shap
v0.46.0
SHAP (SHapley Additive exPlanations) é uma abordagem teórica de jogos para explicar a saída de qualquer modelo de aprendizado de máquina. Ele conecta a alocação ideal de crédito com explicações locais usando os valores clássicos de Shapley da teoria dos jogos e suas extensões relacionadas (ver artigos para detalhes e citações).
O SHAP pode ser instalado a partir do PyPI ou do conda-forge:
pip instalar forma ou conda install -c conda-forge forma
Embora o SHAP possa explicar a saída de qualquer modelo de aprendizado de máquina, desenvolvemos um algoritmo exato de alta velocidade para métodos de conjunto de árvores (veja nosso artigo Nature MI). Implementações rápidas de C++ são suportadas para modelos de árvore XGBoost , LightGBM , CatBoost , scikit-learn e pyspark :
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])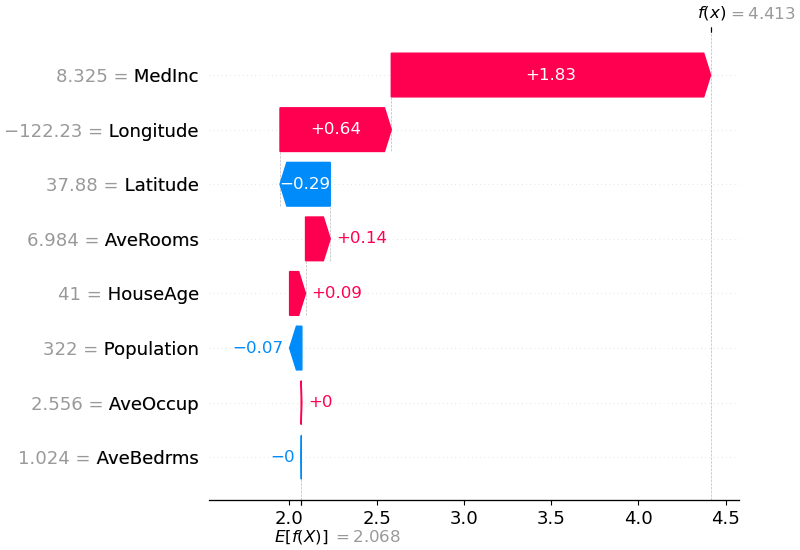
A explicação acima mostra recursos que contribuem para empurrar a saída do modelo do valor base (a saída média do modelo sobre o conjunto de dados de treinamento que passamos) para a saída do modelo. Os recursos que aumentam a previsão são mostrados em vermelho, aqueles que aumentam a previsão são mostrados em azul. Outra maneira de visualizar a mesma explicação é usar um gráfico de força (estes são apresentados em nosso artigo da Nature BME):
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
Se pegarmos muitas explicações do gráfico de força, como a mostrada acima, girá-las 90 graus e, em seguida, empilhá-las horizontalmente, poderemos ver explicações para um conjunto de dados inteiro (no caderno, esse gráfico é interativo):
