Sistema de gerenciamento metropolitano
Projetos do curso CS307 - Principles of Database System liderado por Yuxin MA
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
A primeira parte do projeto trata principalmente de projetar um esquema de banco de dados que satisfaça os princípios dos bancos de dados relacionais com base no histórico dos dados fornecidos. Assim que a fase de design for concluída, escrevemos scripts para importar esses grandes conjuntos de dados. Para garantir a precisão dos dados importados, tivemos que realizar algumas consultas e verificar os resultados da consulta no dia da defesa. Além disso, também realizamos alguns experimentos com os dados para obter insights maravilhosos, conforme mostrado mais adiante.
[Leia os requisitos detalhados]
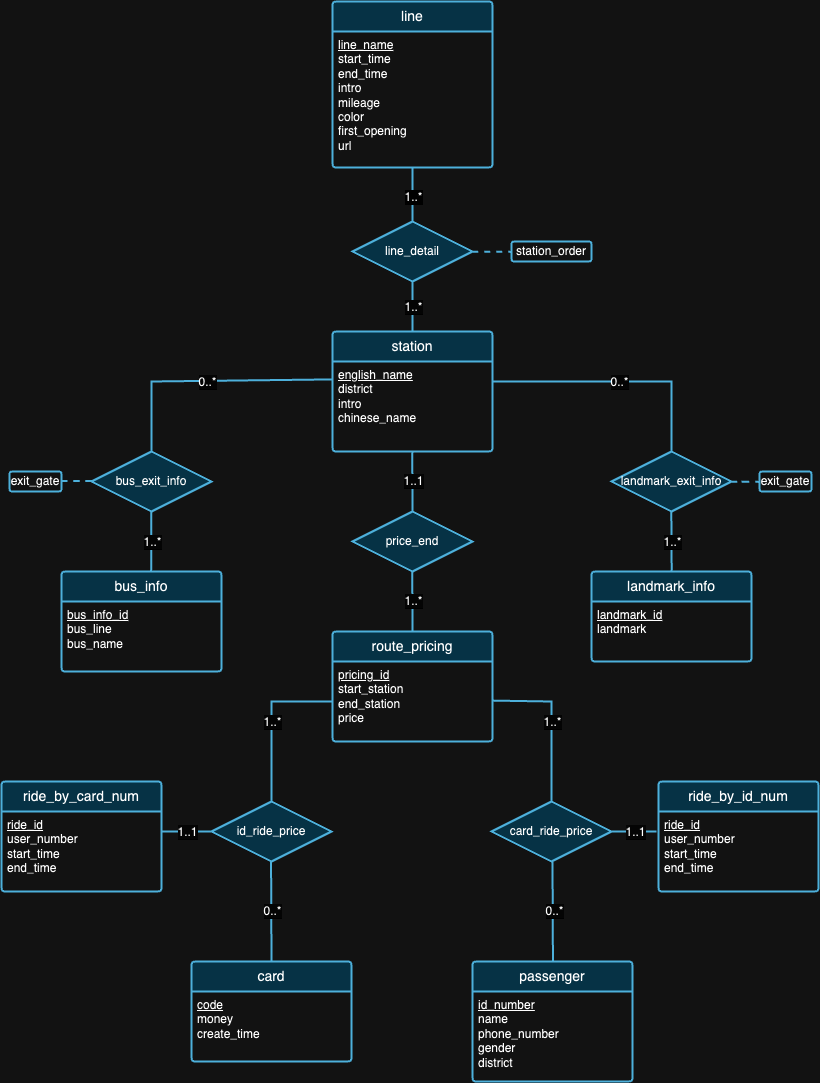
Acreditamos que nenhum design de banco de dados é perfeito. Na verdade, existem falhas no projeto que propomos no diagrama ER acima. Depois de examinar os conjuntos de dados e o histórico de cada conjunto de dados, esperamos que você possa tentar detectar falhas de design por conta própria! :)
Nota : Para interpretação da figura,
| EU IA | SO | Chip | Memória | SSD | Ferramentas |
|---|---|---|---|---|---|
| 1 | MacOS Sonoma 14.4.1 | Apple M3 Pro | 18 GB | 1 TB | IDEA 2024.1 (CE), PyCharm 2023.3.4 (CE), Datagrip 2024.1 |
| 2 | Windows 11 Início 23H2 | Intel(R) Core(TM) i9-12900H de 12ª geração | 32 GB | 1 TB | IDÉIA 2024.1 (CE), Datagrip 2024.1 |
| 3 | Ubuntu 22.04.4 (VM) | Apple M1 Pró | 16 GB | 512 GB | IDÉIA 2024.1 (CE), Datagrip 2024.1 |
Experiment 1: Different Import Methods Método 1 (script original): Este método utiliza a biblioteca java.sql . Primeiramente, estabelecemos uma conexão com nosso servidor PostgreSQL. Em seguida, lemos todos os dados dos arquivos JSON. Em seguida, iteramos cada dado e criamos PreparedStatement para cada instrução de inserção. Por último, chamamos o método executeUpdate() para executar cada instrução individualmente.
