Curso de Modelo de Linguagem Grande
? Siga-me no X • ? Abraçando o Rosto • Blog • ? GNN prático
O curso LLM é dividido em três partes:
- ? LLM Fundamentals cobre conhecimentos essenciais sobre matemática, Python e redes neurais.
- ?? O Cientista LLM se concentra na construção dos melhores LLMs possíveis usando as técnicas mais recentes.
- ? O Engenheiro LLM se concentra na criação de aplicativos baseados em LLM e na implantação deles.
Para uma versão interativa deste curso, criei dois assistentes LLM que irão tirar dúvidas e testar seus conhecimentos de forma personalizada:
- ? HuggingChat Assistant : Versão gratuita usando Mixtral-8x7B.
- ? Assistente ChatGPT : Requer uma conta premium.
Cadernos
Uma lista de cadernos e artigos relacionados a grandes modelos de linguagem.
Ferramentas
| Caderno | Descrição | Caderno |
|---|
| ? LLM AutoEval | Avalie automaticamente seus LLMs usando RunPod | |
| ? LazyMergekit | Mescle modelos facilmente usando o MergeKit com um clique. | |
| ? PreguiçosoAxolote | Ajuste modelos na nuvem usando Axolotl com um clique. | |
| ⚡ AutoQuant | Quantize LLMs nos formatos GGUF, GPTQ, EXL2, AWQ e HQQ com um clique. | |
| ? Árvore genealógica modelo | Visualize a árvore genealógica dos modelos mesclados. | |
| Espaço Zero | Crie automaticamente uma interface de bate-papo Gradio usando um ZeroGPU gratuito. | |
Afinação
| Caderno | Descrição | Artigo | Caderno |
|---|
| Ajuste o Llama 2 com QLoRA | Guia passo a passo para ajuste supervisionado do Llama 2 no Google Colab. | Artigo | |
| Ajuste CodeLlama usando Axolotl | Guia completo da ferramenta de última geração para ajuste fino. | Artigo | |
| Ajuste Mistral-7b com QLoRA | Supervisionei o ajuste fino do Mistral-7b em um Google Colab de nível gratuito com TRL. | | |
| Ajuste Mistral-7b com DPO | Aumente o desempenho de modelos supervisionados e ajustados com DPO. | Artigo | |
| Ajuste o Llama 3 com ORPO | Ajuste fino mais barato e rápido em um único estágio com ORPO. | Artigo | |
| Ajuste o Llama 3.1 com Unsloth | Ajuste fino supervisionado ultraeficiente no Google Colab. | Artigo | |
Quantização
| Caderno | Descrição | Artigo | Caderno |
|---|
| Introdução à Quantização | Otimização de modelos de linguagem grande usando quantização de 8 bits. | Artigo | |
| Quantização de 4 bits usando GPTQ | Quantize seus próprios LLMs de código aberto para executá-los em hardware de consumo. | Artigo | |
| Quantização com GGUF e llama.cpp | Quantize modelos Llama 2 com llama.cpp e carregue versões GGUF para o HF Hub. | Artigo | |
| ExLlamaV2: a biblioteca mais rápida para executar LLMs | Quantize e execute modelos EXL2 e carregue-os no HF Hub. | Artigo | |
Outro
| Caderno | Descrição | Artigo | Caderno |
|---|
| Estratégias de decodificação em grandes modelos de linguagem | Um guia para geração de texto desde a pesquisa de feixe até a amostragem de núcleo | Artigo | |
| Melhore o ChatGPT com gráficos de conhecimento | Aumente as respostas do ChatGPT com gráficos de conhecimento. | Artigo | |
| Mesclar LLMs com MergeKit | Crie seus próprios modelos facilmente, sem necessidade de GPU! | Artigo | |
| Crie MoEs com MergeKit | Combine vários especialistas em um único frankenMoE | Artigo | |
| Não censurar qualquer LLM com abliteração | Ajuste fino sem reciclagem | Artigo | |
? Fundamentos do LLM
Esta seção apresenta conhecimentos essenciais sobre matemática, Python e redes neurais. Você pode não querer começar aqui, mas consulte-o conforme necessário.
Alternar seção
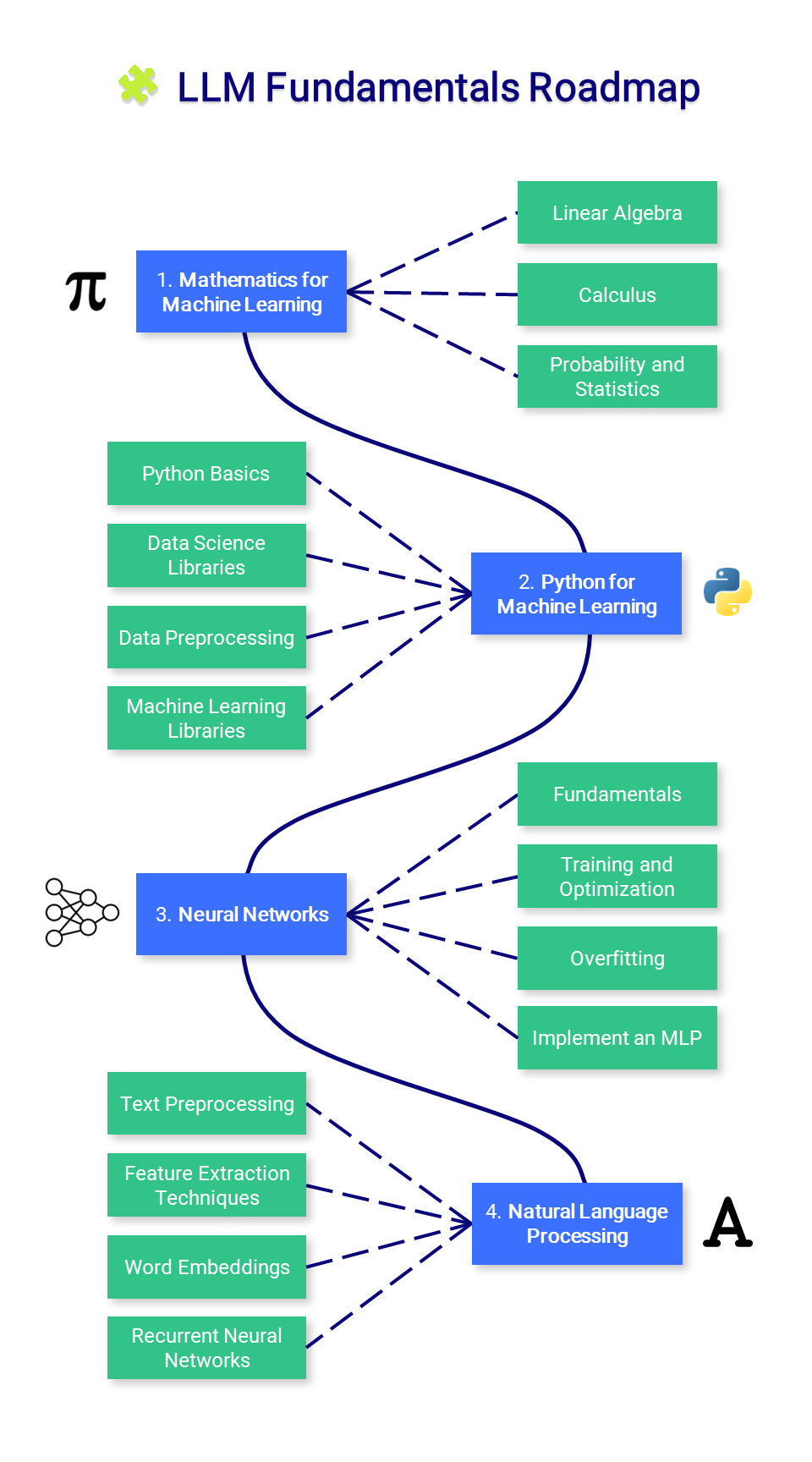
1. Matemática para Aprendizado de Máquina
Antes de dominar o aprendizado de máquina, é importante compreender os conceitos matemáticos fundamentais que alimentam esses algoritmos.
- Álgebra Linear : Isto é crucial para a compreensão de muitos algoritmos, especialmente aqueles usados em aprendizagem profunda. Os conceitos-chave incluem vetores, matrizes, determinantes, autovalores e autovetores, espaços vetoriais e transformações lineares.