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])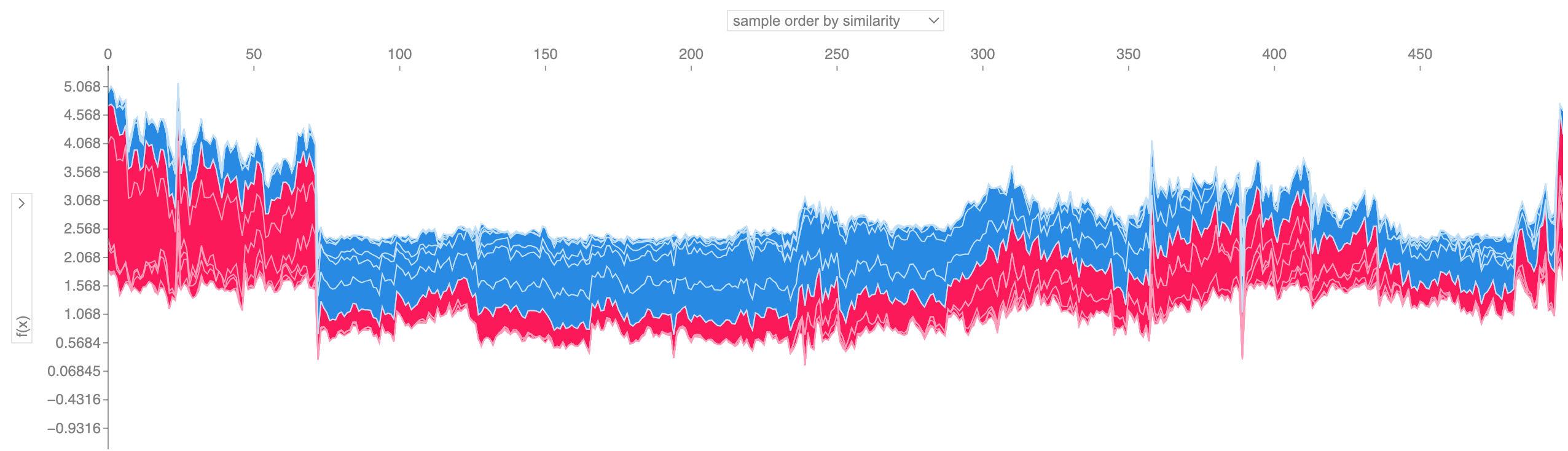
Para entender como um único recurso afeta a saída do modelo, podemos representar graficamente o valor SHAP desse recurso versus o valor do recurso para todos os exemplos em um conjunto de dados. Como os valores SHAP representam a responsabilidade de um recurso por uma mudança na saída do modelo, o gráfico abaixo representa a mudança no preço previsto da casa conforme a latitude muda. A dispersão vertical em um único valor de latitude representa efeitos de interação com outras características. Para ajudar a revelar essas interações, podemos colorir por outro recurso. Se passarmos todo o tensor de explicação para o argumento color , o gráfico de dispersão escolherá o melhor recurso para colorir. Neste caso, ele escolhe a longitude.
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )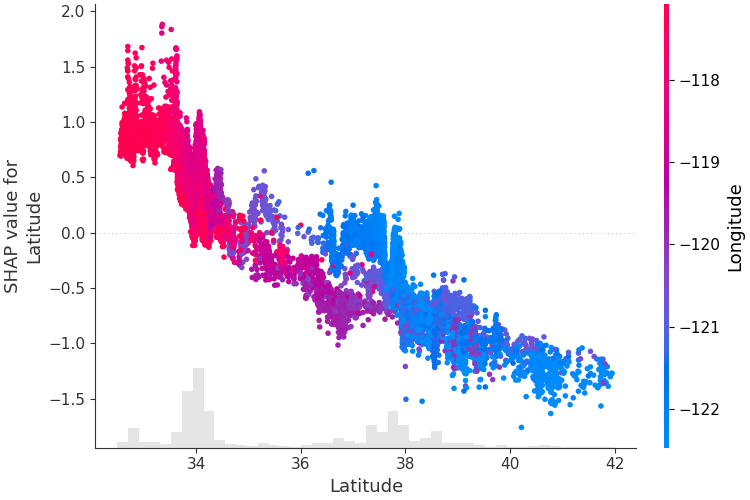
Para obter uma visão geral de quais recursos são mais importantes para um modelo, podemos traçar os valores SHAP de cada recurso para cada amostra. O gráfico abaixo classifica os recursos pela soma das magnitudes dos valores SHAP em todas as amostras e usa valores SHAP para mostrar a distribuição dos impactos que cada recurso tem na saída do modelo. A cor representa o valor do recurso (vermelho alto, azul baixo). Isto revela, por exemplo, que rendimentos medianos mais elevados melhoram o preço previsto da habitação.
