

MPIRE , abreviação de MultiProcessing Is Really Easy, é um pacote Python para multiprocessamento. MPIRE é mais rápido na maioria dos cenários, inclui mais recursos e geralmente é mais fácil de usar do que o pacote de multiprocessamento padrão. Ele combina as funções convenientes do tipo mapa de multiprocessing.Pool com os benefícios do uso de objetos compartilhados copy-on-write de multiprocessing.Process , juntamente com estado de trabalhador fácil de usar, insights de trabalhador, funções de inicialização e saída de trabalhador, tempos limite e funcionalidade da barra de progresso.
A documentação completa está disponível em https://sybrenjansen.github.io/mpire/.
map / map_unordered / imap / imap_unordered / apply / apply_asyncfork )rich e de notebook são suportados)daemonMPIRE é testado em Linux, macOS e Windows. Para usuários de Windows e macOS, existem algumas pequenas advertências conhecidas, que estão documentadas no capítulo Solução de problemas.
Através do pip (PyPi):
pip install mpireMPIRE também está disponível através do conda-forge:
conda install -c conda-forge mpire Suponha que você tenha uma função demorada que recebe alguma entrada e retorna seus resultados. Funções simples como essas são conhecidas como problemas embaraçosamente paralelos, funções que requerem pouco ou nenhum esforço para se transformarem em uma tarefa paralela. Paralelizar uma função simples como essa pode ser tão fácil quanto importar multiprocessing e usar a classe multiprocessing.Pool :
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) O MPIRE pode ser usado quase como um substituto imediato do multiprocessing . Usamos a classe mpire.WorkerPool e chamamos uma das funções map disponíveis:
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) As diferenças no código são pequenas: não há necessidade de aprender uma sintaxe de multiprocessamento completamente nova, se você estiver acostumado com multiprocessing básico. A funcionalidade adicional disponível, porém, é o que diferencia o MPIRE.
Suponha que queiramos saber o status da tarefa atual: quantas tarefas foram concluídas, quanto tempo leva para o trabalho estar pronto? É tão simples quanto definir o parâmetro progress_bar como True :
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )E produzirá uma barra de progresso tqdm bem formatada.
O MPIRE também oferece um painel, para o qual é necessário instalar dependências adicionais. Consulte Painel para obter mais informações.
Nota: Os objetos compartilhados de cópia na gravação estão disponíveis apenas para o método start fork . Para threading os objetos são compartilhados como estão. Para outros métodos de início, os objetos compartilhados são copiados uma vez para cada trabalhador, o que ainda pode ser melhor do que uma vez por tarefa.
Se você tiver um ou mais objetos que deseja compartilhar entre todos os trabalhadores, poderá usar a opção copy-on-write shared_objects do MPIRE. O MPIRE repassará esses objetos apenas uma vez para cada trabalhador sem cópia/serialização. Somente quando você alterar o objeto na função de trabalho ele começará a copiá-lo para aquele trabalhador.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Consulte shared_objects para obter mais detalhes.
Os trabalhadores podem ser inicializados usando o recurso worker_init . Junto com worker_state você pode carregar um modelo ou configurar uma conexão de banco de dados, etc.:
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) Da mesma forma, você pode usar o recurso worker_exit para permitir que o MPIRE chame uma função sempre que um trabalhador terminar. Você pode até deixar que esta função de saída retorne resultados, que podem ser obtidos posteriormente. Consulte a seção trabalhador_init e trabalhador_exit para obter mais informações.
Quando sua configuração de multiprocessamento não está funcionando como você deseja e você não tem ideia do que está causando isso, existe a funcionalidade de insights do trabalhador. Isso lhe dará informações sobre sua configuração, mas não criará um perfil da função que você está executando (existem outras bibliotecas para isso). Em vez disso, ele traça o perfil do tempo de inicialização do trabalhador, do tempo de espera e do tempo de trabalho. Quando as funções de inicialização e saída do trabalhador são fornecidas, elas também serão cronometradas.
Talvez você esteja enviando muitos dados pela fila de tarefas, o que aumenta o tempo de espera. Seja qual for o caso, você pode ativar e obter os insights usando o sinalizador enable_insights e a função mpire.WorkerPool.get_insights , respectivamente:
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()Consulte os insights dos trabalhadores para obter um exemplo mais detalhado e o resultado esperado.
Os tempos limite podem ser definidos separadamente para as funções target, worker_init e worker_exit . Quando um tempo limite for definido e atingido, um TimeoutError será lançado:
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) Ao usar threading como método inicial, o MPIRE não será capaz de interromper certas funções, como time.sleep .
Consulte os tempos limite para obter mais detalhes.