- Cálculo : Muitos algoritmos de aprendizado de máquina envolvem a otimização de funções contínuas, o que requer uma compreensão de derivadas, integrais, limites e séries. O cálculo multivariável e o conceito de gradientes também são importantes.
- Probabilidade e Estatística : são cruciais para compreender como os modelos aprendem com os dados e fazem previsões. Os conceitos-chave incluem teoria da probabilidade, variáveis aleatórias, distribuições de probabilidade, expectativas, variância, covariância, correlação, teste de hipóteses, intervalos de confiança, estimativa de máxima verossimilhança e inferência bayesiana.
Recursos:
- 3Blue1Brown - A Essência da Álgebra Linear: Série de vídeos que dão uma intuição geométrica a esses conceitos.
- StatQuest com Josh Starmer - Fundamentos de Estatística: Oferece explicações simples e claras para muitos conceitos estatísticos.
- AP Statistics Intuition, da Sra. Aerin: Lista de artigos do Medium que fornecem a intuição por trás de cada distribuição de probabilidade.
- Álgebra Linear Imersiva: Outra interpretação visual da álgebra linear.
- Khan Academy - Álgebra Linear: Ótimo para iniciantes, pois explica os conceitos de uma forma muito intuitiva.
- Khan Academy - Cálculo: Um curso interativo que cobre todos os fundamentos do cálculo.
- Khan Academy - Probabilidade e Estatística: Oferece o material em um formato fácil de entender.
2. Python para aprendizado de máquina
Python é uma linguagem de programação poderosa e flexível que é particularmente boa para aprendizado de máquina, graças à sua legibilidade, consistência e ecossistema robusto de bibliotecas de ciência de dados.
- Noções básicas de Python : a programação Python requer um bom entendimento da sintaxe básica, tipos de dados, tratamento de erros e programação orientada a objetos.
- Bibliotecas de ciência de dados : inclui familiaridade com NumPy para operações numéricas, Pandas para manipulação e análise de dados, Matplotlib e Seaborn para visualização de dados.
- Pré-processamento de dados : envolve dimensionamento e normalização de recursos, tratamento de dados ausentes, detecção de valores discrepantes, codificação de dados categóricos e divisão de dados em conjuntos de treinamento, validação e teste.
- Bibliotecas de aprendizado de máquina : é vital ter proficiência com Scikit-learn, uma biblioteca que fornece uma ampla seleção de algoritmos de aprendizado supervisionado e não supervisionado. É importante compreender como implementar algoritmos como regressão linear, regressão logística, árvores de decisão, florestas aleatórias, k-vizinhos mais próximos (K-NN) e agrupamento K-means. Técnicas de redução de dimensionalidade como PCA e t-SNE também são úteis para visualizar dados de alta dimensão.
Recursos:
- Real Python: um recurso abrangente com artigos e tutoriais para conceitos iniciantes e avançados de Python.
- freeCodeCamp - Aprenda Python: vídeo longo que fornece uma introdução completa a todos os conceitos básicos do Python.
- Manual de ciência de dados Python: livro digital gratuito que é um ótimo recurso para aprender pandas, NumPy, Matplotlib e Seaborn.
- freeCodeCamp - Aprendizado de Máquina para Todos: Introdução prática a diferentes algoritmos de aprendizado de máquina para iniciantes.
- Udacity - Introdução ao Machine Learning: Curso gratuito que aborda PCA e vários outros conceitos de aprendizado de máquina.
3. Redes Neurais
As redes neurais são uma parte fundamental de muitos modelos de aprendizado de máquina, especialmente no domínio do aprendizado profundo. Para utilizá-los de forma eficaz, é essencial uma compreensão abrangente de seu design e mecânica.
- Fundamentos : Isso inclui a compreensão da estrutura de uma rede neural, como camadas, pesos, vieses e funções de ativação (sigmóide, tanh, ReLU, etc.)
