clearml agent
v1.9.2

Agente ClearML - MLOps/LLMOps facilitados
Solução de orquestração e agendador MLOps/LLMOps com suporte para Linux, macOS e Windows
? ClearML is open-source - Leave a star to support the project! ?
É um agente de execução do tipo "dispare e esqueça" de configuração zero, fornecendo uma solução completa de cluster ML/DL.
Automação completa em 5 passos
pip install clearml-agent (instale o agente ClearML em qualquer máquina GPU: local/nuvem/...)"Todos os DevOps de Deep/Machine Learning que sua pesquisa precisa, e mais alguns... Porque ninguém tem tempo para isso"
Experimente ClearML agora, hospedagem auto-hospedada ou de nível gratuito 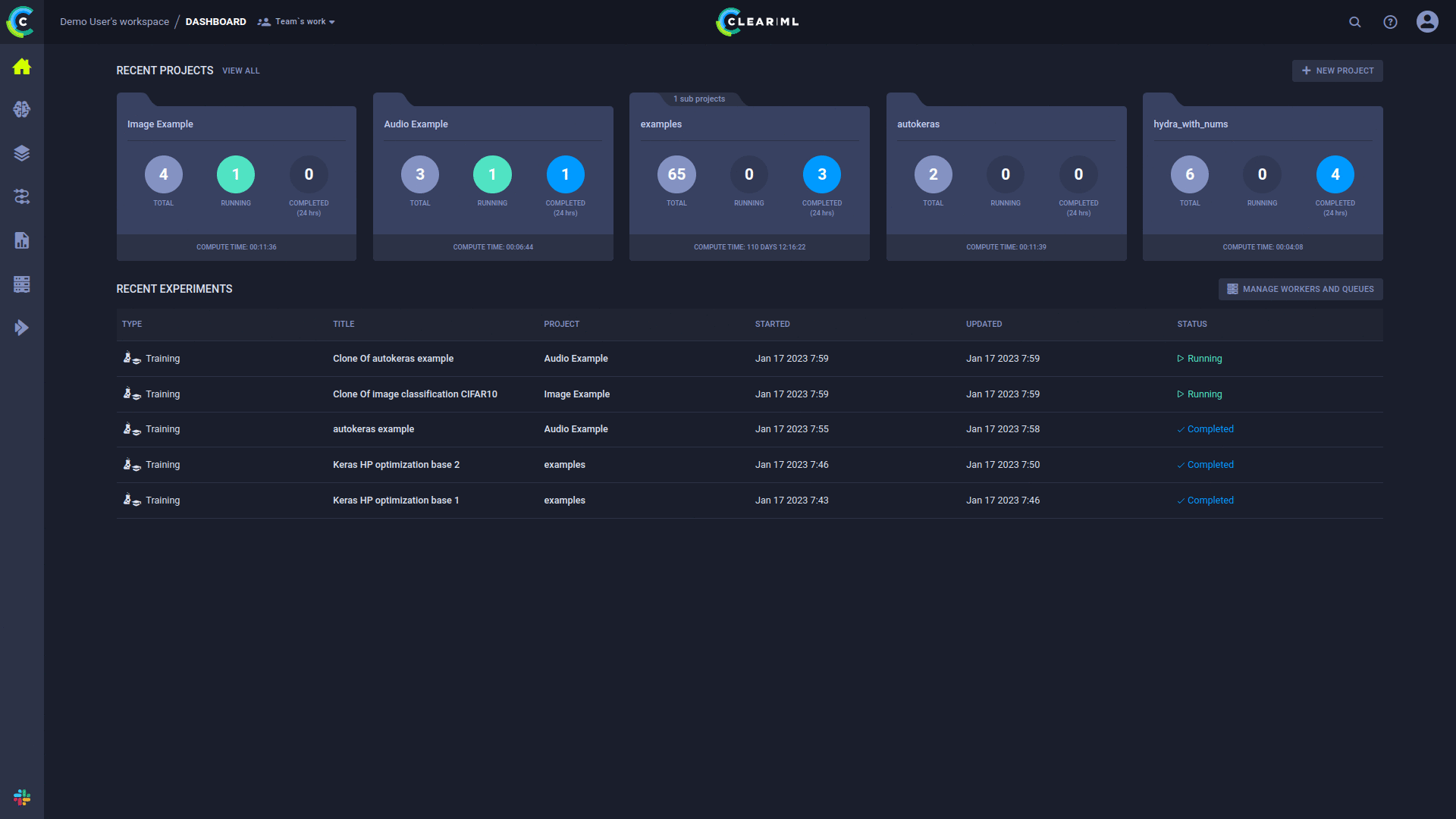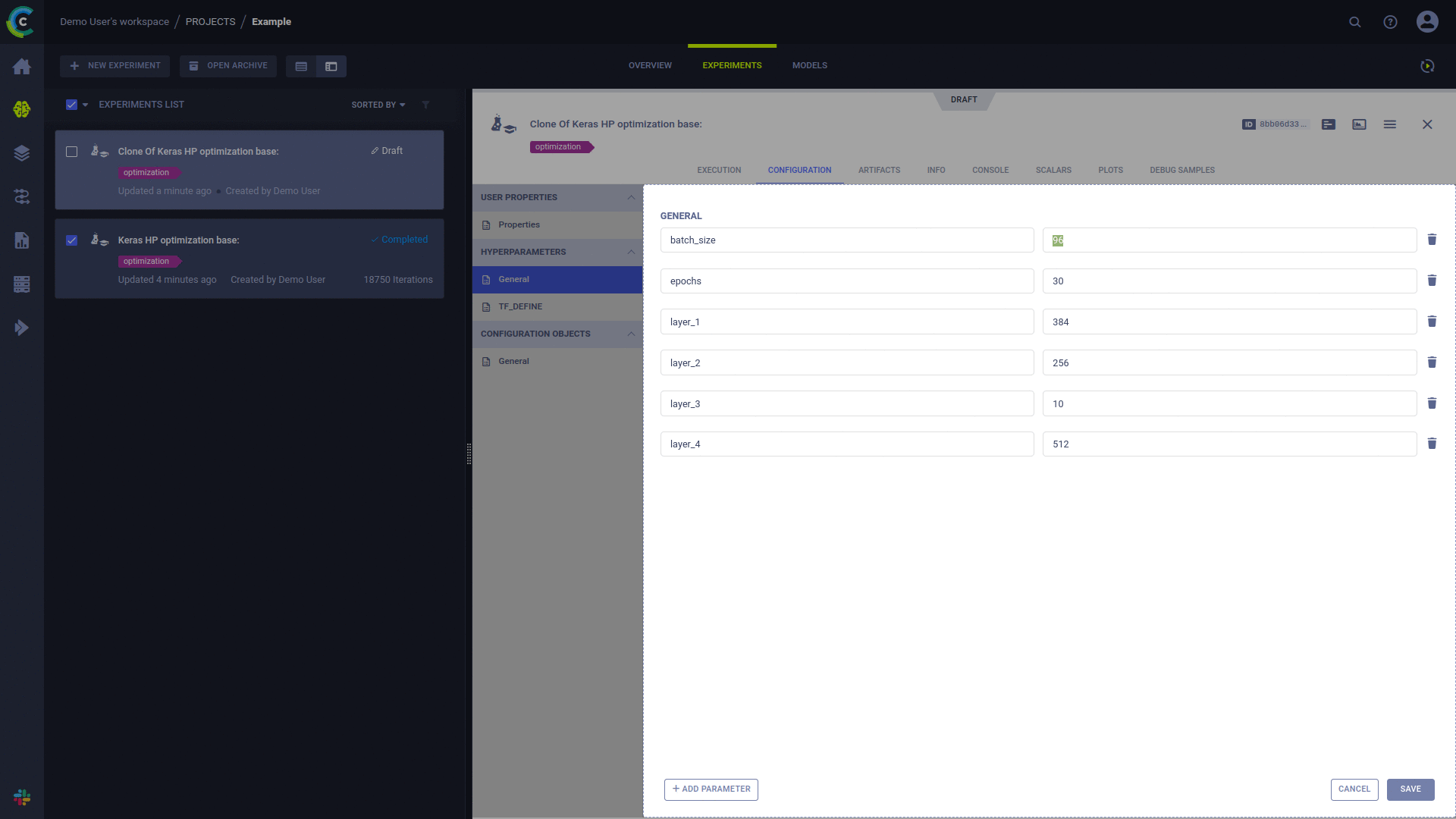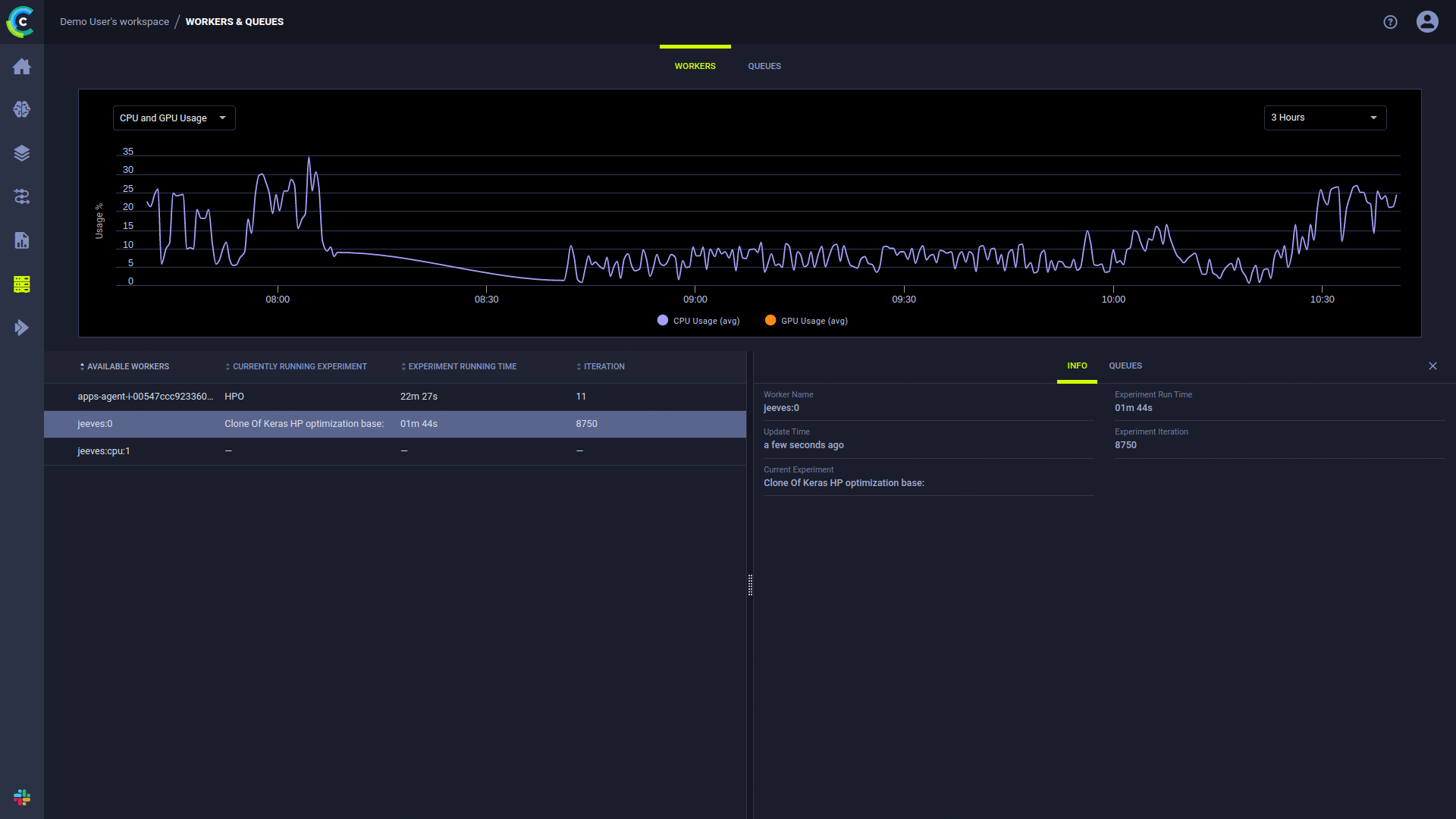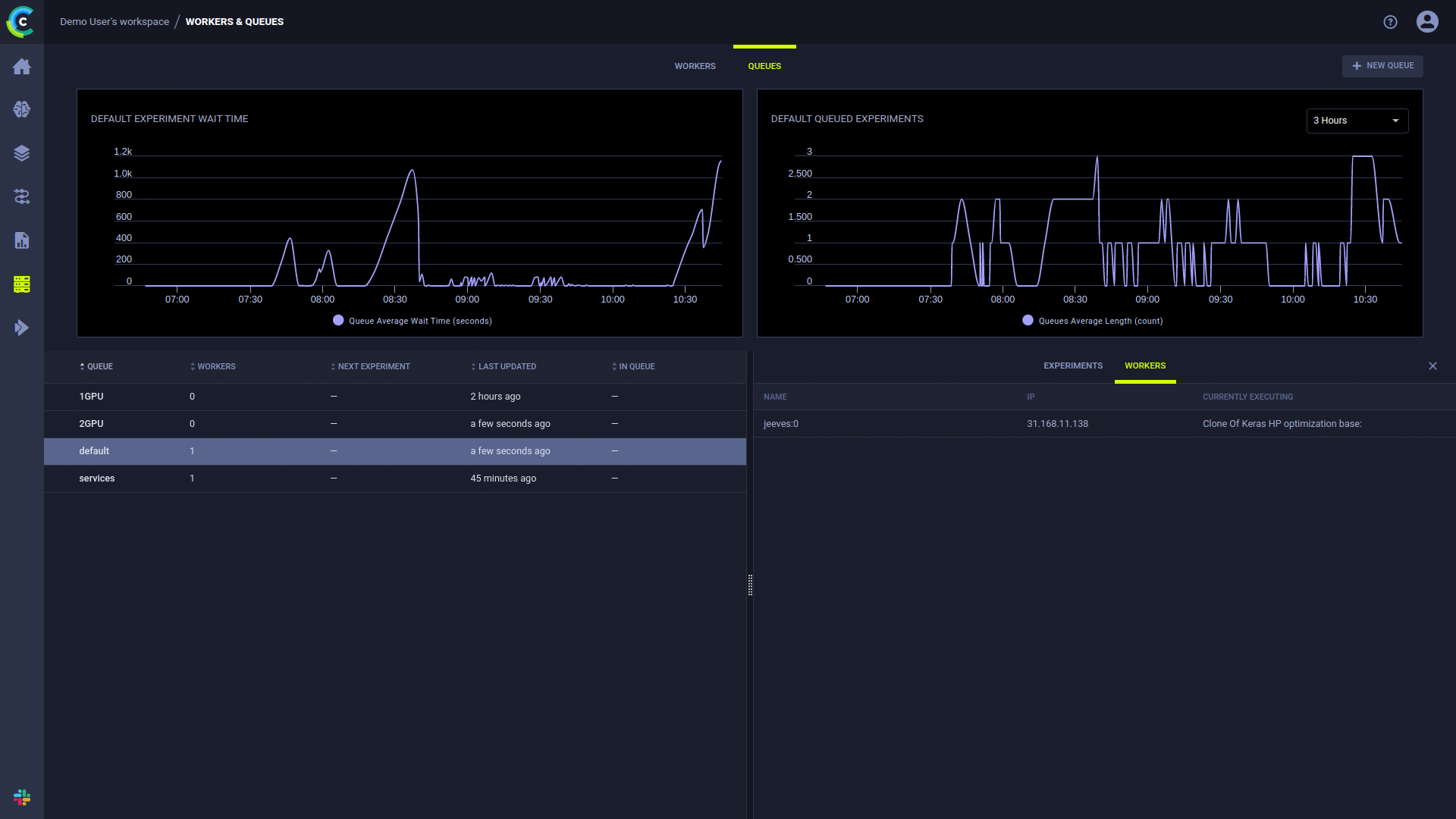
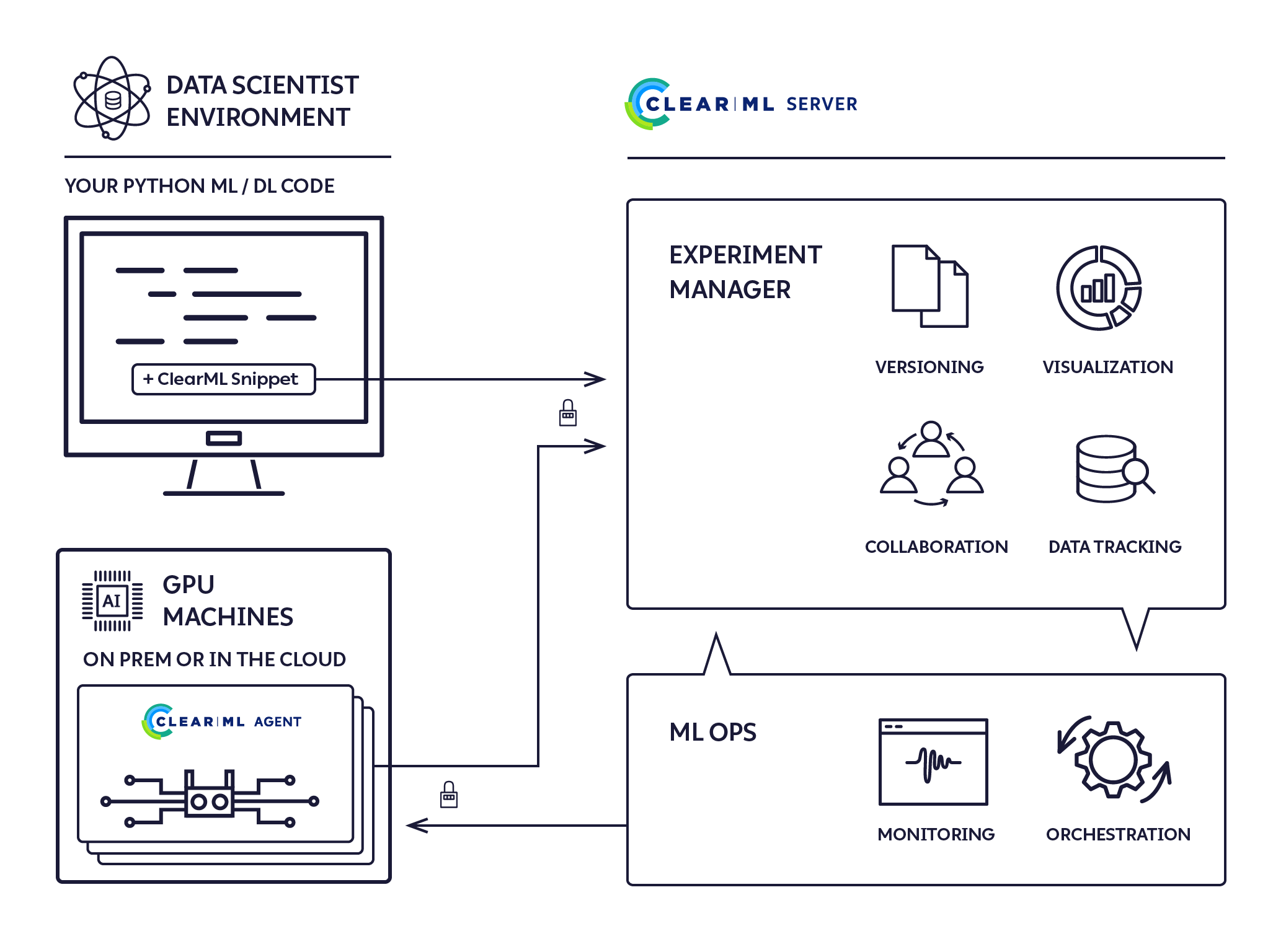
O ClearML Agent foi criado para atender às necessidades de DevOps de P&D de DL/ML:
Usando o ClearML Agent, agora você pode configurar um cluster dinâmico com *epsilon DevOps
*épsilon - Porque nós somos? e nada é realmente zero trabalho
Achamos que o Kubernetes é incrível, mas não é obrigatório começar com agentes de execução remota e gerenciamento de cluster. Projetamos clearml-agent para