FlagEmbedding
1.3.2


Notícias | Instalação | Início rápido | Comunidade | Projetos | Lista de modelos | Colaborador | Citação | Licença
Inglês | 中文
BGE (BAAI General Embedding) concentra-se em LLMs com recuperação aumentada, consistindo atualmente nos seguintes projetos:
29/10/2024: ? Criamos o grupo WeChat para BGE. Digitalize o código QR para entrar no chat em grupo! Para receber a mensagem em primeira mão sobre nossas atualizações e novos lançamentos, ou se tiver alguma dúvida ou ideia, junte-se a nós agora!

22/10/2024: Lançamos outro modelo interessante: OmniGen, que é um modelo unificado de geração de imagens que suporta diversas tarefas. OmniGen pode realizar tarefas complexas de geração de imagens sem a necessidade de plug-ins adicionais como ControlNet, adaptador IP ou modelos auxiliares como detecção de pose e detecção de rosto.
10/09/2024: Apresentando o MemoRAG , um passo em direção ao RAG 2.0 além da descoberta de conhecimento inspirada na memória (repo: https://github.com/qhjqhj00/MemoRAG, artigo: https://arxiv.org/pdf/ 2409.05591v1)
02/09/2024: Início da manutenção dos tutoriais. O conteúdo será atualizado e acessado ativamente, fique ligado!
26/07/2024: Lançar um novo modelo de incorporação bge-en-icl, um modelo de incorporação que incorpora recursos de aprendizagem no contexto, que, ao fornecer exemplos de consulta-resposta relevantes para tarefas, pode codificar consultas semanticamente mais ricas, aprimorando ainda mais a semântica capacidade de representação dos embeddings.
26/07/2024: Lançar um novo modelo de incorporação bge-multilingual-gemma2, um modelo de incorporação multilíngue baseado em gemma-2-9b, que suporta vários idiomas e diversas tarefas downstream, alcançando novo SOTA em benchmarks multilíngues (MIRACL, MTEB-fr e MTEB-pl).
26/07/2024: Lançar um novo reclassificador leve bge-reranker-v2.5-gemma2-lightweight, um reclassificador leve baseado em gemma-2-9b, que suporta compactação de token e operações leves em camadas, ainda pode garantir um bom desempenho enquanto salva uma quantidade significativa de recursos.
BAAI/bge-reranker-base e BAAI/bge-reranker-large , que são mais poderosos do que o modelo de incorporação. Recomendamos usá-los/ajustá-los para reclassificar os principais documentos retornados pela incorporação de modelos.bge-*-v1.5 para aliviar o problema da distribuição de similaridade e aprimorar sua capacidade de recuperação sem instrução.bge-large-* (abreviação de BAAI General Embedding), classificação em 1º lugar no benchmark MTEB e C-MTEB! ? ?Se não quiser fazer o ajuste fino dos modelos, você pode instalar o pacote sem a dependência do ajuste fino:
pip install -U FlagEmbedding
Se quiser ajustar os modelos, você pode instalar o pacote com a dependência de ajuste fino:
pip install -U FlagEmbedding[finetune]
Clone o repositório e instale
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
Para desenvolvimento em modo editável:
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
Primeiro, carregue um dos modelos de incorporação BGE:
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
Em seguida, alimente algumas frases ao modelo e obtenha seus embeddings:
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
Depois de obtermos os embeddings, podemos calcular a similaridade por produto interno:
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
Para obter mais detalhes, você pode consultar inferência do incorporador, inferência do reclassificador, ajuste fino do incorporador, ajuste do reclassificador, avaliação.
Se você não estiver familiarizado com algum dos conceitos relacionados, confira o tutorial. Se não estiver lá, avise-nos.
Para tópicos mais interessantes relacionados ao BGE, dê uma olhada na pesquisa.
Estamos mantendo ativamente a comunidade BGE e FlagEmbedding. Deixe-nos saber se você tem alguma sugestão ou ideia!
Atualmente estamos atualizando os tutoriais, pretendemos criar um tutorial abrangente e detalhado para iniciantes em recuperação de texto e RAG. Fique atento!