- Treinamento e Otimização : Familiarize-se com retropropagação e diferentes tipos de funções de perda, como erro quadrático médio (MSE) e entropia cruzada. Entenda vários algoritmos de otimização como Gradient Descent, Stochastic Gradient Descent, RMSprop e Adam.
- Overfitting : Entenda o conceito de overfitting (onde um modelo tem um bom desempenho em dados de treinamento, mas ruim em dados não vistos) e aprenda várias técnicas de regularização (abandono, regularização L1/L2, parada antecipada, aumento de dados) para evitá-lo.
- Implementar um Multilayer Perceptron (MLP) : Construa um MLP, também conhecido como rede totalmente conectada, usando PyTorch.
Recursos:
- 3Blue1Brown - Mas o que é uma Rede Neural?: Este vídeo fornece uma explicação intuitiva das redes neurais e seu funcionamento interno.
- freeCodeCamp - Curso intensivo de aprendizado profundo: Este vídeo apresenta com eficiência todos os conceitos mais importantes do aprendizado profundo.
- Fast.ai - Practical Deep Learning: curso gratuito desenvolvido para pessoas com experiência em codificação que desejam aprender sobre aprendizado profundo.
- Patrick Loeber - Tutoriais do PyTorch: Série de vídeos para iniciantes aprenderem sobre o PyTorch.
4. Processamento de Linguagem Natural (PNL)
A PNL é um ramo fascinante da inteligência artificial que preenche a lacuna entre a linguagem humana e a compreensão da máquina. Do simples processamento de texto à compreensão das nuances linguísticas, a PNL desempenha um papel crucial em muitas aplicações, como tradução, análise de sentimentos, chatbots e muito mais.
- Pré-processamento de texto : aprenda várias etapas de pré-processamento de texto, como tokenização (dividir o texto em palavras ou frases), lematização (redução das palavras à sua forma raiz), lematização (semelhante à lematização, mas considera o contexto), remoção de palavras de parada, etc.
- Técnicas de extração de recursos : familiarize-se com técnicas para converter dados de texto em um formato que possa ser entendido por algoritmos de aprendizado de máquina. Os principais métodos incluem Bag-of-words (BoW), Term Frequency-Inverse Document Frequency (TF-IDF) e n-gramas.
- Embeddings de palavras : os embeddings de palavras são um tipo de representação de palavras que permite que palavras com significados semelhantes tenham representações semelhantes. Os principais métodos incluem Word2Vec, GloVe e FastText.
- Redes Neurais Recorrentes (RNNs) : Entenda o funcionamento das RNNs, um tipo de rede neural projetada para trabalhar com dados de sequência. Explore LSTMs e GRUs, duas variantes de RNN capazes de aprender dependências de longo prazo.
Recursos:
- RealPython - PNL com spaCy em Python: guia completo sobre a biblioteca spaCy para tarefas de PNL em Python.
- Kaggle - Guia de PNL: alguns cadernos e recursos para uma explicação prática de PNL em Python.
- Jay Alammar - A Ilustração Word2Vec: Uma boa referência para entender a famosa arquitetura Word2Vec.
- Jake Tae - PyTorch RNN from Scratch: Implementação prática e simples de modelos RNN, LSTM e GRU em PyTorch.
- blog de colah - Entendendo Redes LSTM: Um artigo mais teórico sobre a rede LSTM.
?? O Cientista LLM
Esta seção do curso se concentra em aprender como construir os melhores LLMs possíveis usando as técnicas mais recentes.
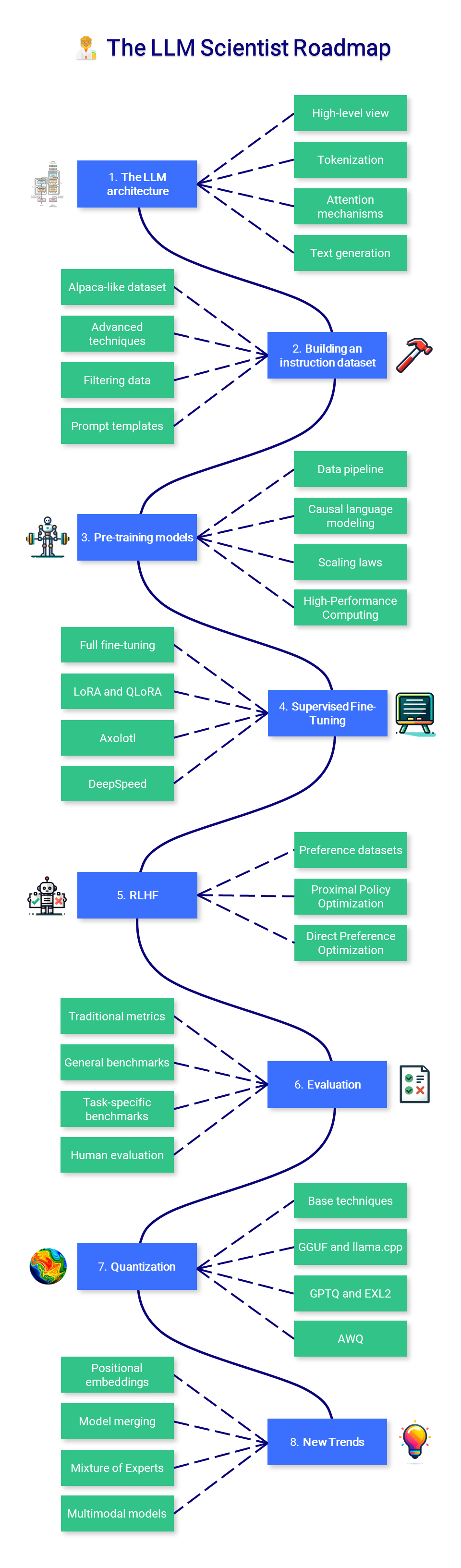
1. A arquitetura LLM
Embora não seja necessário um conhecimento profundo sobre a arquitetura do Transformer, é importante ter um bom entendimento de suas entradas (tokens) e saídas (logits). O mecanismo de atenção vanilla é outro componente crucial a ser dominado, à medida que versões melhoradas dele são introduzidas posteriormente.
