whisperX
3.1.1
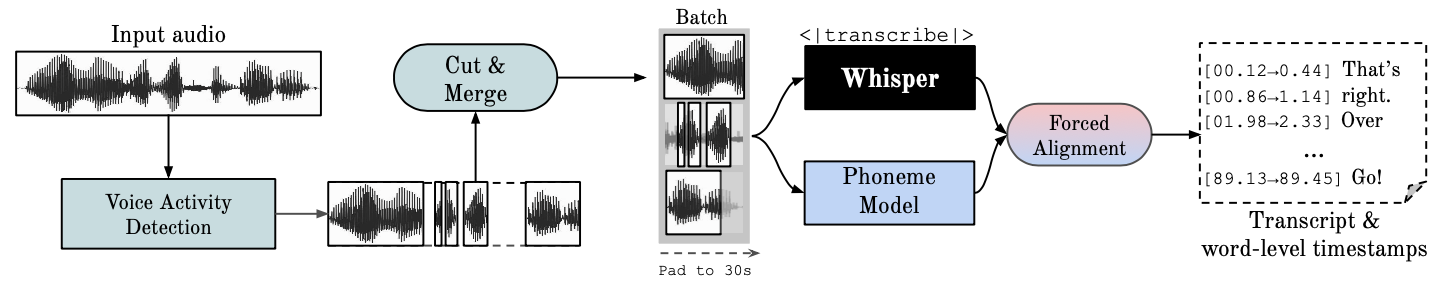
Este repositório fornece reconhecimento de fala automático rápido (70x em tempo real com v2 grande) com carimbos de data e hora em nível de palavra e diarização de alto-falante.
Whisper é um modelo ASR desenvolvido pela OpenAI, treinado em um grande conjunto de dados de áudio diversificado. Embora produza transcrições altamente precisas, os carimbos de data/hora correspondentes estão no nível da expressão, não por palavra, e podem ser imprecisos por vários segundos. O sussurro do OpenAI não oferece suporte nativo ao processamento em lote.
ASR Baseado em Fonemas Um conjunto de modelos ajustados para reconhecer a menor unidade de fala que distingue uma palavra de outra, por exemplo, o elemento p em "tap". Um modelo de exemplo popular é wav2vec2.0.
Alinhamento forçado refere-se ao processo pelo qual as transcrições ortográficas são alinhadas às gravações de áudio para gerar automaticamente a segmentação no nível do telefone.
A Detecção de Atividade de Voz (VAD) é a detecção da presença ou ausência de fala humana.
Diarização de alto-falante é o processo de particionar um fluxo de áudio contendo fala humana em segmentos homogêneos de acordo com a identidade de cada locutor.
A execução da GPU requer que as bibliotecas NVIDIA cuBLAS 11.x e cuDNN 8.x sejam instaladas no sistema. Consulte a documentação do CTranslate2.
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
Veja outros métodos aqui.
pip install git+https://github.com/m-bain/whisperx.git
Se já estiver instalado, atualize o pacote para o commit mais recente
pip install git+https://github.com/m-bain/whisperx.git --upgrade
Se desejar modificar este pacote, clone e instale em modo editável:
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
Você também pode precisar instalar ffmpeg, ferrugem etc. Siga as instruções do openAI aqui https://github.com/openai/whisper#setup.
Para habilitar Speaker Diarization , inclua seu token de acesso Hugging Face (leitura) que você pode gerar aqui após o argumento --hf_token e aceite o contrato do usuário para os seguintes modelos: Segmentation e Speaker-Diarization-3.1 (se você optar por usar Speaker -Diarização 2.x, siga os requisitos aqui.)
Observação
Em 11 de outubro de 2023, há um problema conhecido relacionado ao desempenho lento com pyannote/Speaker-Diarization-3.0 no WhisperX. É devido a conflitos de dependência entre o sussurro mais rápido e o pyannote-audio 3.0.0. Consulte este problema para obter mais detalhes e possíveis soluções alternativas.