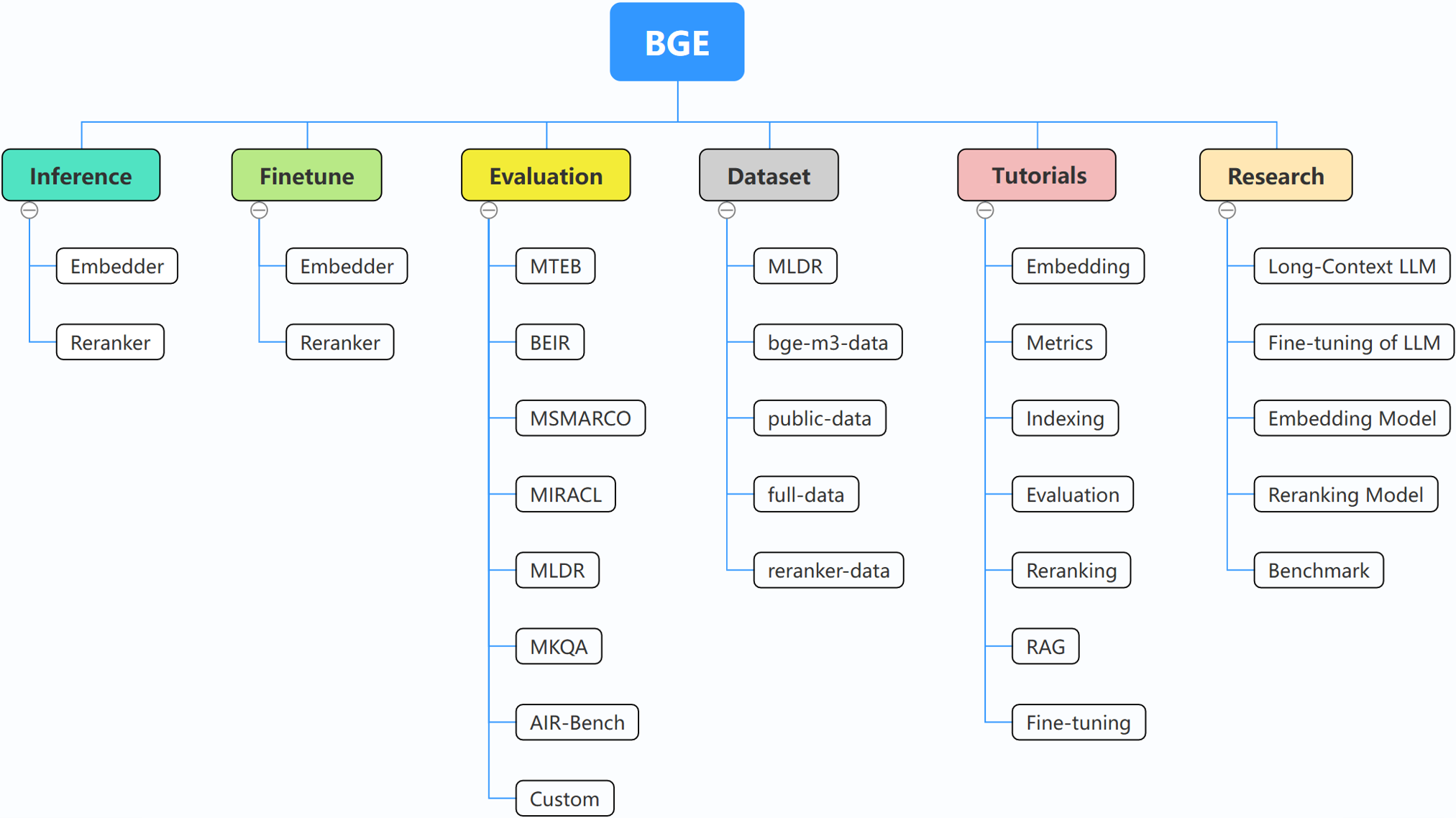
Os seguintes conteúdos serão lançados nas próximas semanas:
bge é a abreviatura de BAAI general embedding .
