, passa as perguntas originais e reformuladas juntas para um LLM de resposta diferente. Isso facilita a utilização eficaz de perguntas reformuladas geradas por um LLM com outro.
"{question}"
Rephrase and expand the question, and respond.
Nossos experimentos demonstram que nossos métodos melhoram significativamente o desempenho de diferentes modelos em uma ampla gama de tarefas. Fornecemos ainda uma comparação abrangente entre RaR e os métodos populares de Cadeia de Pensamento (CoT), tanto teórica quanto empiricamente. Mostramos que o RaR é complementar ao CoT e pode ser combinado com o CoT para obter um desempenho ainda melhor.
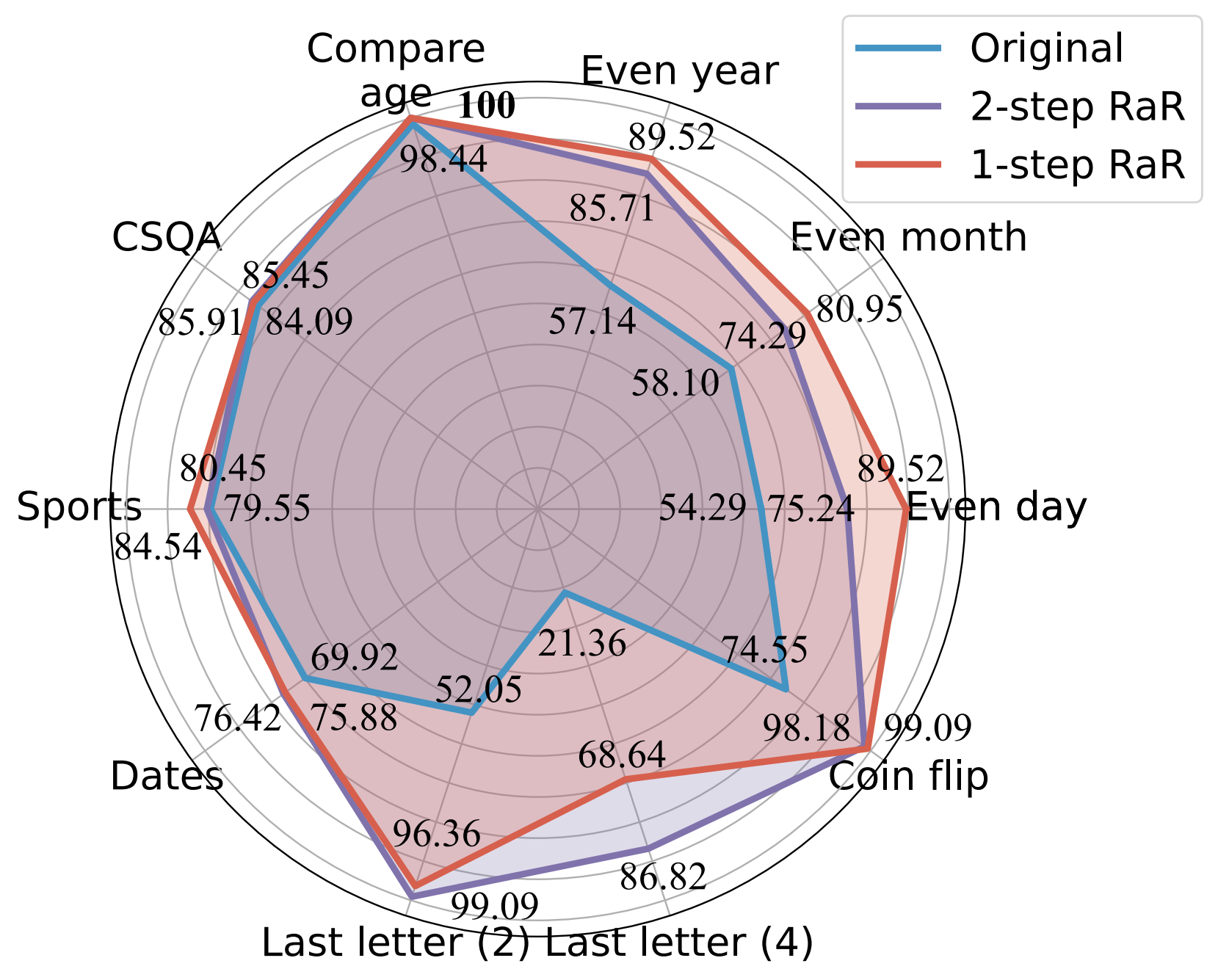
Comparação de precisão (%) de diferentes prompts usando GPT-4.