Método 2 (script otimizado): Este método também utiliza a biblioteca java.sql e emprega o mesmo algoritmo de leitura de dados do Método 1. A diferença é que agora usamos o método executeBatch() . Portanto, iteramos todos os dados, criamos cada instrução de inserção com PreparedStatement e adicionamos cada PreparedStatement a um lote para execução em lote.
Método 3 (executando um arquivo .sql): Usamos um programa Java para gerar instruções de inserção SQL e as escrevemos em um arquivo .sql empregando o mesmo algoritmo de leitura de dados mencionado acima. Em seguida, executamos o arquivo no DataGrip.
Como estamos usando o mesmo algoritmo de leitura de dados em todos os três métodos, usaremos um tempo de execução médio para nossos testes subsequentes. Inicialmente reunimos três tempos de execução diferentes – 504 ms, 546 ms e 552 ms – e calculamos um tempo de execução médio de 534 ms.
| Ambiente de teste | Método | Tempo médio de leitura (ms) | Tempo de gravação (ms) | Tempo total (ms) | Taxa de transferência (instruções/s) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636,91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632,92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
A Tabela 2 ilustra métricas de desempenho variadas em diferentes métodos, com o Método 2 mostrando o rendimento mais alto e o Método 1 tendo o tempo total mais lento. Isso torna o Método 2 o método de teste padrão nos próximos experimentos.
Experiment 2: Data Import with Different Data VolumesGerenciar e importar dados de volumes variados é um aspecto crucial para garantir o desempenho, a escalabilidade e a confiabilidade de um sistema de banco de dados.
Antes do processo de importação, notamos que os dados de ‘viagem’ eram notavelmente maiores em volume em comparação aos demais. Com base nessa ideia, decidimos testar a importação de dados com volumes diferentes apenas no ride.json . Como o peso dos dados não é consistente, importar menos volume para as demais tabelas pode resultar em um problema sério devido à conectividade entre as tabelas.
Inicialmente, começamos importando os dados completos (100% do volume) para todas as outras tabelas, exceto as tabelas rides_by_id_num e rides_by_card_num para garantir a consistência do nosso design. Para gerenciar isso de forma eficaz, adotamos uma estratégia de importação em fases para os dados ride , começando com um subconjunto de 20% dos dados, o que equivalia a 20.000 registros. Esta fase inicial permitiu avaliar o impacto no desempenho do sistema e fazer os ajustes necessários ao processo de importação sem comprometer a estabilidade da base de dados. Após validação e ajuste de desempenho bem-sucedidos, procedemos à importação de 50% dos dados e, por fim, o restante para concluir a importação de 100% dos dados. Observe que usamos o Método 2 para todas as importações, pois é o mais rápido.
| Ambiente de teste | Método | Volume | Tempo de leitura (ms) | Tempo de gravação (ms) | Tempo total (ms) | Contagem de extratos | Taxa de transferência (instruções/s) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | 1859 | 130849 | 97794,47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263,95 |
Na Tabela 3, à medida que o volume de dados aumenta (de 20% para 50% e para 100%), os tempos de leitura e gravação tendem a aumentar, resultando em tempos totais mais longos para as operações. No entanto, estes números não dão qualquer significado esclarecedor, uma vez que tivemos diferentes volumes de importação. Se observarmos o número de taxas de transferência, a taxa de transferência (instruções/s) diminui gradualmente com o aumento do volume de dados, indicando que o sistema se torna menos eficiente no processamento de instruções à medida que a carga de trabalho aumenta.
Experiment 3: Data Import on Different Operating SystemsAo testar o processo de importação de dados em diferentes SOs, empregamos o método de importação mais rápido, que é o Método 2, com 100% do volume de importação.
Observe que ao executar o script de importação Java no Linux por meio de uma máquina virtual, é essencial considerar a desvantagem injusta no desempenho e na alocação de recursos, pois a virtualização pode introduzir sobrecarga e afetar a eficiência do sistema.