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )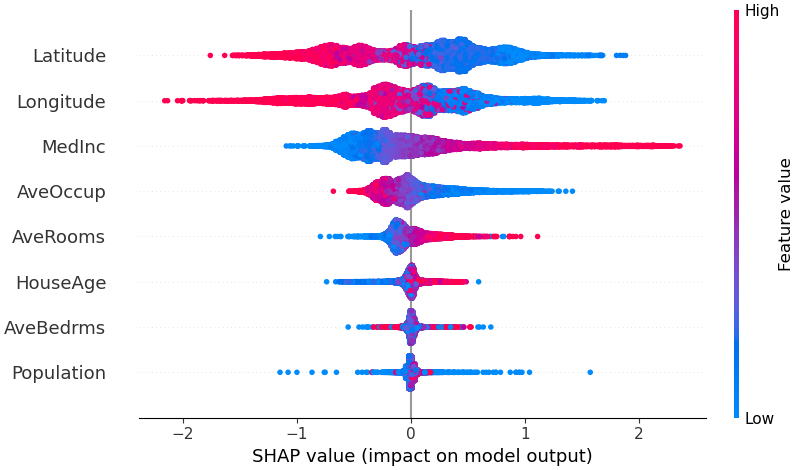
Também podemos apenas pegar o valor absoluto médio dos valores SHAP para cada recurso para obter um gráfico de barras padrão (produz barras empilhadas para saídas multiclasse):
shap . plots . bar ( shap_values )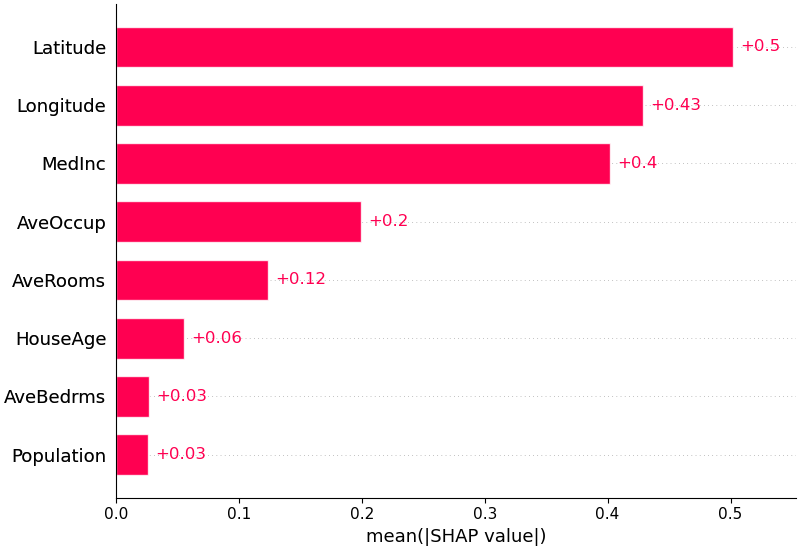
SHAP tem suporte específico para modelos de linguagem natural como os da biblioteca de transformadores Hugging Face. Ao adicionar regras de coalizão aos valores Shapley tradicionais, podemos formar jogos que explicam o grande modelo moderno de PNL usando muito poucas avaliações de funções. Usar essa funcionalidade é tão simples quanto passar um pipeline de transformadores suportado para o SHAP:
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP é um algoritmo de aproximação de alta velocidade para valores SHAP em modelos de aprendizado profundo que se baseia em uma conexão com DeepLIFT descrito no artigo SHAP NIPS. A implementação aqui difere do DeepLIFT original por usar uma distribuição de amostras de fundo em vez de um único valor de referência e usar equações de Shapley para linearizar componentes como max, softmax, produtos, divisões, etc. desde integrado ao DeepLIFT. Modelos TensorFlow e modelos Keras que usam o backend TensorFlow são suportados (também há suporte preliminar para PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])O gráfico acima explica dez saídas (dígitos 0 a 9) para quatro imagens diferentes. Os pixels vermelhos aumentam a saída do modelo, enquanto os pixels azuis diminuem a saída. As imagens de entrada são mostradas à esquerda e em tons de cinza quase transparentes atrás de cada uma das explicações. A soma dos valores SHAP é igual à diferença entre o resultado esperado do modelo (média do conjunto de dados de segundo plano) e o resultado do modelo atual. Observe que para a imagem 'zero' o meio em branco é importante, enquanto para a imagem 'quatro' a falta de conexão no topo faz com que seja um quatro em vez de um nove.