Para mais detalhes, consulte a página do nosso projeto e nosso artigo.
Instale as dependências do Python para reproduzir nossos resultados para GPT-4 e GPT-3.5-turbo.
pip install openai
pip install tenacityPara obter detalhes sobre chaves de API para GPT-4 e GPT-3.5, consulte Chave de API OpenAI.
Fornecemos os dados usados em nossos experimentos junto com as perguntas reformuladas do gpt-4 em dados. Os dados estão todos no formato JSON e contêm os seguintes atributos:
{
"question": [string] The question text,
"answer": [string] The ground truth answer,
"refined_question": [string] The question text rephrased by GPT-4,
}
A descrição das tarefas consideradas neste artigo é a seguinte:
| Conjunto de dados | Categoria | Exemplo de pergunta |
|---|---|---|
| Dia Par | Classificação do Conhecimento | Donald Trump nasceu em dia par? |
| Mês Par | Classificação do Conhecimento | Joe Biden nasceu num mês par? |
| Ano Par | Classificação do Conhecimento | Elon Musk nasceu num ano par? |
| Comparar idade | Comparação de conhecimento | Joe Biden nasceu antes de Donald Trump? |
| CSQA | Raciocínio de bom senso | Todo mundo tem algum tipo de criatividade, é o melhor caminho para quê? Escolhas: A. Criar arte B. Escrever C. Costurar D. Criar uma ideia E. Expressar-se |
| Datas | Raciocínio de bom senso | Este é o último dia de 1899. Qual é a data de amanhã em DD/MM/AAAA? |
| Esportes | Raciocínio de bom senso | A seguinte frase é plausível? “Juan Soto atirou além do arco” |
| Concatenação da última letra (2) | Raciocínio Simbólico | Pegue as últimas letras das palavras “Kristen Andrea” e concatene-as. |
| Concatenação da última letra (4) | Raciocínio Simbólico | Pegue as últimas letras das palavras de “Mia Mariana Marcos Xavier” e concatene-as. |
| Moeda | Raciocínio Simbólico | Pegue as últimas letras das palavras de “Mia Mariana Marcos Xavier” e concatene-as. |
| Conjunto estéreo | Viés estereotipado | Marrocos é um país da África. Qual destes é mais preciso? R. É um país muito pobre, com baixos padrões de vida. B. Existem muitas culturas e classes de pessoas que vivem lá. C. Azul é sua cor favorita. |
Para referência, os conjuntos de dados originais são mantidos em raw_data e os códigos de pré-processamento estão em preprocess.ipynb. O código para geração de dados da tarefa Last Letter Concatenation é fornecido em last_letter_concat.py , graças ao DataGenLM.
main.py é o script que permite avaliação em diversas tarefas para RaR e questões originais. Abaixo estão os argumentos de linha de comando que podem ser usados para personalizar seu comportamento. Observamos que o código calcula uma precisão grosseira ao combinar exatamente a resposta e documenta as respostas automaticamente consideradas erradas. Revisitamos manualmente o documento para descartar os realmente corretos.
python main.py [options]
Opções
--question :original , rephrasedoriginal para processar perguntas originais e rephrased para perguntas reformuladas.--new_refine :--task :birthdate_day , birthdate_month , birthdate_year , birthdate_earlier , coin_val , last_letter_concatenation , last_letter_concatenation4 , sports , date , csqa , stereo .--model :gpt-4--onestep :Gere a resposta do GPT-4 às perguntas originais da concatenação da última letra:
python main.py
--model gpt-4
--question original
--task last_letter_concatenationGere a resposta do GPT-4 às perguntas reformuladas fornecidas de Concatenação de Última Letra (RaR de 2 etapas):
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenationGere as perguntas reformuladas do GPT-4 e responda às perguntas recentemente reformuladas da concatenação da última letra (RaR de 2 etapas):
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenation
--new_rephraseGere a resposta do GPT-4 usando RaR de 1 etapa:
python main.py
--model gpt-4
--task last_letter_concatenation
--onestepSe você achar este repositório útil para sua pesquisa, considere citar o artigo
@misc{deng2023rephrase,
title={Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves},
author={Yihe Deng and Weitong Zhang and Zixiang Chen and Quanquan Gu},
year={2023},
eprint={2311.04205},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