- Visão de alto nível : revisite a arquitetura do Transformer codificador-decodificador e, mais especificamente, a arquitetura GPT somente decodificador, que é usada em todos os LLM modernos.
- Tokenização : entenda como converter dados de texto bruto em um formato que o modelo possa entender, o que envolve a divisão do texto em tokens (geralmente palavras ou subpalavras).
- Mecanismos de atenção : compreenda a teoria por trás dos mecanismos de atenção, incluindo autoatenção e atenção de produto escalar, que permite que o modelo se concentre em diferentes partes da entrada ao produzir uma saída.
- Geração de texto : aprenda sobre as diferentes maneiras pelas quais o modelo pode gerar sequências de saída. Estratégias comuns incluem decodificação gananciosa, busca de feixe, amostragem top-k e amostragem de núcleo.
Referências :
- The Illustrated Transformer de Jay Alammar: Uma explicação visual e intuitiva do modelo Transformer.
- The Illustrated GPT-2 de Jay Alammar: Ainda mais importante que o artigo anterior, é focado na arquitetura GPT, que é muito semelhante à do Llama.
- Introdução visual de Transformers por 3Blue1Brown: Introdução visual simples e fácil de entender de Transformers
- Visualização LLM por Brendan Bycroft: Visualização 3D incrível do que acontece dentro de um LLM.
- nanoGPT de Andrej Karpathy: Um vídeo do YouTube de 2h para reimplementar o GPT do zero (para programadores).
- Atenção? Atenção! por Lilian Weng: Apresente a necessidade de atenção de uma forma mais formal.
- Estratégias de decodificação em LLMs: Fornece código e uma introdução visual às diferentes estratégias de decodificação para gerar texto.
2. Construindo um conjunto de dados de instruções
Embora seja fácil encontrar dados brutos da Wikipédia e de outros sites, é difícil coletar pares de instruções e respostas à solta. Tal como na aprendizagem automática tradicional, a qualidade do conjunto de dados influenciará diretamente a qualidade do modelo, razão pela qual pode ser o componente mais importante no processo de ajuste fino.
- Conjunto de dados semelhante ao Alpaca : gere dados sintéticos do zero com a API OpenAI (GPT). Você pode especificar sementes e prompts do sistema para criar um conjunto de dados diversificado.
- Técnicas avançadas : Aprenda como melhorar conjuntos de dados existentes com Evol-Instruct, como gerar dados sintéticos de alta qualidade, como nos artigos Orca e phi-1.
- Filtragem de dados : Técnicas tradicionais envolvendo regex, remoção de quase duplicatas, foco em respostas com grande número de tokens, etc.
- Modelos de prompt : não existe um padrão verdadeiro de formatação de instruções e respostas, por isso é importante conhecer os diferentes modelos de bate-papo, como ChatML, Alpaca, etc.
Referências :
- Preparando um conjunto de dados para ajuste de instrução por Thomas Capelle: Exploração dos conjuntos de dados Alpaca e Alpaca-GPT4 e como formatá-los.
- Gerando um conjunto de dados de instruções clínicas por Solano Todeschini: Tutorial sobre como criar um conjunto de dados de instruções sintéticas usando GPT-4.
- GPT 3.5 para classificação de notícias por Kshitiz Sahay: Use GPT 3.5 para criar um conjunto de dados de instruções para ajustar o Llama 2 para classificação de notícias.
- Criação de conjunto de dados para ajuste fino de LLM: Notebook que contém algumas técnicas para filtrar um conjunto de dados e fazer upload do resultado.
- Modelo de bate-papo de Matthew Carrigan: página do Hugging Face sobre modelos de prompt
3. Modelos de pré-treinamento
A pré-formação é um processo muito longo e dispendioso, razão pela qual este não é o foco deste curso. É bom ter algum nível de compreensão do que acontece durante o pré-treinamento, mas não é necessária experiência prática.
- Pipeline de dados : o pré-treinamento requer enormes conjuntos de dados (por exemplo, o Llama 2 foi treinado em 2 trilhões de tokens) que precisam ser filtrados, tokenizados e agrupados com um vocabulário predefinido.
- Modelagem de linguagem causal : Aprenda a diferença entre modelagem de linguagem causal e mascarada, bem como a função de perda usada neste caso. Para um pré-treinamento eficiente, saiba mais sobre Megatron-LM ou gpt-neox.
- Leis de escalabilidade : as leis de escalabilidade descrevem o desempenho esperado do modelo com base no tamanho do modelo, no tamanho do conjunto de dados e na quantidade de computação usada para treinamento.
- Computação de alto desempenho : Fora do escopo aqui, mas mais conhecimento sobre HPC é fundamental se você planeja criar seu próprio LLM do zero (hardware, carga de trabalho distribuída, etc.).
Referências :
- LLMDataHub por Junhao Zhao: lista selecionada de conjuntos de dados para pré-treinamento, ajuste fino e RLHF.
- Treinando um modelo de linguagem causal do zero com Hugging Face: Pré-treine um modelo GPT-2 do zero usando a biblioteca de transformadores.
- TinyLlama de Zhang et al.: Verifique este projeto para obter uma boa compreensão de como um modelo Llama é treinado do zero.
- Modelagem de linguagem causal por Hugging Face: Explique a diferença entre modelagem de linguagem causal e mascarada e como ajustar rapidamente um modelo DistilGPT-2.
- As implicações selvagens da chinchila por nostalgebraist: Discuta as leis de escala e explique o que elas significam para os LLMs em geral.
- BLOOM by BigScience: Página de noção que descreve como o modelo BLOOM foi construído, com muitas informações úteis sobre a parte de engenharia e os problemas encontrados.
- OPT-175 Logbook by Meta: Registros de pesquisa mostrando o que deu errado e o que deu certo. Útil se você planeja pré-treinar um modelo de linguagem muito grande (neste caso, parâmetros 175B).
- LLM 360: Uma estrutura para LLMs de código aberto com código, dados, métricas e modelos de treinamento e preparação de dados.
