Este repositório contém código PyTorch para Motif, treinando agentes de IA no NetHack com funções de recompensa derivadas das preferências de um LLM.
Motivo: Motivação Intrínseca do Feedback da Inteligência Artificial
por Martin Klissarov* e Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang e Mikael Henaff
O Motif extrai as preferências de um Large Language Model (LLM) em pares de observações legendadas de um conjunto de dados de interações coletadas no NetHack. Automaticamente, ele destila o bom senso do LLM em uma função de recompensa que é usada para treinar agentes com aprendizagem por reforço.
Para facilitar as comparações, fornecemos curvas de treinamento no arquivo pickle motif_results.pkl , contendo um dicionário com tarefas como chaves. Para cada tarefa, fornecemos uma lista de intervalos de tempo e retornos médios para Motif e linhas de base, para múltiplas sementes.
Conforme ilustrado na figura a seguir, o Motif apresenta três fases:
Detalhamos cada uma das fases, fornecendo os conjuntos de dados, comandos e resultados brutos necessários para reproduzir os experimentos no artigo.
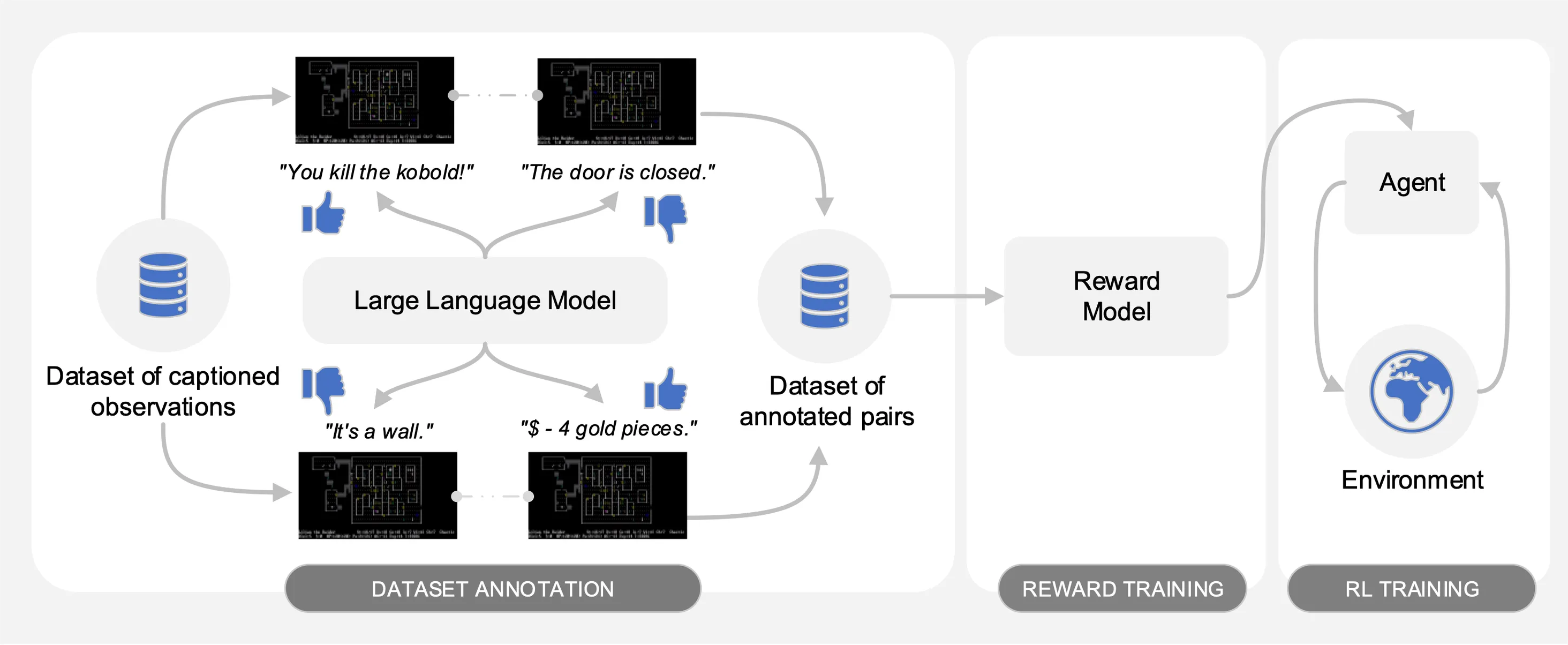
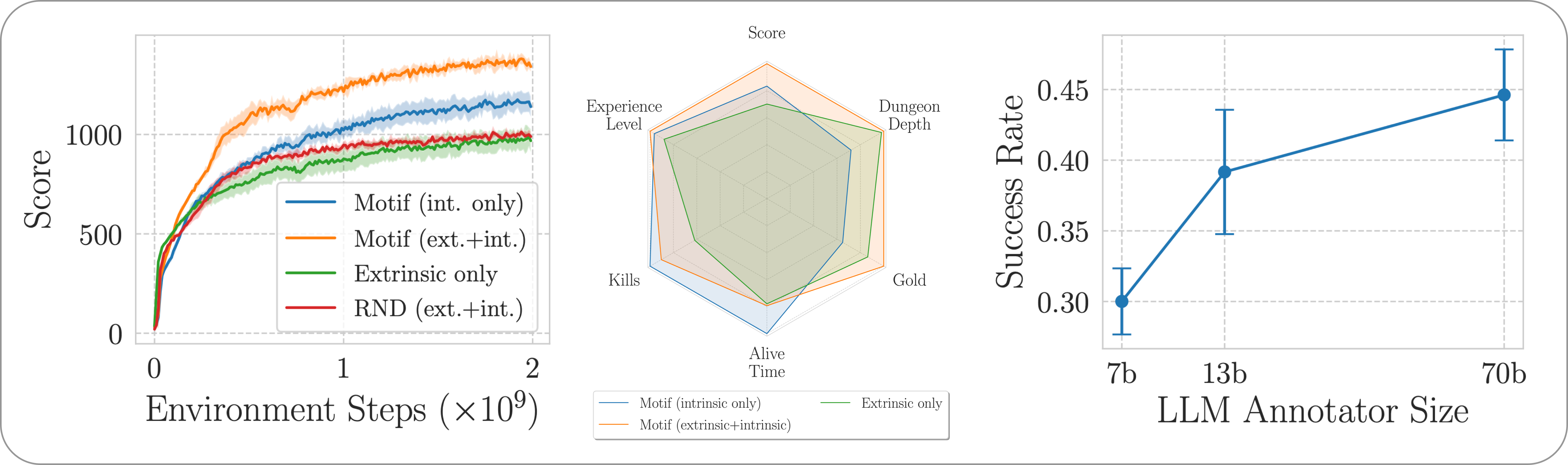
Avaliamos o desempenho do Motif no jogo NetHack desafiador, aberto e gerado processualmente por meio do NetHack Learning Environment. Investigamos como o Motif gera principalmente comportamentos intuitivos alinhados ao humano, que podem ser facilmente controlados por meio de modificações imediatas, bem como suas propriedades de escala.

Para instalar as dependências necessárias para todo o pipeline, basta executar pip install -r requirements.txt .