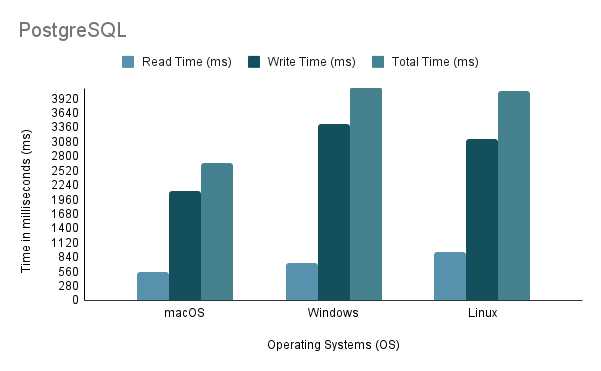
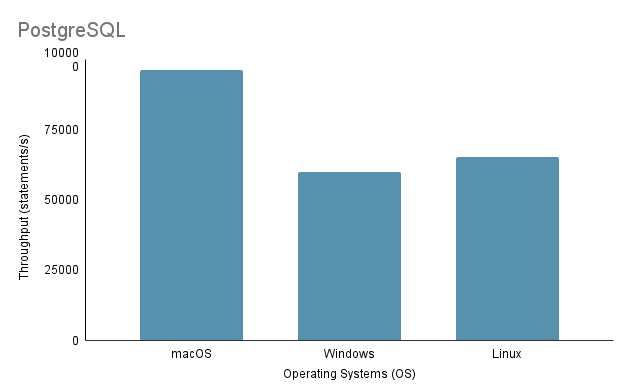
Com base na análise acima, fica claro que o Ambiente 1 (macOS) apresenta o melhor desempenho com o menor tempo total de 2.648 ms e o maior rendimento de 97.632,92 instruções/s. Em contraste, o Ambiente 2 (Windows) é o mais lento, com um tempo total de 4.117 ms e a menor taxa de transferência, 60.669,02 instruções/s. É importante notar que o Linux Ubuntu, embora executado como uma VM, ainda superou o Windows bare-metal.
Experiment 4: Data Import with Various Programming LanguagesNeste experimento, usamos o Método 2 mencionado acima para código Java, pois é o mais rápido. Enquanto isso, para Python, escrevemos um método de importação que utilizava Psycopg2 para se comunicar com o servidor de banco de dados PostgreSQL.
| Ambiente de teste | Linguagem de programação | Tempo de leitura (ms) | Tempo de gravação (ms) | Tempo total (ms) | Taxa de transferência (instruções/s) |
|---|---|---|---|---|---|
| 1 | Java | 534 | 2114 | 2648 | 96263,95 |
| 1 | Pitão | 390 | 7237 | 7627 | 28119.66 |
Os dados da Tabela 4 mostram que o Java superou o Python tanto em velocidade quanto em rendimento, indicando sua eficiência superior para operações de leitura e gravação.
Experiment 5: Data Import on Different DatabasesDesenvolvemos três métodos de importação diferentes para PostgreSQL e MySQL, mas apenas realizamos um experimento no Método 2, pois é a escolha do desenvolvedor para importar dados. Tanto o PostgreSQL quanto o MySQL têm um design de implementação de banco de dados semelhante (DDL) e um design de código de importação semelhante.
| Ambiente de teste | Método | Banco de dados | Tempo de leitura (ms) | Tempo de gravação (ms) | Tempo total (ms) | Taxa de transferência (instruções/s) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263,95 |
| 1 | 2 | MySQL | 534 | 42315 | 42849 | 4809.22 |
Apesar de ambos serem bancos de dados baseados em SQL, o PostgreSQL é aproximadamente 16 vezes mais rápido no que diz respeito ao tempo de gravação. Isso pode ser devido a diferenças na arquitetura do mecanismo de banco de dados e na implementação do driver ( postgresql-42.2.5.jar para PostgreSQL e mysql-connector-j-8.3.0.jar para MySQL).
A Parte 2 do projeto se concentra em fornecer a funcionalidade básica de acesso ao sistema de banco de dados através da construção de uma biblioteca backend que expõe um conjunto de interfaces de programação de aplicativos (APIs). Observe que também há um conjunto de dados adicional que precisa ser importado, portanto, requer uma implementação de banco de dados atualizada (pode ser encontrada em ./Project2/DataImport ).
[Leia os requisitos detalhados]
./Project2/DataImport/src/main/sql/ddl.sql./Project2/DataImport/src/main/java/ImportScript.java./Project2/ShenzhenMetro ) com Maven (IntelliJ IDEA IDE é recomendado)