4. Ajuste fino supervisionado
Os modelos pré-treinados são treinados apenas em uma tarefa de previsão do próximo token, e é por isso que não são assistentes úteis. SFT permite ajustá-los para responder às instruções. Além disso, permite ajustar seu modelo em quaisquer dados (privados, não vistos pelo GPT-4, etc.) e usá-lo sem ter que pagar por uma API como a do OpenAI.
- Ajuste fino completo : O ajuste fino completo refere-se ao treinamento de todos os parâmetros do modelo. Não é uma técnica eficiente, mas produz resultados um pouco melhores.
- LoRA : Uma técnica com eficiência de parâmetros (PEFT) baseada em adaptadores de baixa classificação. Em vez de treinar todos os parâmetros, treinamos apenas esses adaptadores.
- QLoRA : Outro PEFT baseado em LoRA, que também quantiza os pesos do modelo em 4 bits e introduz otimizadores paginados para gerenciar picos de memória. Combine-o com o Unsloth para executá-lo com eficiência em um notebook Colab gratuito.
- Axolotl : Uma ferramenta de ajuste fino poderosa e fácil de usar que é usada em muitos modelos de código aberto de última geração.
- DeepSpeed : Pré-treinamento eficiente e ajuste fino de LLMs para configurações multi-GPU e multi-nós (implementado em Axolotl).
Referências :
- The Novice's LLM Training Guide da Alpin: Visão geral dos principais conceitos e parâmetros a serem considerados ao ajustar LLMs.
- Insights sobre LoRA por Sebastian Raschka: insights práticos sobre LoRA e como selecionar os melhores parâmetros.
- Ajuste seu próprio modelo Llama 2: Tutorial prático sobre como ajustar um modelo Llama 2 usando bibliotecas Hugging Face.
- Preenchendo modelos de linguagem grande por Benjamin Marie: Melhores práticas para preencher exemplos de treinamento para LLMs causais
- Guia para iniciantes em ajuste fino de LLM: Tutorial sobre como ajustar um modelo CodeLlama usando Axolotl.
5. Alinhamento de preferência
Após o ajuste fino supervisionado, o RLHF é uma etapa usada para alinhar as respostas do LLM com as expectativas humanas. A ideia é aprender as preferências a partir do feedback humano (ou artificial), que pode ser usado para reduzir preconceitos, censurar modelos ou fazê-los agir de forma mais útil. É mais complexo do que uma OFVM e muitas vezes visto como opcional.
- Conjuntos de dados de preferência : Esses conjuntos de dados normalmente contêm várias respostas com algum tipo de classificação, o que os torna mais difíceis de produzir do que conjuntos de dados de instruções.
- Otimização de política proximal : Este algoritmo aproveita um modelo de recompensa que prevê se um determinado texto é bem classificado por humanos. Esta previsão é então usada para otimizar o modelo SFT com uma penalidade baseada na divergência KL.
- Otimização de preferência direta : o DPO simplifica o processo, reformulando-o como um problema de classificação. Ele usa um modelo de referência em vez de um modelo de recompensa (sem necessidade de treinamento) e requer apenas um hiperparâmetro, tornando-o mais estável e eficiente.
Referências :
- Distilabel by Argilla: Excelente ferramenta para criar seus próprios conjuntos de dados. Ele foi especialmente projetado para conjuntos de dados preferenciais, mas também pode realizar SFT.
- Uma introdução ao treinamento de LLMs usando RLHF por Ayush Thakur: Explique por que o RLHF é desejável para reduzir preconceitos e aumentar o desempenho em LLMs.
- Ilustração RLHF de Hugging Face: Introdução ao RLHF com treinamento de modelo de recompensa e ajuste fino com aprendizagem por reforço.
- Preference Tuning LLMs by Hugging Face: Comparação dos algoritmos DPO, IPO e KTO para realizar o alinhamento de preferências.
- Treinamento LLM: RLHF e suas alternativas por Sebastian Rashcka: Visão geral do processo RLHF e alternativas como RLAIF.
- Ajuste fino do Mistral-7b com DPO: Tutorial para ajustar um modelo Mistral-7b com DPO e reproduzir NeuralHermes-2.5.
6. Avaliação
A avaliação de LLMs é uma parte subvalorizada do pipeline, que consome tempo e é moderadamente confiável. Sua tarefa posterior deve ditar o que você deseja avaliar, mas lembre-se sempre da lei de Goodhart: “Quando uma medida se torna uma meta, ela deixa de ser uma boa medida”.
- Métricas tradicionais : métricas como perplexidade e pontuação BLEU não são tão populares como eram porque apresentam falhas na maioria dos contextos. Ainda é importante compreendê-los e quando podem ser aplicados.
- Benchmarks gerais : Com base no Language Model Evaluation Harness, o Open LLM Leaderboard é o principal benchmark para LLMs de uso geral (como ChatGPT). Existem outros benchmarks populares como BigBench, MT-Bench, etc.
- Benchmarks específicos de tarefas : tarefas como resumo, tradução e resposta a perguntas têm benchmarks, métricas e até subdomínios (médicos, financeiros, etc.) dedicados, como PubMedQA para resposta a perguntas biomédicas.
- Avaliação humana : A avaliação mais confiável é a taxa de aceitação pelos usuários ou comparações feitas por humanos. Registrar o feedback do usuário além dos rastreamentos de bate-papo (por exemplo, usando LangSmith) ajuda a identificar possíveis áreas de melhoria.
Referências :
- Perplexidade de modelos de comprimento fixo por Hugging Face: Visão geral da perplexidade com código para implementá-la com a biblioteca de transformadores.
- BLEU por sua própria conta e risco por Rachael Tatman: Visão geral da pontuação BLEU e seus muitos problemas com exemplos.
- Uma Pesquisa sobre Avaliação de LLMs por Chang et al.: Artigo abrangente sobre o que avaliar, onde avaliar e como avaliar.
- Tabela de classificação do Chatbot Arena por lmsys: classificação Elo de LLMs de uso geral, com base em comparações feitas por humanos.