Para a primeira fase, utilizamos um conjunto de dados de pares de observações com legendas (ou seja, mensagens do jogo) coletados por agentes treinados com aprendizagem por reforço para maximizar a pontuação do jogo. Fornecemos o conjunto de dados neste repositório. Armazenamos as diferentes partes no diretório motif_dataset_zipped , que pode ser descompactado usando o seguinte comando.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
O conjunto de dados que fornecemos apresenta um conjunto de preferências fornecidas pelos modelos Llama 2, contidas no diretório preference/ , usando os diferentes prompts descritos no artigo. Os nomes dos arquivos .npy contendo as anotações seguem o modelo llama{size}b_msg_{instruction}_{version} , onde size é um tamanho LLM do conjunto {7,13,70} , instruction é uma instrução introduzida no prompt fornecido ao LLM do conjunto {defaultgoal, zeroknowledge, combat, gold, stairs} , version é a versão do modelo de prompt a ser usado no conjunto {default, reworded} . Aqui fornecemos um resumo das anotações disponíveis:
| Anotação | Caso de uso do papel |
|---|---|
llama70b_msg_defaultgoal_default | Experimentos principais |
llama70b_msg_combat_default | Direcionando para o comportamento do Monster Slayer |
llama70b_msg_gold_default | Orientando-se para o comportamento do Colecionador de Ouro |
llama70b_msg_stairs_default | Direcionando para o comportamento do Descendente |
llama7b_msg_defaultgoal_default | Experimento de dimensionamento |
llama13b_msg_defaultgoal_default | Experimento de dimensionamento |
llama70b_msg_zeroknowledge_default | Experimento imediato de conhecimento zero |
llama70b_msg_defaultgoal_reworded | Experimento de reformulação imediata |
Para criar as anotações, usamos o vLLM e a versão chat do Llama 2. se você deseja gerar suas próprias anotações com o Llama 2 ou reproduzir nosso processo de anotação, certifique-se de baixar o modelo seguindo as instruções oficiais (pode demorar alguns dias para ter acesso aos pesos do modelo).