Gradientes esperados combinam ideias de Gradientes Integrados, SHAP e SmoothGrad em uma única equação de valor esperado. Isso permite que um conjunto de dados inteiro seja usado como distribuição de fundo (em oposição a um único valor de referência) e permite suavização local. Se aproximarmos o modelo com uma função linear entre cada amostra de dados de fundo e a entrada atual a ser explicada, e assumirmos que os recursos de entrada são independentes, os gradientes esperados calcularão valores SHAP aproximados. No exemplo abaixo explicamos como a 7ª camada intermediária do modelo VGG16 ImageNet impacta as probabilidades de saída.
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) As previsões para duas imagens de entrada são explicadas no gráfico acima. Pixels vermelhos representam valores SHAP positivos que aumentam a probabilidade da classe, enquanto pixels azuis representam valores SHAP negativos que reduzem a probabilidade da classe. Ao usar ranked_outputs=2 explicamos apenas as duas classes mais prováveis para cada entrada (isso nos poupa de explicar todas as 1.000 classes).
Kernel SHAP usa uma regressão linear local especialmente ponderada para estimar valores SHAP para qualquer modelo. Abaixo está um exemplo simples para explicar um SVM multiclasse no conjunto de dados clássico da íris.
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )A explicação acima mostra quatro recursos, cada um contribuindo para empurrar a saída do modelo do valor base (a saída média do modelo sobre o conjunto de dados de treinamento que passamos) para zero. Se houvesse algum recurso elevando o rótulo da classe, ele seria mostrado em vermelho.
Se pegarmos muitas explicações como a mostrada acima, girá-las 90 graus e empilhá-las horizontalmente, poderemos ver explicações para um conjunto de dados inteiro. Isso é exatamente o que fazemos abaixo para todos os exemplos do conjunto de testes de íris:
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" ) Os valores de interação SHAP são uma generalização dos valores SHAP para interações de ordem superior. O cálculo rápido e exato de interações entre pares é implementado para modelos de árvore com shap.TreeExplainer(model).shap_interaction_values(X) . Isso retorna uma matriz para cada previsão, onde os efeitos principais estão na diagonal e os efeitos de interação estão fora da diagonal. Estes valores muitas vezes revelam relações ocultas interessantes, tais como a forma como o risco aumentado de morte atinge o pico para os homens aos 60 anos (ver o caderno NHANES para mais detalhes):
Os notebooks abaixo demonstram diferentes casos de uso do SHAP. Procure dentro do diretório de notebooks do repositório se quiser tentar brincar com os notebooks originais.
Uma implementação do Tree SHAP, um algoritmo rápido e exato para calcular valores SHAP para árvores e conjuntos de árvores.
Modelo de sobrevivência NHANES com valores de interação XGBoost e SHAP - Usando dados de mortalidade de 20 anos de acompanhamento, este caderno demonstra como usar XGBoost e shap para descobrir relações complexas de fatores de risco.
Classificação de renda do censo com LightGBM - Usando o conjunto de dados padrão de renda do censo de adultos, este notebook treina um modelo de árvore de aumento de gradiente com LightGBM e, em seguida, explica as previsões usando shap .
Previsão de vitória de League of Legends com XGBoost - Usando um conjunto de dados Kaggle de 180.000 partidas classificadas de League of Legends, treinamos e explicamos um modelo de árvore de aumento de gradiente com XGBoost para prever se um jogador vencerá sua partida.
Uma implementação do Deep SHAP, um algoritmo mais rápido (mas apenas aproximado) para calcular valores SHAP para modelos de aprendizado profundo baseado em conexões entre o SHAP e o algoritmo DeepLIFT.