7. Quantização
Quantização é o processo de conversão dos pesos (e ativações) de um modelo com menor precisão. Por exemplo, pesos armazenados em 16 bits podem ser convertidos em uma representação de 4 bits. Esta técnica tem se tornado cada vez mais importante para reduzir os custos computacionais e de memória associados aos LLMs.
- Técnicas básicas : Aprenda os diferentes níveis de precisão (FP32, FP16, INT8, etc.) e como realizar quantização ingênua com técnicas absmax e ponto zero.
- GGUF e llama.cpp : Originalmente projetados para rodar em CPUs, llama.cpp e o formato GGUF se tornaram as ferramentas mais populares para executar LLMs em hardware de consumo.
- GPTQ e EXL2 : GPTQ e, mais especificamente, o formato EXL2 oferecem uma velocidade incrível, mas só podem ser executados em GPUs. Os modelos também demoram muito para serem quantizados.
- AWQ : Este novo formato é mais preciso que o GPTQ (menor perplexidade), mas usa muito mais VRAM e não é necessariamente mais rápido.
Referências :
- Introdução à quantização: Visão geral da quantização, absmax e quantização de ponto zero, e LLM.int8() com código.
- Quantizar modelos Llama com llama.cpp: Tutorial sobre como quantizar um modelo Llama 2 usando llama.cpp e o formato GGUF.
- Quantização LLM de 4 bits com GPTQ: Tutorial sobre como quantizar um LLM usando o algoritmo GPTQ com AutoGPTQ.
- ExLlamaV2: A biblioteca mais rápida para executar LLMs: Guia sobre como quantizar um modelo Mistral usando o formato EXL2 e executá-lo com a biblioteca ExLlamaV2.
- Compreendendo a quantização de peso com reconhecimento de ativação por FriendliAI: Visão geral da técnica AWQ e seus benefícios.
8. Novas Tendências
- Embeddings posicionais : Aprenda como os LLMs codificam posições, especialmente esquemas de codificação posicional relativa como RoPE. Implemente YaRN (multiplica a matriz de atenção por um fator de temperatura) ou ALiBi (penalidade de atenção baseada na distância do token) para estender o comprimento do contexto.
- Mesclagem de modelos : a fusão de modelos treinados tornou-se uma forma popular de criar modelos de desempenho sem qualquer ajuste fino. A popular biblioteca mergekit implementa os métodos de fusão mais populares, como SLERP, DARE e TIES.
- Mistura de Especialistas : Mixtral repopularizou a arquitetura MoE graças ao seu excelente desempenho. Paralelamente, um tipo de frankenMoE surgiu na comunidade OSS ao fundir modelos como o Phixtral, que é uma opção mais barata e de melhor desempenho.
- Modelos multimodais : esses modelos (como CLIP, Stable Diffusion ou LLaVA) processam vários tipos de entradas (texto, imagens, áudio, etc.) com um espaço de incorporação unificado, que desbloqueia aplicativos poderosos como texto para imagem.
Referências :
- Estendendo o RoPE da EleutherAI: Artigo que resume as diferentes técnicas de codificação de posição.
- Compreendendo o YaRN por Rajat Chawla: Introdução ao YaRN.
- Mesclar LLMs com mergekit: Tutorial sobre fusão de modelos usando mergekit.
- Mistura de especialistas explicada por Hugging Face: guia exaustivo sobre MoEs e como eles funcionam.
- Grandes Modelos Multimodais de Chip Huyen: Visão geral dos sistemas multimodais e a história recente deste campo.
? O Engenheiro LLM
Esta seção do curso se concentra em aprender como construir aplicativos com tecnologia LLM que podem ser usados na produção, com foco no aumento de modelos e na implantação deles.
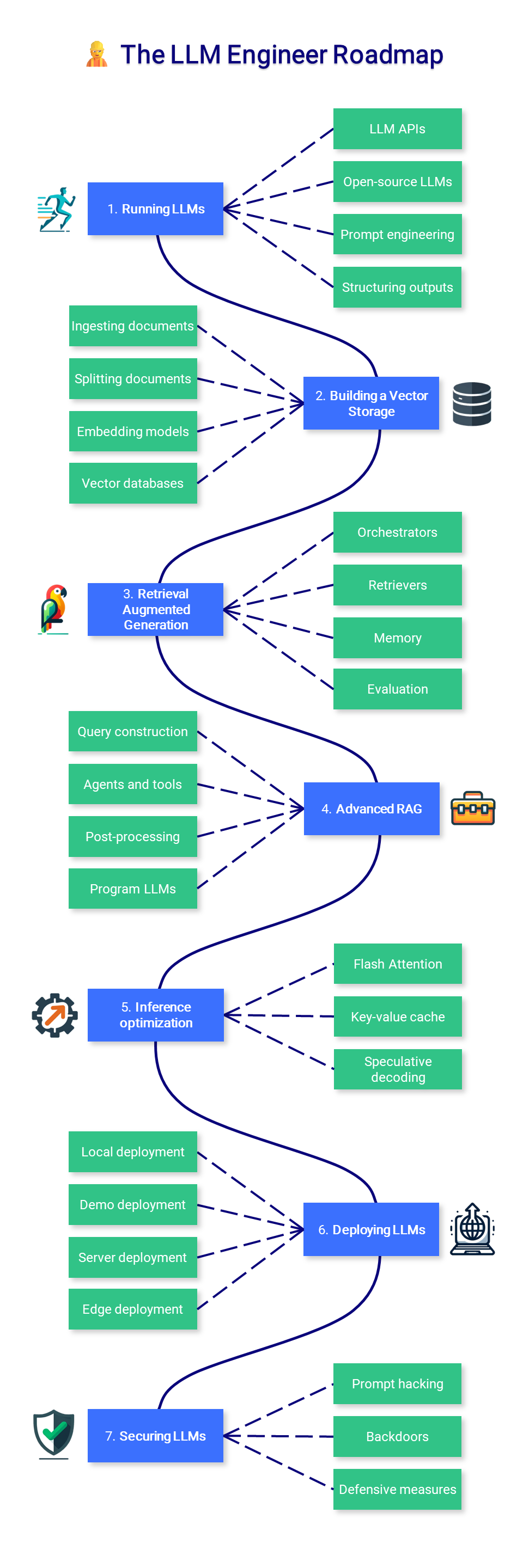
1. Executando LLMs
A execução de LLMs pode ser difícil devido aos altos requisitos de hardware. Dependendo do seu caso de uso, você pode simplesmente consumir um modelo por meio de uma API (como GPT-4) ou executá-lo localmente. Em qualquer caso, técnicas adicionais de solicitação e orientação podem melhorar e restringir a saída de seus aplicativos.
