chrono_lens
v1.1.1
Este é o repositório público do projeto de análise de câmeras de trânsito, conforme publicado no Office for National Statistics Data Science Campus Blog como parte dos Indicadores mais rápidos de coronavírus do ONS (por exemplo - Atividade de câmeras de trânsito - 10 de setembro de 2020) e a metodologia subjacente. O projeto utilizou o Google Compute Platform (GCP) para permitir uma solução escalonável, mas a metodologia subjacente é independente de plataforma; este repositório contém nossa implementação orientada ao GCP.
Um exemplo de resultado produzido para o Indicador Coronavírus Mais Rápido é apresentado abaixo.
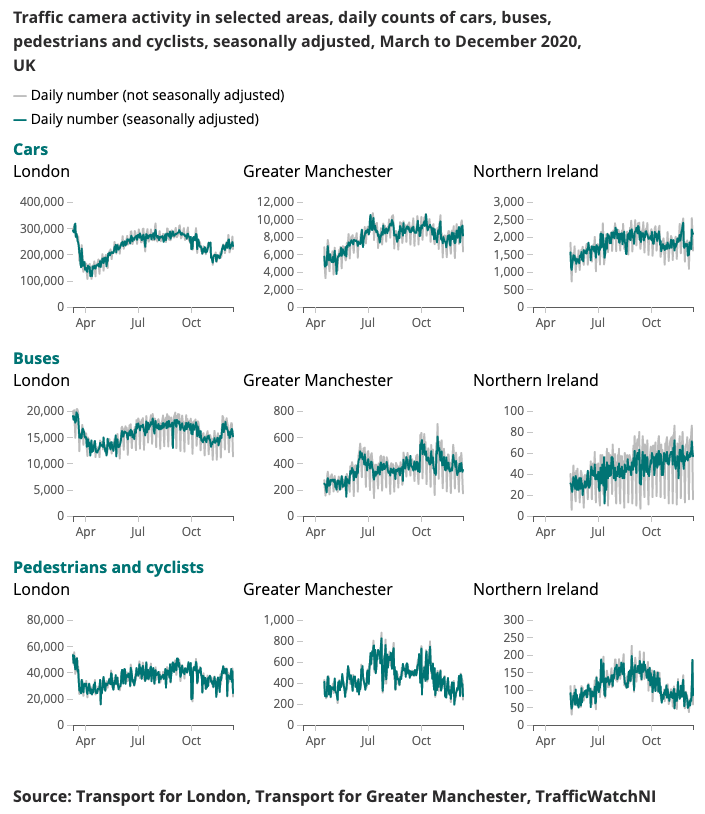
Compreender os padrões de mudança na mobilidade e no comportamento em tempo real tem sido um foco importante da resposta do governo ao coronavírus (COVID-19). O Data Science Campus tem explorado fontes de dados alternativas que possam fornecer informações sobre como estimar os níveis de distanciamento social e acompanhar a recuperação da sociedade e da economia à medida que as condições de confinamento são relaxadas.
As câmaras de trânsito são uma fonte de dados amplamente disponível ao público que permite aos profissionais dos transportes e ao público avaliar o fluxo de tráfego em diferentes partes do país através da Internet. As imagens produzidas pelas câmeras de trânsito são de domínio público, de baixa resolução e não permitem a identificação individual de pessoas ou veículos. Eles diferem do CCTV usado para segurança pública e aplicação da lei para reconhecimento automático de matrículas (ANPR) ou para monitorar a velocidade do tráfego.