Classificação de dígitos MNIST com Keras - Usando o conjunto de dados de reconhecimento de escrita manual MNIST, este notebook treina uma rede neural com Keras e, em seguida, explica as previsões usando shap .
Keras LSTM para classificação de sentimento do IMDB - Este notebook treina um LSTM com Keras no conjunto de dados de análise de sentimento de texto do IMDB e, em seguida, explica as previsões usando shap .
Uma implementação de gradientes esperados para aproximar valores SHAP para modelos de aprendizagem profunda. É baseado em conexões entre SHAP e o algoritmo Integrated Gradients. GradientExplainer é mais lento que DeepExplainer e faz diferentes suposições de aproximação.
Para um modelo linear com características independentes, podemos calcular analiticamente os valores SHAP exatos. Também podemos levar em conta a correlação de recursos se estivermos dispostos a estimar a matriz de covariância de recursos. LinearExplainer oferece suporte a ambas as opções.
Uma implementação do Kernel SHAP, um método independente de modelo para estimar valores SHAP para qualquer modelo. Como não faz suposições sobre o tipo de modelo, KernelExplainer é mais lento que outros algoritmos específicos de tipo de modelo.
Classificação de renda do censo com scikit-learn - Usando o conjunto de dados padrão de renda do censo de adultos, este notebook treina um classificador de k-vizinhos mais próximos usando scikit-learn e, em seguida, explica as previsões usando shap .
Modelo ImageNet VGG16 com Keras - Explique as previsões da rede neural convolucional clássica VGG16 para uma imagem. Isso funciona aplicando o método Kernel SHAP independente de modelo a uma imagem segmentada de super pixel.
Classificação da íris – Uma demonstração básica usando o popular conjunto de dados de espécies de íris. Ele explica as previsões de seis modelos diferentes no scikit-learn usando shap .
Esses notebooks demonstram de forma abrangente como usar funções e objetos específicos.
shap.decision_plot e shap.multioutput_decision_plot
shap.dependence_plot
LIMA: Ribeiro, Marco Tulio, Sameer Singh e Carlos Guestrin. "Por que eu deveria confiar em você?: Explicando as previsões de qualquer classificador." Anais da 22ª Conferência Internacional ACM SIGKDD sobre Descoberta de Conhecimento e Mineração de Dados. ACM, 2016.
Valores de amostragem de Shapley: Strumbelj, Erik e Igor Kononenko. "Explicando modelos de previsão e previsões individuais com contribuições de recursos." Sistemas de conhecimento e informação 41.3 (2014): 647-665.
DeepLIFT: Shrikumar, Avanti, Peyton Greenside e Anshul Kundaje. "Aprendendo recursos importantes através da propagação de diferenças de ativação." Pré-impressão do arXiv arXiv:1704.02685 (2017).
QII: Datta, Anupam, Shayak Sen e Yair Zick. "Transparência algorítmica via influência quantitativa de insumos: Teoria e experimentos com sistemas de aprendizagem." Segurança e Privacidade (SP), Simpósio IEEE 2016 em. IEEE, 2016.
Propagação de relevância por camada: Bach, Sebastian, et al. "Sobre explicações em pixels para decisões de classificadores não lineares por propagação de relevância em camadas." PloS um 10.7 (2015): e0130140.
Valores de regressão Shapley: Lipovetsky, Stan e Michael Conklin. "Análise de regressão na abordagem da teoria dos jogos." Modelos Estocásticos Aplicados em Negócios e Indústria 17.4 (2001): 319-330.
Intérprete de árvores: Saabas, Ando. Interpretando florestas aleatórias. http://blog.datadive.net/interpreting-random-forests/
Os algoritmos e visualizações usados neste pacote vieram principalmente de pesquisas no laboratório de Su-In Lee na Universidade de Washington e na Microsoft Research. Se você usar o SHAP em sua pesquisa, agradeceríamos uma citação do(s) artigo(s) apropriado(s):
force_plot e aplicações médicas você pode ler/citar nosso artigo Nature Biomedical Engineering (bibtex; acesso gratuito).