que você possa executar bare metal e em cima do Kubernetes, em qualquer combinação adequada ao seu ambiente.
Você pode encontrar os Dockerfiles na pasta docker e o gráfico do leme em https://github.com/allegroai/clearml-helm-charts
Execute o agente no modo Kubernetes Glue e mapeie os trabalhos ClearML diretamente para os trabalhos K8s:
Sim! A integração Slurm está disponível, verifique a documentação para mais detalhes
HPC em escala real com o clique de um botão
O ClearML Agent é um agendador de trabalhos que escuta fila(s) de trabalhos, extrai trabalhos, define os ambientes de trabalho, executa o trabalho e monitora seu progresso.
Qualquer experimento 'Rascunho' pode ser agendado para execução por um agente ClearML.
Um experimento executado anteriormente pode ser colocado no estado 'Rascunho' por um dos dois métodos:
Um experimento é agendado para execução usando a ação 'Enfileirar' no menu de contexto do experimento com o botão direito do mouse na UI do ClearML e selecionando a fila de execução.
Consulte criar uma experiência e enfileirá-la para execução.
Depois que um experimento for enfileirado, ele será selecionado e executado por um agente ClearML que monitora essa fila.
A página ClearML UI Workers & Queues fornece informações de execução contínua:
O Agente ClearML executa experimentos usando o seguinte processo:
pip install clearml-agentInterface completa e recursos estão disponíveis com
clearml-agent --help
clearml-agent daemon --helpclearml-agent init Nota: O Agente ClearML usa uma pasta de cache para armazenar em cache pacotes pip, pacotes apt e repositórios clonados. A pasta de cache padrão do ClearML Agent é ~/.clearml .
Veja detalhes completos em seu arquivo de configuração em ~/clearml.conf .
Nota: O ClearML Agent estende o arquivo de configuração ClearML ~/clearml.conf . Eles são projetados para compartilhar o mesmo arquivo de configuração, veja o exemplo aqui
Para depuração e experimentação, inicie o agente ClearML no modo foreground , onde toda a saída é impressa na tela:
clearml-agent daemon --queue default --foreground Para o modo de serviço real, todo o stdout será armazenado automaticamente em um arquivo temporário (sem necessidade de pipe). Aviso: com o sinalizador --detached , o agente clearml estará sendo executado em segundo plano
clearml-agent daemon --detached --queue default A alocação de GPU é controlada por meio do ambiente de sistema operacional padrão NVIDIA_VISIBLE_DEVICES ou sinalizador --gpus (ou desabilitado com --cpu-only ).
