Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, Onkar Dabeer.
Este repositório contém os recursos para nosso artigo ECCV-2022 "SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation". Atualmente lançamos o conjunto de dados Visual Anomaly (VisA).
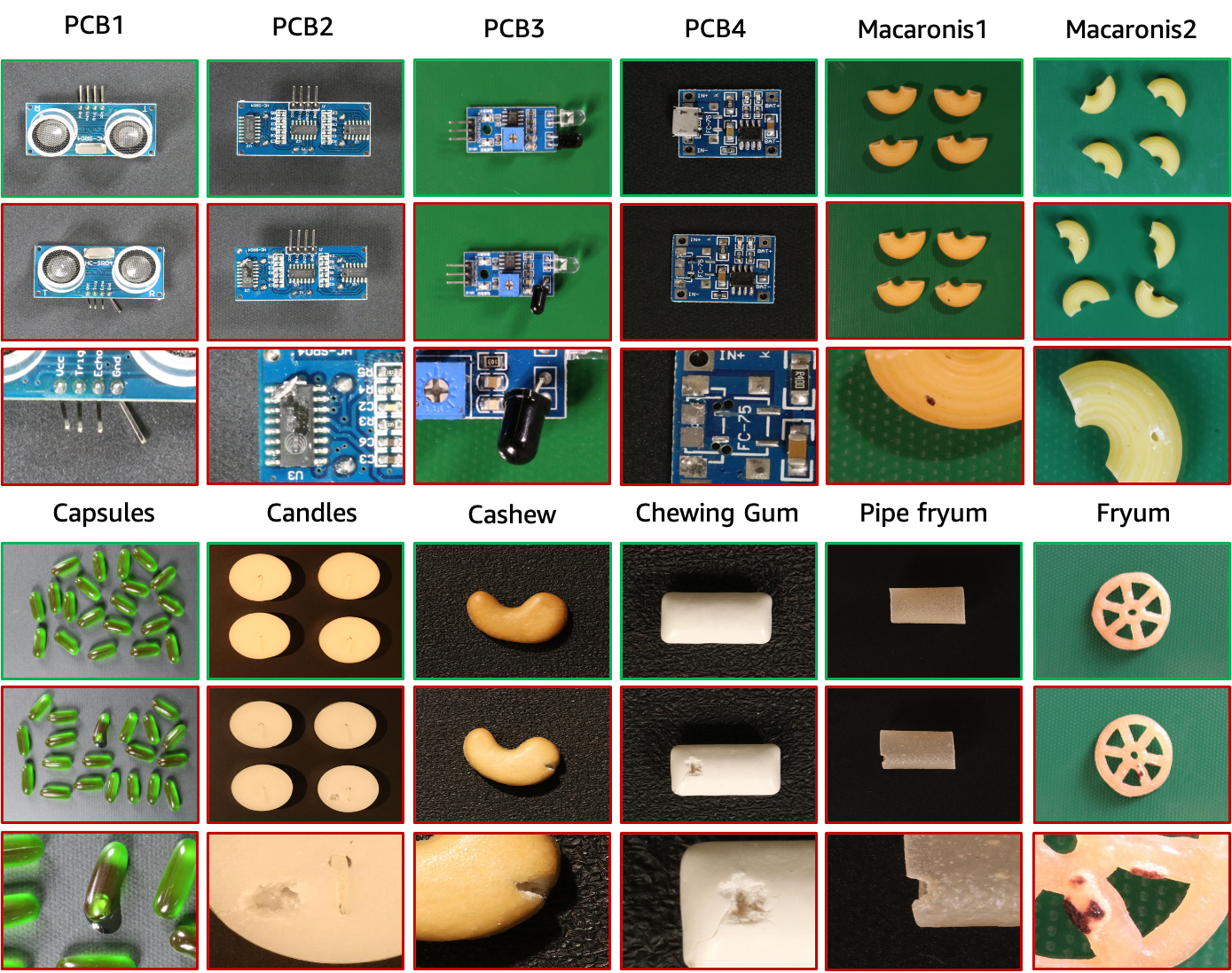
O conjunto de dados VisA contém 12 subconjuntos correspondentes a 12 objetos diferentes, conforme mostrado na figura acima. São 10.821 imagens com 9.621 amostras normais e 1.200 amostras anômalas. Quatro subconjuntos são diferentes tipos de placas de circuito impresso (PCB) com estruturas relativamente complexas contendo transistores, capacitores, chips, etc. Para o caso de múltiplas instâncias em uma visualização, coletamos quatro subconjuntos: Cápsulas, Velas, Macarrão1 e Macarrão2. As instâncias em Cápsulas e Macarrão2 diferem amplamente em locais e poses. Além disso, coletamos quatro subconjuntos, incluindo Caju, Goma de mascar, Fryum e Pipe Fryum, onde os objetos estão aproximadamente alinhados. As imagens anômalas contêm várias falhas, incluindo defeitos superficiais, como arranhões, amassados, manchas coloridas ou rachaduras, e defeitos estruturais, como posicionamento incorreto ou peças faltantes.
| Objeto | # amostras normais | # amostras de anomalia | # classes de anomalia | tipo de objeto |
|---|---|---|---|---|
| PCB1 | 1.004 | 100 | 4 | Estrutura complexa |
| PCB2 | 1.001 | 100 | 4 | Estrutura complexa |
| PCB3 | 1.006 | 100 | 4 | Estrutura complexa |
| PCB4 | 1.005 | 100 | 7 | Estrutura complexa |
| Cápsulas | 602 | 100 | 5 | Várias instâncias |
| Velas | 1.000 | 100 | 8 | Várias instâncias |
| Macarrão1 | 1.000 | 100 | 7 | Várias instâncias |
| Macarrão2 | 1.000 | 100 | 7 | Várias instâncias |
| Caju | 500 | 100 | 9 | Instância única |
| Goma de mascar | 503 | 100 | 6 | Instância única |
| Frium | 500 | 100 | 8 | Instância única |
| Frito de cachimbo | 500 | 100 | 9 | Instância única |