- APIs LLM : APIs são uma maneira conveniente de implantar LLMs. Este espaço é dividido entre LLMs privados (OpenAI, Google, Anthropic, Cohere, etc.) e LLMs de código aberto (OpenRouter, Hugging Face, Together AI, etc.).
- LLMs de código aberto : O Hugging Face Hub é um ótimo lugar para encontrar LLMs. Você pode executar alguns deles diretamente no Hugging Face Spaces ou baixá-los e executá-los localmente em aplicativos como LM Studio ou por meio da CLI com llama.cpp ou Ollama.
- Engenharia de prompt : técnicas comuns incluem solicitação de disparo zero, solicitação de poucos disparos, cadeia de pensamento e ReAct. Funcionam melhor com modelos maiores, mas podem ser adaptados aos menores.
- Estruturação de resultados : muitas tarefas exigem uma saída estruturada, como um modelo estrito ou um formato JSON. Bibliotecas como LMQL, Outlines, Guidance, etc. podem ser utilizadas para orientar a geração e respeitar uma determinada estrutura.
Referências :
- Execute um LLM localmente com LM Studio por Nisha Arya: breve guia sobre como usar o LM Studio.
- Guia de engenharia de prompt da DAIR.AI: lista exaustiva de técnicas de prompt com exemplos
- Outlines - Quickstart: Lista de técnicas de geração guiada habilitadas pelo Outlines.
- LMQL - Visão geral: introdução à linguagem LMQL.
2. Construindo um armazenamento vetorial
Criar um armazenamento vetorial é a primeira etapa para construir um pipeline de geração aumentada de recuperação (RAG). Os documentos são carregados, divididos e partes relevantes são usadas para produzir representações vetoriais (incorporações) que são armazenadas para uso futuro durante a inferência.
- Ingestão de documentos : os carregadores de documentos são wrappers convenientes que podem lidar com muitos formatos: PDF, JSON, HTML, Markdown, etc. Eles também podem recuperar dados diretamente de alguns bancos de dados e APIs (GitHub, Reddit, Google Drive, etc.).
- Divisão de documentos : os divisores de texto dividem os documentos em partes menores e semanticamente significativas. Em vez de dividir o texto após n caracteres, geralmente é melhor dividir por cabeçalho ou recursivamente, com alguns metadados adicionais.
- Modelos de incorporação : modelos de incorporação convertem texto em representações vetoriais. Permite uma compreensão mais profunda e matizada da linguagem, o que é essencial para realizar a pesquisa semântica.
- Bancos de dados de vetores : bancos de dados de vetores (como Chroma, Pinecone, Milvus, FAISS, Annoy, etc.) são projetados para armazenar vetores de incorporação. Eles permitem a recuperação eficiente de dados que são “mais semelhantes” a uma consulta baseada na similaridade vetorial.
Referências :
- LangChain - Divisores de texto: Lista dos diferentes divisores de texto implementados no LangChain.
- Biblioteca de transformadores de frases: biblioteca popular para incorporação de modelos.
- Tabela de classificação MTEB: Tabela de classificação para modelos incorporados.
- Os 5 principais bancos de dados de vetores de Moez Ali: uma comparação dos melhores e mais populares bancos de dados de vetores.
3. Geração Aumentada de Recuperação
Com o RAG, os LLMs recuperam documentos contextuais de um banco de dados para melhorar a precisão de suas respostas. RAG é uma forma popular de aumentar o conhecimento do modelo sem qualquer ajuste fino.
- Orquestradores : orquestradores (como LangChain, LlamaIndex, FastRAG, etc.) são estruturas populares para conectar seus LLMs com ferramentas, bancos de dados, memórias, etc.
- Recuperadores : as instruções do usuário não são otimizadas para recuperação. Diferentes técnicas (por exemplo, multi-query retriever, HyDE, etc.) podem ser aplicadas para reformulá-los/expandi-los e melhorar o desempenho.
- Memória : para lembrar instruções e respostas anteriores, LLMs e chatbots como ChatGPT adicionam esse histórico à sua janela de contexto. Este buffer pode ser melhorado com sumarização (por exemplo, usando um LLM menor), um armazenamento de vetores + RAG, etc.
- Avaliação : Precisamos avaliar tanto a recuperação do documento (precisão e recuperação do contexto) quanto os estágios de geração (fidelidade e relevância da resposta). Pode ser simplificado com as ferramentas Ragas e DeepEval.
Referências :
- Llamaindex - Conceitos de alto nível: Principais conceitos a saber na construção de pipelines RAG.
- Pinecone - Aumento de recuperação: Visão geral do processo de aumento de recuperação.
- LangChain - Perguntas e Respostas com RAG: Tutorial passo a passo para construir um pipeline RAG típico.
- LangChain - Tipos de memória: Lista de diferentes tipos de memórias com uso relevante.
- Pipeline RAG - Métricas: Visão geral das principais métricas utilizadas para avaliar pipelines RAG.
4. RAG avançado
Os aplicativos da vida real podem exigir pipelines complexos, incluindo bancos de dados SQL ou gráficos, bem como a seleção automática de ferramentas e APIs relevantes. Essas técnicas avançadas podem melhorar uma solução básica e fornecer recursos adicionais.
- Construção de consulta : dados estruturados armazenados em bancos de dados tradicionais requerem uma linguagem de consulta específica como SQL, Cypher, metadados, etc. Podemos traduzir diretamente as instruções do usuário em uma consulta para acessar os dados com construção de consulta.
- Agentes e ferramentas : os agentes aumentam os LLMs selecionando automaticamente as ferramentas mais relevantes para fornecer uma resposta. Essas ferramentas podem ser tão simples como usar o Google ou a Wikipedia, ou mais complexas como um interpretador Python ou Jira.