| Modelo | Linguagem | Descrição | instrução de consulta para recuperação |
|---|---|---|---|
| BAAI/bge-en-icl | Inglês | Um modelo de incorporação baseado em LLM com recursos de aprendizagem no contexto, que pode aproveitar totalmente o potencial do modelo com base em alguns exemplos | Forneça instruções e exemplos rápidos livremente com base na tarefa determinada. |
| BAAI/bge-multilíngue-gemma2 | Multilíngue | Um modelo de incorporação multilíngue baseado em LLM, treinado em uma ampla variedade de idiomas e tarefas. | Forneça instruções com base na tarefa determinada. |
| BAAI/bge-m3 | Multilíngue | Multifuncionalidade (recuperação densa, recuperação esparsa, multivetor (colbert)), multilingualidade e multigranulação (8192 tokens) | |
| Coquetel LM | Inglês | modelos ajustados (Llama e BGE) que podem ser usados para reproduzir os resultados do LM-Cocktail | |
| Incorporador BAAI/llm | Inglês | um modelo de incorporação unificado para suportar diversas necessidades de aumento de recuperação para LLMs | Veja LEIA-ME |
| BAAI/bge-reranker-v2-m3 | Multilíngue | um modelo leve de codificador cruzado, possui fortes recursos multilíngues, fácil de implantar e com inferência rápida. | |
| BAAI/bge-reranker-v2-gemma | Multilíngue | um modelo de codificação cruzada adequado para contextos multilíngues, com bom desempenho tanto na proficiência em inglês quanto nas capacidades multilíngues. | |
| BAAI/bge-reranker-v2-minicpm-layerwise | Multilíngue | um modelo de codificador cruzado adequado para contextos multilíngues, com bom desempenho em proficiência em inglês e chinês, permite liberdade para selecionar camadas para saída, facilitando a inferência acelerada. | |
| BAAI/bge-reranker-v2.5-gemma2-lightweight | Multilíngue | um modelo de codificador cruzado adequado para contextos multilíngues, com bom desempenho em proficiência em inglês e chinês, permite liberdade para selecionar camadas, taxa de compactação e camadas de compactação para saída, facilitando a inferência acelerada. | |
| BAAI/bge-reclassificador-grande | Chinês e Inglês | um modelo de codificador cruzado que é mais preciso, mas menos eficiente | |
| BAAI/bge-reclassificador-base | Chinês e Inglês | um modelo de codificador cruzado que é mais preciso, mas menos eficiente | |
| BAAI/bge-large-pt-v1.5 | Inglês | versão 1.5 com distribuição de similaridade mais razoável | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-pt-v1.5 | Inglês | versão 1.5 com distribuição de similaridade mais razoável | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-pt-v1.5 | Inglês | versão 1.5 com distribuição de similaridade mais razoável | Represent this sentence for searching relevant passages: |
| BAAI/bge-grande-zh-v1.5 | chinês | versão 1.5 com distribuição de similaridade mais razoável | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | chinês | versão 1.5 com distribuição de similaridade mais razoável | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | chinês | versão 1.5 com distribuição de similaridade mais razoável | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | Inglês | Incorporação de modelo que mapeia texto em vetor | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | Inglês | um modelo em escala básica, mas com capacidade semelhante ao bge-large-en | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | Inglês | um modelo de pequena escala, mas com desempenho competitivo | Represent this sentence for searching relevant passages: |
| BAAI/bge-grande-zh | chinês | Incorporação de modelo que mapeia texto em vetor | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | chinês | um modelo em escala básica, mas com capacidade semelhante a bge-large-zh | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh | chinês | um modelo de pequena escala, mas com desempenho competitivo | 为这个句子生成表示以用于检索相关文章: |
Agradeça a todos os nossos colaboradores por seus esforços e dê as boas-vindas aos novos membros para participarem!
Se você achar este repositório útil, considere dar uma estrela e uma citação
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding é licenciado sob a licença MIT.