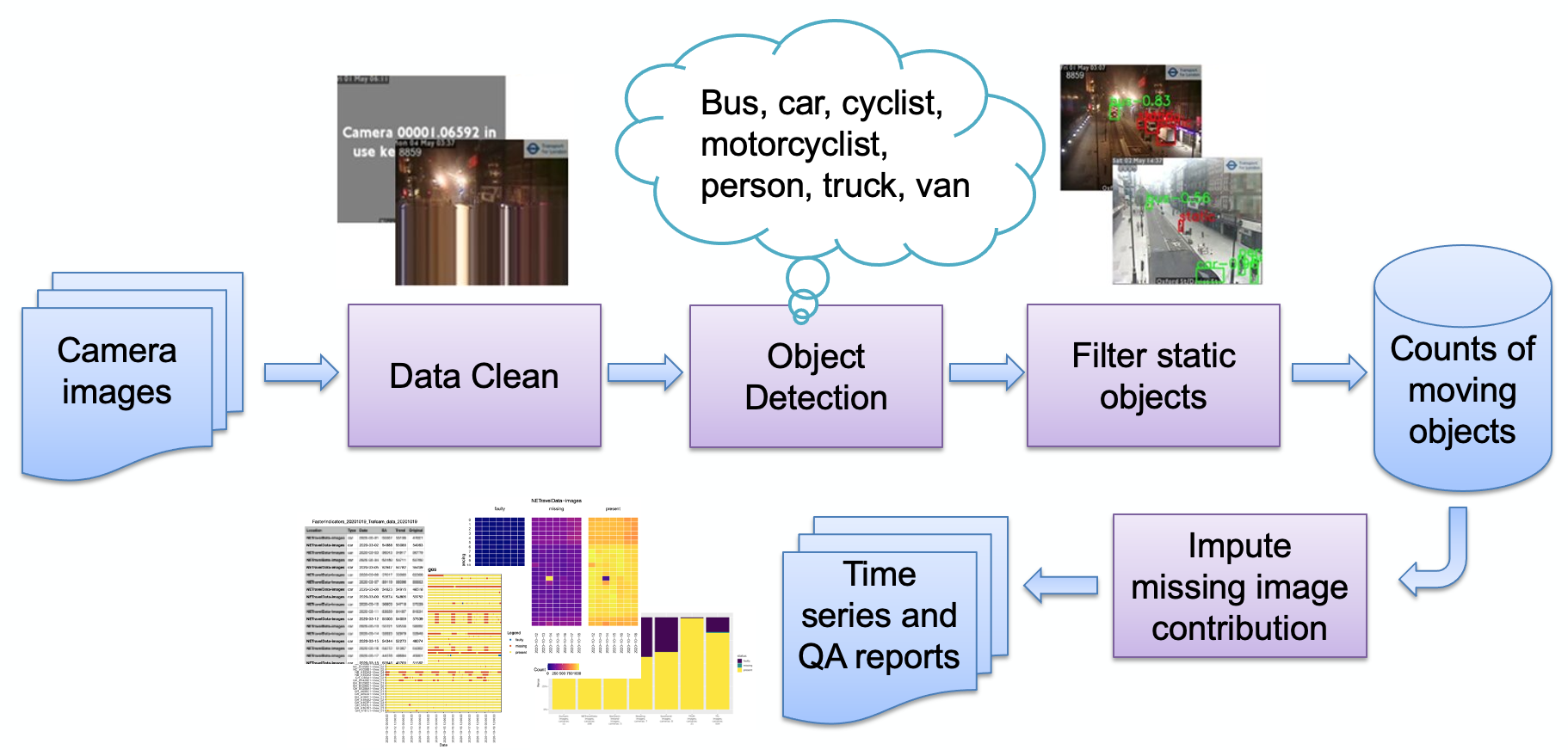
As principais etapas do pipeline, conforme descrito na imagem, são:
Ingestão de imagens
Detecção de imagem defeituosa
Detecção de objetos
Detecção de objetos estáticos
Armazenamento de contagens resultantes
As contagens podem então ser processadas posteriormente (ajuste sazonal, imputação de valores em falta) e transformadas em relatórios conforme necessário. Analisaremos brevemente as principais etapas do pipeline.
Um conjunto de fontes de câmera (imagens JPEG hospedadas na web) é selecionado pelo usuário e fornecido como uma lista de URLs ao usuário. Um código de exemplo é fornecido para obter imagens públicas do Transport for London e um código especializado para extrair dados de tráfego NE diretamente do Observatório Urbano da Universidade de Newcastle.