- Pós-processamento : Etapa final que processa as entradas que alimentam o LLM. Aumenta a relevância e a diversidade dos documentos recuperados com reclassificação, fusão RAG e classificação.
- Programa LLMs : Frameworks como DSPy permitem otimizar prompts e pesos com base em avaliações automatizadas de forma programática.
Referências :
- LangChain - Construção de consulta: postagem no blog sobre diferentes tipos de construção de consulta.
- LangChain - SQL: Tutorial sobre como interagir com bancos de dados SQL com LLMs, envolvendo Text-to-SQL e um agente SQL opcional.
- Pinecone - Agentes LLM: Introdução a agentes e ferramentas com diferentes tipos.
- LLM Powered Autonomous Agents por Lilian Weng: Artigo mais teórico sobre agentes LLM.
- LangChain - RAG da OpenAI: Visão geral das estratégias RAG empregadas pela OpenAI, incluindo pós-processamento.
- DSPy em 8 etapas: Guia de uso geral para DSPy apresentando módulos, assinaturas e otimizadores.
5. Otimização de inferência
A geração de texto é um processo caro que requer hardware caro. Além da quantização, várias técnicas foram propostas para maximizar o rendimento e reduzir os custos de inferência.
- Atenção Flash : Otimização do mecanismo de atenção para transformar sua complexidade de quadrática para linear, agilizando tanto o treinamento quanto a inferência.
- Cache de valor-chave : entenda o cache de valor-chave e as melhorias introduzidas no Multi-Query Attention (MQA) e no Grouped-Query Attention (GQA).
- Decodificação especulativa : Use um modelo pequeno para produzir rascunhos que são então revisados por um modelo maior para acelerar a geração de texto.
Referências :
- Inferência de GPU por Hugging Face: Explique como otimizar a inferência em GPUs.
- Inferência LLM por Databricks: Melhores práticas sobre como otimizar a inferência LLM na produção.
- Otimizando LLMs para velocidade e memória por meio do abraço: Explique três técnicas principais para otimizar velocidade e memória, ou seja, quantização, atenção Flash e inovações arquitetônicas.
- Geração Assistida por Hugging Face: a versão de decodificação especulativa do HF, é uma postagem interessante no blog sobre como funciona com o código para implementá-lo.
6. Implantando LLMs
A implantação de LLMs em escala é um feito de engenharia que pode exigir vários clusters de GPUs. Em outros cenários, demonstrações e aplicativos locais podem ser obtidos com uma complexidade muito menor.
- Implantação local : A privacidade é uma vantagem importante que os LLMs de código aberto têm sobre os privados. Servidores LLM locais (LM Studio, Ollama, oobabooga, kobold.cpp, etc.) aproveitam essa vantagem para potencializar aplicativos locais.
- Implantação de demonstração : Frameworks como Gradio e Streamlit são úteis para criar protótipos de aplicativos e compartilhar demonstrações. Você também pode hospedá -los facilmente on -line, por exemplo, usando espaços de rosto abraçados.
- Implantação do servidor : a implantação LLMS na escala requer nuvem (consulte também a infraestrutura do Skypilot) ou no local e geralmente aproveita estruturas de geração de texto otimizadas como TGI, VLLM, etc.
- Implantação de borda : em ambientes restritos, estruturas de alto desempenho como MLC LLM e MNN-LLM podem implantar LLM em navegadores da web, Android e iOS.
Referências :
- Streamlit - Crie um aplicativo Basic LLM: Tutorial para criar um aplicativo básico do tipo ChatGPT usando o Streamlit.
- HF LLM RECIMENTO DE INFERÊNCIA: Implante LLMS no Amazon Sagemaker usando o contêiner de inferência do Hugging Face.
- Philschmid Blog de Philipp Schmid: Coleção de artigos de alta qualidade sobre a implantação do LLM usando a Amazon Sagemaker.
- Otimizando a latência por Hamel Husain: Comparação de TGI, VLLM, Ctranslate2 e MLC em termos de taxa de transferência e latência.
7. Segura de LLMS
Além dos problemas de segurança tradicionais associados ao Software, os LLMs têm fraquezas únicas devido à maneira como são treinadas e solicitadas.
- Hacking rápido : diferentes técnicas relacionadas à engenharia imediata, incluindo injeção imediata (instruções adicionais para seqüestrar a resposta do modelo), dados de dados rápidos (recuperar seus dados/prompt originais) e jailbreak (solicita a manutenção para ignorar os recursos de segurança).
- Backdoors : os vetores de ataque podem segmentar os dados de treinamento em si, envenenando os dados de treinamento (por exemplo, com informações falsas) ou criando backdoors (gatilhos secretos para alterar o comportamento do modelo durante a inferência).
- Medidas defensivas : A melhor maneira de proteger seus aplicativos LLM é testá -los contra essas vulnerabilidades (por exemplo, usar a equipe vermelha e verificações como Garak) e observá -las na produção (com uma estrutura como Langfuse).
Referências :
- Owasp LLM Top 10 pelo Hego Wiki: Lista das 10 vulnerabilidades mais críticas observadas nos aplicativos LLM.
- Primer de injeção imediata por Joseph Thacker: guia curto dedicado para solicitar injeção para engenheiros.
- LLM Segurança por @LLM_SEC: extensa lista de recursos relacionados à segurança da LLM.
- Red Teaming LLMS da Microsoft: Guia sobre como executar a Red Teaming com o LLMS.
Agradecimentos
Este roteiro foi inspirado no excelente roteiro DevOps de Milan Milanović e Romano Roth.
Agradecimentos especiais a:
- Thomas Thelen por me motivar a criar um roteiro
- André Frade para sua contribuição e revisão do primeiro rascunho
- Dino Dunn para fornecer recursos sobre a LLM Security
- Magdalena Kuhn para melhorar a parte da "avaliação humana"
- ODOVERDOSE para sugerir o vídeo de 3Blue1Brown sobre Transformers
Isenção de responsabilidade: não sou afiliado a nenhuma fonte listada aqui.