Hospedamos o conjunto de dados VisA no AWS S3 e você pode baixá-lo por este URL.
A árvore de dados dos dados baixados é a seguinte.
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv fornece rótulo em nível de imagem e máscara de anotação em nível de pixel para cada imagem. As funções do mapa id2class para máscaras multiclasse podem ser encontradas em ./utils/id2class.py Aqui, as máscaras para imagens normais não são armazenadas para economizar espaço.
Para preparar as configurações de 1 classe, 2 classes-highshot e 2-class-fewshot descritas no artigo original, usamos ./utils/prepare_data.py para reorganizar os dados seguindo os arquivos de divisão de dados em "./split_csv/" . Fornecemos um exemplo de linha de comando para preparação de configuração de 1 classe como segue.
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
A árvore de dados da configuração reorganizada de 1 classe é a seguinte.
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...Especificamente, os dados reorganizados para configuração de 1 classe seguem a árvore de dados do MVTec-AD. Para cada objeto, os dados possuem três pastas:
Observe que as máscaras de segmentação de verdade básica multiclasse no conjunto de dados original são reindexadas em máscaras binárias onde 0 indica normalidade e 255 indica anomalia.
Além disso, as configurações de 2 classes podem ser preparadas de maneira semelhante, alterando os argumentos de prepare_data.py.
Para calcular métricas de classificação e segmentação, consulte ./utils/metrics.py. Observe que levamos em consideração as amostras normais ao calcular as métricas de localização. Isso é diferente de alguns outros trabalhos que desconsideram as amostras normais na localização.
Cite o seguinte artigo se este conjunto de dados ajudar seu projeto:
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}Os dados são divulgados sob a licença CC BY 4.0.