As câmeras podem estar indisponíveis por vários motivos (falha do sistema, alimentação desabilitada pelo operador local, etc.) e isso pode fazer com que o modelo gere contagens de objetos falsas (por exemplo, uma pequena bolha pode parecer um barramento distante). Um exemplo de tal imagem é: 
Até agora, todas essas imagens seguiram um padrão de imagem muito sintética, consistindo em uma cor de fundo plana e texto sobreposto (em comparação com uma imagem de uma cena natural). Atualmente, essas imagens são detectadas reduzindo a profundidade da cor (juntando cores semelhantes) e, em seguida, observando a fração mais alta da imagem ocupada por uma única cor. Quando isso ultrapassar um limite, determinamos que a imagem é sintética e a marcamos como defeituosa. Outras falhas podem ocorrer devido à codificação, como: 
Aqui, o feed da camrera parou e a última linha “ao vivo” foi repetida; detectamos isso verificando se a linha inferior da imagem corresponde à linha acima (dentro do limite). Nesse caso, a próxima linha acima será verificada em busca de correspondência e assim por diante até que as linhas não correspondam mais ou fiquemos sem linhas. Se o número de linhas correspondentes estiver acima de um limite, é improvável que a imagem gere dados úteis e, portanto, seja sinalizada como defeituosa.
Observe que diferentes provedores de imagens usam maneiras diferentes de mostrar que uma câmera não está disponível; nossa técnica de detecção depende do uso de poucas cores - ou seja, uma imagem puramente sintética. Se for utilizada uma imagem mais natural, nossa técnica pode não funcionar. Uma alternativa é manter uma “biblioteca” de imagens com falhas e buscar semelhanças, o que pode funcionar melhor com imagens mais naturais.
O processo de detecção de objetos identifica objetos estáticos e em movimento, usando um Faster-RCNN pré-treinado fornecido pelo Observatório Urbano da Universidade de Newcastle. O modelo foi treinado em 10.000 imagens de câmeras de trânsito do Nordeste da Inglaterra e posteriormente validado pelo ONS Data Science Campus para confirmar que o modelo era utilizável com imagens de câmeras de outras áreas do Reino Unido. Ele detecta os seguintes tipos de objetos: carro, van, caminhão, ônibus, pedestre, ciclista, motociclista.
Como pretendemos detectar atividade, é importante filtrar objetos estáticos usando informações temporais. As imagens são amostradas em intervalos de 10 minutos, portanto os métodos tradicionais para detecção de fundo em vídeo, como mistura de gaussianas, não são adequados.
Quaisquer pedestres e veículos classificados durante a detecção de objetos serão definidos como estáticos e removidos da contagem final se também aparecerem em segundo plano. A imagem abaixo mostra exemplos de resultados da máscara estática, onde os carros estacionados na imagem (a) são identificados como estáticos e removidos. Um benefício extra é que a máscara estática pode ajudar a remover alarmes falsos. Por exemplo, na imagem (b), a lixeira é identificada erroneamente como um pedestre na detecção de objetos, mas filtrada como fundo estático.

Os resultados são simplesmente armazenados como uma tabela, o esquema registrando a identificação da câmera, data, hora, contagens relacionadas por tipo de objeto (carro, van, pedestre, etc.), se uma imagem estiver com defeito ou se uma imagem estiver faltando.
Inicialmente, o sistema foi projetado para ser nativo da nuvem, para permitir escalabilidade; no entanto, isso introduz uma barreira de entrada - você precisa ter uma conta em um provedor de nuvem, saber como proteger a infraestrutura, etc. Com isso em mente, também transferimos o código para funcionar em uma máquina autônoma (ou "host local") para permitir que um usuário interessado simplesmente execute o sistema em seu próprio laptop. Ambas as implementações são agora descritas abaixo.
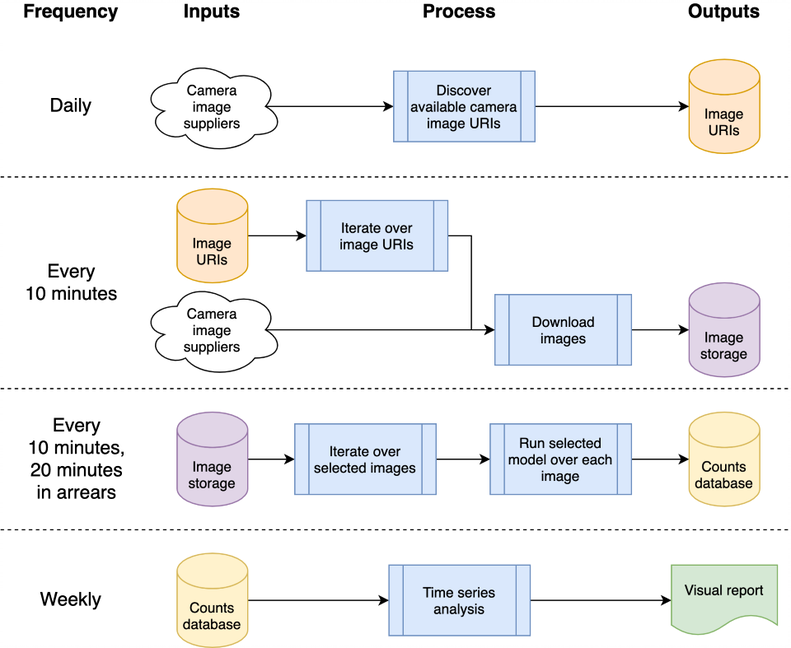
Essa arquitetura pode ser mapeada para uma única máquina ou sistema em nuvem; optamos por usar o Google Compute Platform (GCP), mas outras plataformas, como Amazon Web Services (AWS) ou Microsoft Azure, forneceriam serviços relativamente equivalentes.