Se nenhum sinalizador for definido e a variável NVIDIA_VISIBLE_DEVICES não existir, todas as GPUs serão alocadas para o clearml-agent .
Se o sinalizador --cpu-only estiver definido ou NVIDIA_VISIBLE_DEVICES="none" , nenhuma GPU será alocada para o clearml-agent .
Exemplo: gire dois agentes, um por GPU na mesma máquina:
Aviso: com o sinalizador --detached , o agente clearml será executado em segundo plano
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default Exemplo: girar dois agentes, extraindo da fila dual_gpu dedicada, duas GPUs por agente
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu Para depuração e experimentação, inicie o agente ClearML no modo foreground , onde toda a saída é impressa na tela
clearml-agent daemon --queue default --docker --foreground Para o modo de serviço real, todo o stdout será armazenado automaticamente em um arquivo (sem necessidade de pipe). Aviso: com o sinalizador --detached , o agente clearml será executado em segundo plano
clearml-agent daemon --detached --queue default --docker Exemplo: gire dois agentes, um por GPU na mesma máquina, com nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 docker padrão:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 Exemplo: gire dois agentes, extraindo da fila dual_gpu dedicada, duas GPUs por agente, com nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 docker padrão:
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04Filas prioritárias também são suportadas, exemplo de caso de uso:
Fila de alta prioridade: important_jobs , fila de baixa prioridade: default
clearml-agent daemon --queue important_jobs default O agente ClearML primeiro tentará extrair trabalhos da fila important_jobs e somente se estiver vazia, o agente tentará extrair da fila default .
Adicionar filas, gerenciar pedidos de trabalho dentro de uma fila e mover trabalhos entre filas está disponível usando a UI da Web, veja o exemplo em nosso servidor gratuito
Para interromper a execução de um agente ClearML em segundo plano, execute a mesma linha de comando usada para iniciar o agente com --stop anexado. Por exemplo, para parar a primeira das mesmas máquinas mostradas acima, agentes de GPU únicos:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopIntegre ClearML ao seu código
Execute o código em sua máquina (Manualmente/PyCharm/Jupyter Notebook)
Enquanto seu código está em execução, o ClearML cria um experimento registrando todas as informações de execução necessárias:
Agora você tem um 'modelo' do seu experimento com tudo o que é necessário para a execução automatizada
Na UI do ClearML, clique com o botão direito no experimento e selecione 'clone'. Uma cópia da sua experiência será criada.
Agora você tem um novo rascunho de experimento clonado de seu experimento original. Sinta-se à vontade para editá-lo
Agende a experiência recém-criada para execução: clique com o botão direito na experiência e selecione 'enfileirar'
ClearML-Agent Services é um modo especial de ClearML-Agent que fornece a capacidade de iniciar trabalhos de longa duração que antes precisavam ser executados em máquinas locais/dedicadas. Ele permite que um único agente inicie vários dockers (tarefas) para diferentes casos de uso:
O modo ClearML-Agent Services irá girar qualquer tarefa enfileirada na fila especificada. Cada tarefa lançada pelo ClearML-Agent Services será registrada como um novo nó no sistema, fornecendo recursos de rastreamento e transparência. Atualmente, o clearml-agent no modo de serviço oferece suporte apenas à configuração da CPU. O modo de serviços ClearML-Agent pode ser iniciado junto com os agentes GPU.
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-onlyNota : É responsabilidade do usuário garantir que as tarefas adequadas sejam colocadas na fila especificada.
O agente ClearML também pode ser usado para implementar orquestração AutoML e pipelines de experimentos em conjunto com o pacote ClearML.
Exemplos de exemplos de AutoML e orquestração podem ser encontrados na pasta exemplo/automação do ClearML.
Exemplos de AutoML:
Exemplos de pipeline de experimentos:
Licença Apache, versão 2.0 (consulte a LICENÇA para obter mais informações)