O script de anotação assume que o conjunto de dados será anotado em partes diferentes usando o argumento n-annotation-chunks . Isso permite um processo que pode ser paralelizado dependendo da disponibilidade de recursos e é robusto para reinicializações/preempção. Para executar com um único bloco (ou seja, para processar todo o conjunto de dados) e anotar com o modelo de prompt padrão e a especificação de tarefa, execute o comando a seguir.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
Observe que o comportamento padrão retoma o processo de anotação anexando as anotações ao arquivo que especifica a configuração, a menos que indicado de outra forma com o sinalizador --ignore-existing . O nome do arquivo '.npy' criado para as anotações também pode ser selecionado manualmente usando o sinalizador --custom-annotator-string . É possível anotar usando --llm-size 7 e --llm-size 13 usando uma única GPU com 32 GB de memória. Você pode anotar usando --llm-size 70 com um nó de 8 GPUs. Fornecemos aqui estimativas aproximadas de tempos de anotação com GPUs NVIDIA V100s 32G, para um conjunto de dados de 100 mil pares, que deve ser capaz de reproduzir aproximadamente a maioria de nossos resultados (que são obtidos com 500 mil pares).
| Modelo | Recursos para anotar |
|---|---|
| Lhama 2 7b | ~32 horas de GPU |
| Lhama 2 13b | ~40 horas de GPU |
| Lhama 2 70b | ~72 horas de GPU |
Na segunda fase, destilamos as preferências do LLM numa função de recompensa através da entropia cruzada. Para iniciar o treinamento de recompensa com hiperparâmetros padrão, use o seguinte comando.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
A função de recompensa será treinada por meio das anotações do annotator localizado em --dataset_dir . A função resultante será salva em train_dir na subpasta --experiment .
Finalmente, treinamos um agente com as funções de recompensa resultantes através da aprendizagem por reforço. Para treinar um agente na tarefa NetHackScore-v1 , com os hiperparâmetros padrão empregados para experimentos que combinam recompensas intrínsecas e extrínsecas, você pode usar o comando a seguir.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
Para alterar a tarefa, simplesmente modifique o argumento --root_env . A tabela a seguir indica explicitamente os valores necessários para corresponder aos experimentos apresentados no artigo. A tarefa NetHackScore-v1 é aprendida com o valor extrinsic_reward igual a 0.1 , enquanto todas as outras tarefas assumem o valor 10.0 , a fim de incentivar o agente a atingir a meta.
| Ambiente | root_env |
|---|---|
| pontuação | NetHackScore-v1 |
| escadaria | NetHackStaircase-v1 |
| escada (nível 3) | NetHackStaircaseLvl3-v1 |
| escada (nível 4) | NetHackStaircaseLvl4-v1 |
| oráculo | NetHackOracle-v1 |
| oráculo sóbrio | NetHackOracleSober-v1 |
Além disso, se você quiser treinar agentes usando apenas a recompensa intrínseca proveniente do LLM, mas nenhuma recompensa do ambiente, basta definir --extrinsic_reward 0.0 . Nos experimentos intrínsecos somente de recompensa, encerramos o episódio apenas se o agente morrer, e não quando o agente atingir a meta. Esses ambientes modificados são enumerados na tabela a seguir.
| Ambiente | root_env |
|---|---|
| escada (nível 3) - apenas intrínseca | NetHackStaircaseLvl3Continual-v1 |
| escada (nível 4) - apenas intrínseca | NetHackStaircaseLvl4Continual-v1 |
Além disso, fornecemos um script para visualizar seus agentes RL treinados. Isso pode fornecer informações importantes sobre seu comportamento, mas também gerará as principais mensagens para cada episódio, o que pode ajudar a entender o que ele está tentando otimizar. Você simplesmente precisa executar o seguinte comando.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
Se você desenvolver nosso trabalho ou considerá-lo útil, cite-o usando o seguinte bibtex.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
A maior parte do Motif é licenciada sob CC-BY-NC, no entanto, partes do projeto estão disponíveis sob termos de licença separados: sample-factory é licenciado sob a licença do MIT.