O sistema é hospedado como “funções de nuvem”, que são códigos independentes e sem estado que podem ser chamados repetidamente sem causar corrupção – uma consideração importante para aumentar a robustez das funções. As intermitências de processamento diárias e “a cada 10 minutos” são orquestradas usando o Agendador do GCP para acionar um tópico Pub/Sub do GCP de acordo com a programação desejada. As funções de nuvem do GCP são registradas no tópico e iniciadas sempre que o tópico é acionado.
O processamento das imagens para detectar veículos e pedestres resulta na gravação de contagens de objetos em um banco de dados para análise posterior como uma série temporal. O banco de dados é usado para compartilhar dados entre a coleta de dados e a análise de séries temporais, reduzindo o acoplamento. Usamos o BigQuery no GCP como nosso banco de dados devido ao amplo suporte em outros produtos do GCP, como o Data Studio para visualização de dados; a implementação do host local armazena CSVs diários por comparação, para remover qualquer dependência de um banco de dados específico ou de outra infraestrutura.
O código-fonte relacionado ao GCP é armazenado na pasta cloud ; isso baixa as imagens, processa-as para contar objetos, armazena as contagens em um banco de dados e (semanalmente) produz análises de séries temporais. Toda a documentação e código-fonte são armazenados na pasta cloud ; consulte Cloud README.md para obter uma visão geral da arquitetura e como instalar sua própria instância usando nossos scripts em seu espaço de projeto do GCP. O projeto pode ser integrado ao GitHub, permitindo a implantação automática e a execução de testes automaticamente a partir de commits para um projeto local do GitHub; isso também está documentado no Cloud README.md. O código de suporte da nuvem também é armazenado no módulo chrono_lens.gcloud , permitindo que scripts de linha de comando ofereçam suporte ao GCP, junto com o código da função da nuvem na pasta cloud .
O código independente de máquina única ("localhost") está contido no módulo chrono_lens.localhost . O processo segue o mesmo fluxo da variante GCP, embora use uma única máquina e cada arquivo python em chrono_lens.localhost mapeia para o Cloud Functions do GCP. Consulte README-localhost.md para obter mais detalhes.
Descrevemos agora as várias etapas e pré-requisitos para instalar o sistema, visto que as implementações do GCP e do hos local exigem pelo menos alguma instalação local.
A criação de um ambiente virtual é fortemente aconselhada permitindo um ambiente de trabalho isolado. Exemplos de bons ambientes de trabalho incluem conda, pyenv e poerty.
Observe que as dependências já estão contidas em requirements.txt , então instale-o via pip:
pip install -r requirements.txt
Para evitar a confirmação acidental de senhas, são recomendados ganchos de pré-confirmação que evitam que os commits do git sejam processados antes que informações confidenciais cheguem ao repositório. Usamos os ganchos de pré-confirmação de https://github.com/ukgovdatascience/govcookiecutter
A instalação de require.txt instalará a ferramenta de pré-commit, que agora precisa ser conectada ao git:
pre-commit install
... que extrairá a configuração de .pre-commit-config.yaml .
NOTA: o teste de pré-commit check-added-large-files tem seu tamanho máximo de kB em .pre-commit-config.yaml é temporariamente aumentado para 60Mb ao adicionar o arquivo de modelo RCNN /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb . O limite é então revertido para 5 Mb como um limite superior "normal" sensato.