O MPIRE foi avaliado em três benchmarks diferentes: computação numérica, computação com estado e inicialização cara. Mais detalhes sobre esses benchmarks podem ser encontrados nesta postagem do blog. Todo o código para esses benchmarks pode ser encontrado neste projeto.
Resumindo, as principais razões pelas quais o MPIRE é mais rápido são:
fork está disponível, podemos usar objetos compartilhados copy-on-write, o que reduz a necessidade de copiar objetos que precisam ser compartilhados em processos filhos.O gráfico a seguir mostra os resultados médios normalizados de todos os três benchmarks. Os resultados de benchmarks individuais podem ser encontrados na postagem do blog. Os benchmarks foram executados em uma máquina Linux com 20 núcleos, com hyperthreading desabilitado e 200GB de RAM. Para cada tarefa, experimentos foram executados com diferentes números de processos/trabalhadores e os resultados foram calculados em média em 5 execuções.
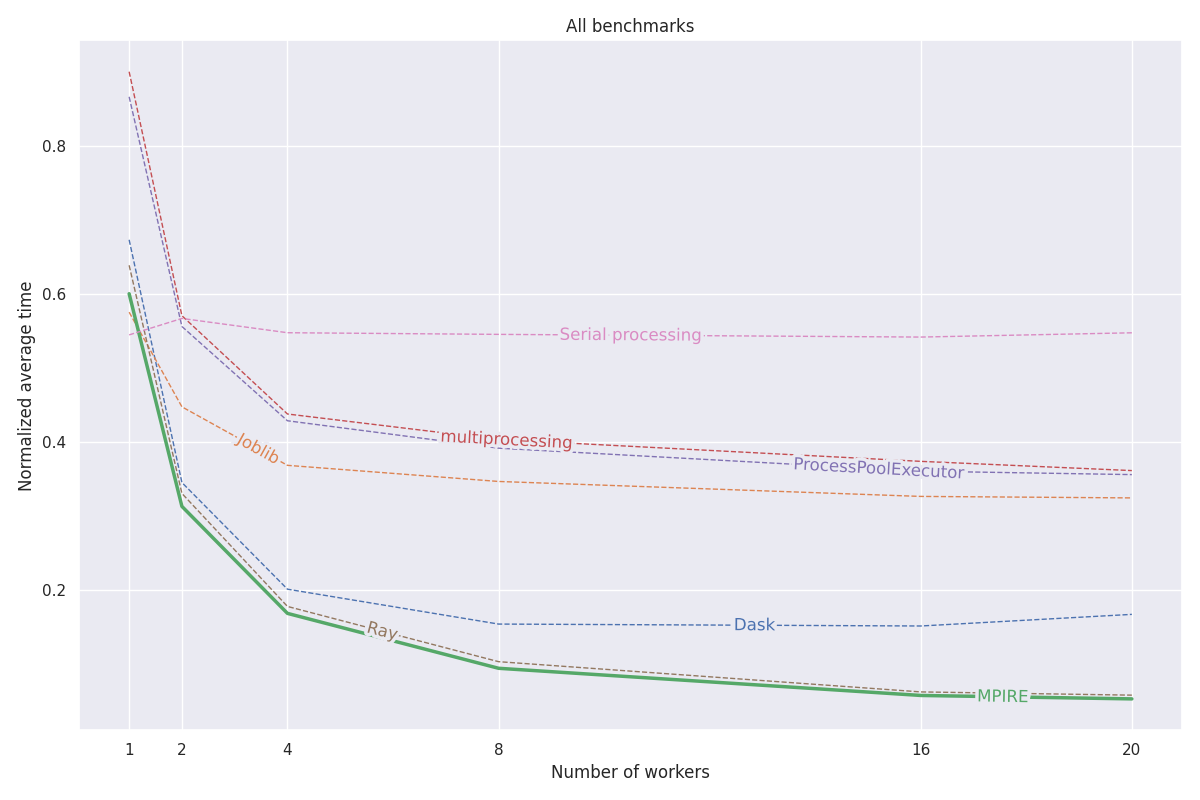
Consulte a documentação completa em https://sybrenjansen.github.io/mpire/ para obter informações sobre todos os outros recursos do MPIRE.
Se você quiser construir a documentação sozinho, instale as dependências da documentação executando:
pip install mpire[docs]ou
pip install .[docs]A documentação pode então ser construída usando Python <= 3.9 e executando:
python setup.py build_docs A documentação também pode ser criada diretamente da pasta docs . Nesse caso, MPIRE deverá estar instalado e disponível no seu ambiente de trabalho atual. Em seguida, execute:
make html na pasta docs .