Execute sussurro no segmento de exemplo (usando parâmetros padrão, sussurro pequeno) adicione --highlight_words True para visualizar os tempos das palavras no arquivo .srt.
whisperx examples/sample01.wav
Resultado usando WhisperX com alinhamento forçado para wav2vec2.0 grande:
Compare isso com o sussurro original, onde muitas transcrições estão fora de sincronia:
Para aumentar a precisão do carimbo de data e hora, ao custo de maior memória de GPU, use modelos maiores (o modelo de alinhamento maior não é tão útil, consulte o artigo), por exemplo
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
Para rotular a transcrição com IDs de locutor (defina o número de locutores, se conhecido, por exemplo, --min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
Para rodar na CPU em vez da GPU (e para rodar no Mac OS X):
whisperx examples/sample01.wav --compute_type int8
O modelo de alinhamento ASR do fonema é específico do idioma ; para idiomas testados, esses modelos são automaticamente escolhidos em pipelines torchaudio ou huggingface. Basta passar o código --language e usar o Whisper --model large .
Atualmente, os modelos padrão são fornecidos para {en, fr, de, es, it, ja, zh, nl, uk, pt} . Se o idioma detectado não estiver nesta lista, você precisará encontrar um modelo ASR baseado em fonema no hub do modelo huggingface e testá-lo em seus dados.
whisperx --model large-v2 --language de examples/sample_de_01.wav
Veja mais exemplos em outros idiomas aqui.
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs Se você não tiver acesso às suas próprias GPUs, use os links acima para experimentar o WhisperX.
Para detalhes específicos sobre lote e alinhamento, o efeito do VAD, bem como o modelo de alinhamento escolhido, consulte o artigo pré-impresso.
Para reduzir os requisitos de memória da GPU, tente qualquer um dos seguintes (2. e 3. podem afetar a qualidade):
--batch_size 4--model base--compute_type int8Diferenças de transcrição do sussurro de openai:
--without_timestamps True , o que garante 1 passagem direta por amostra no lote. No entanto, isso pode causar discrepâncias na saída de sussurro padrão.--condition_on_prev_text é definido como False por padrão (reduz a alucinação) Se você é multilíngue, uma forma importante de contribuir com este projeto é encontrar modelos de fonemas no huggingface (ou treinar o seu próprio) e testá-los na fala do idioma alvo. Se os resultados parecerem bons, envie uma solicitação pull e alguns exemplos mostrando seu sucesso.
A localização de bugs e solicitações pull também são muito apreciadas para manter este projeto em andamento, uma vez que ele já está divergindo do escopo original da pesquisa.
Inicialização multilíngue
Seleção automática de modelos de alinhamento com base na detecção de idioma
Uso de Python
Incorporando diarização de alto-falante
Liberação de modelo, para recursos de memória de baixo GPU
Back-end de sussurro mais rápido
Adicione max-line etc. veja (sussurro utils.py da openai)
Segmentos de nível de frase (caixa de ferramentas nltk)
Melhore a lógica de alinhamento
atualizar exemplos com diarização e destaque de palavras
Saída do subtítulo .ass <- trazer isso de volta (removido na v3)
Adicionar código de benchmarking (TEDLIUM para spd/WER e segmentação de palavras)
Permitir silero-vad como opção alternativa de VAD
Melhorar a diarização (nível de palavra). Mais difícil do que se pensava...
Contate [email protected] para dúvidas.
Este trabalho, e meu doutorado, são apoiados pelo VGG (Visual Geometry Group) e pela Universidade de Oxford.
Claro, isso se baseia no sussurro do openAI. Pega emprestado código de alinhamento importante do tutorial PyTorch sobre alinhamento forçado e usa o maravilhoso pyannote VAD / Diarization https://github.com/pyannote/pyannote-audio
Valiosos modelos de VAD e diarização de [pyannote audio][https://github.com/pyannote/pyannote-audio]
Ótimo back-end de sussurro mais rápido e CTranslate2
Aqueles que apoiaram este trabalho financeiramente
Por fim, obrigado aos contribuidores do sistema operacional deste projeto, por mantê-lo funcionando e identificando bugs.
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