É recomendado executar uma varredura em todos os arquivos antes de continuar, apenas para garantir que nada esteja presente por engano:
pre-commit run --all-files
Isso reportará quaisquer problemas existentes - útil porque o gancho só é executado em arquivos editados.
O projeto foi projetado para ser usado principalmente por meio de infraestrutura em nuvem, mas existem scripts utilitários para acesso local e atualizações de séries temporais na nuvem. Esses scripts estão localizados na pasta scripts/gcloud , com cada script agora descrito em seções separadas a seguir. Mais informações podem ser encontradas em scripts/gcloud/README.md , e seu uso por uma máquina virtual opcional é descrito em cloud/README.md .
O uso fora da nuvem é suportado pelos scripts na pasta scripts/localhost , e detalhes de como usar o sistema chrono_lens em uma máquina autônoma são descritos em README-localhost.md . Mais informações sobre o uso dos scripts podem ser encontradas em scripts/localhost/README.md .
Observe que os scripts usam código na pasta chrono_lens .
| Versão | Data | Notas |
|---|---|---|
| 1.0.0 | 08/06/2021 | Primeira versão do repositório público |
| 1.0.1 | 2021-09-21 | Correção de bug para imagens isoladas, aumento da versão do tensorflow |
| 1.1.0 | ? | Adicionado suporte limitado para máquina única autônoma |
Áreas de potencial trabalho futuro são apresentadas aqui; essas mudanças podem não ser investigadas, mas estão aqui para conscientizar as pessoas sobre possíveis melhorias que consideramos.
Atualmente, os scripts bash shell são usados para criar a infraestrutura do GCP; uma melhoria seria usar IaC, como o Terraform. Isso simplifica a alteração (por exemplo) das configurações do Cloud Function sem a necessidade de remover manualmente o Cloud Build Trigger e recriá-lo quando o ambiente de tempo de execução ou os limites de memória forem alterados.
O design atual decorre de seu caso de uso inicial de aquisição de imagens antes da finalização dos modelos, portanto, todas as imagens disponíveis são baixadas e não apenas aquelas que são analisadas. Para economizar custos de ingestão, o código de ingestão deve fazer uma verificação cruzada com os arquivos JSON de análise e fazer download apenas desses arquivos; um alerta deve ser emitido quando alguma dessas fontes não estiver mais disponível ou se novas fontes estiverem disponíveis.
O preenchimento noturno de imagens para NETravelData parece atualizar cerca de 40% das imagens NETravelData; a vantagem de uma atualização regular é diminuída se os números forem necessários apenas diariamente e, portanto, a Cloud Function distribute_ne_travel_data pode ser removida.
http async para o PubSub O design inicial usa scripts operados manualmente ao testar novos modelos – ou seja, batch_process_images.py . Informa o sucesso (ou não) e o número de imagens processadas. Para fazer isso, uma Cloud Function funciona bem, pois retorna um resultado. No entanto, uma arquitetura mais eficiente seria usar uma fila PubSub internamente com as funções distribute_json_sources e processed_scheduled adicionando trabalho às filas PubSub que são consumidas por uma única função de trabalho, em vez da hierarquia atual de chamadas assíncronas (usando duas funções extras para escalar horizontalmente ).
O Observatório Urbano da Universidade de Newcastle forneceu o Faster-RCNNN pré-treinado que usamos (uma cópia local é armazenada em /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb ).
Os dados são fornecidos pelo Serviço de Dados Abertos de Gerenciamento e Controle de Tráfego Urbano do Nordeste, licenciado sob a Licença Governamental Aberta 3.0. As imagens são atribuídas a Tyne and Wear Urban Traffic Management and Control.
Os dados do Nordeste são posteriormente processados e hospedados pelo Observatório Urbano da Universidade de Newcastle, cujo apoio e aconselhamento agradecemos.
Os dados são fornecidos pela TfL e alimentados pela TfL Open Data. Os dados são licenciados sob a versão 2.0 da Open Government License. Os dados TfL contêm dados do sistema operacional © Crown copyright e direitos de banco de dados 2016 e Geomni UK Map data © e direitos de banco de dados (2019).
Várias bibliotecas de terceiros são usadas neste projeto; estes estão listados na página de dependências, cujas contribuições agradecemos.


