[Artigo] [Página do Projeto] [Modelo miniFLUX] [Modelo SD3 ⚡️] [demonstração?]
Este é o repositório oficial do Pyramid Flow, um método de geração de vídeo autoregressivo com eficiência de treinamento baseado em Flow Matching . Ao treinar apenas em conjuntos de dados de código aberto , ele pode gerar vídeos de 10 segundos de alta qualidade com resolução de 768p e 24 FPS e, naturalmente, oferece suporte à geração de imagem para vídeo.
| 10s, 768p, 24fps | 5s, 768p, 24fps | Imagem para vídeo |
|---|---|---|
fogos de artifício.mp4 | trailer.mp4 | domingo.mp4 |
2024.11.13 Lançamos o ponto de verificação miniFLUX 768p (até 10s).
Mudamos a estrutura do modelo de SD3 para um mini FLUX para corrigir problemas de estrutura humana. Experimente nosso ponto de verificação de imagem 1024p, ponto de verificação de vídeo 384p (até 5s) e ponto de verificação de vídeo 768p (até 10s). O novo modelo miniflux mostra grande melhoria na estrutura humana e na estabilidade do movimento
2024.10.29 ⚡️⚡️⚡️ Lançamos código de treinamento para VAE, código de ajuste fino para DiT e novos modelos de checkpoints com estrutura FLUX treinados do zero.
2024.10.13 Inferência multi-GPU e descarregamento de CPU são suportados. Use-o com menos de 8 GB de memória GPU, com grande aceleração em múltiplas GPUs.
2024.10.11 ??? A demonstração Hugging Face está disponível. Obrigado @multimodalart pelo commit!
2024.10.10 Divulgamos o relatório técnico, página do projeto e checkpoint do modelo do Pyramid Flow.
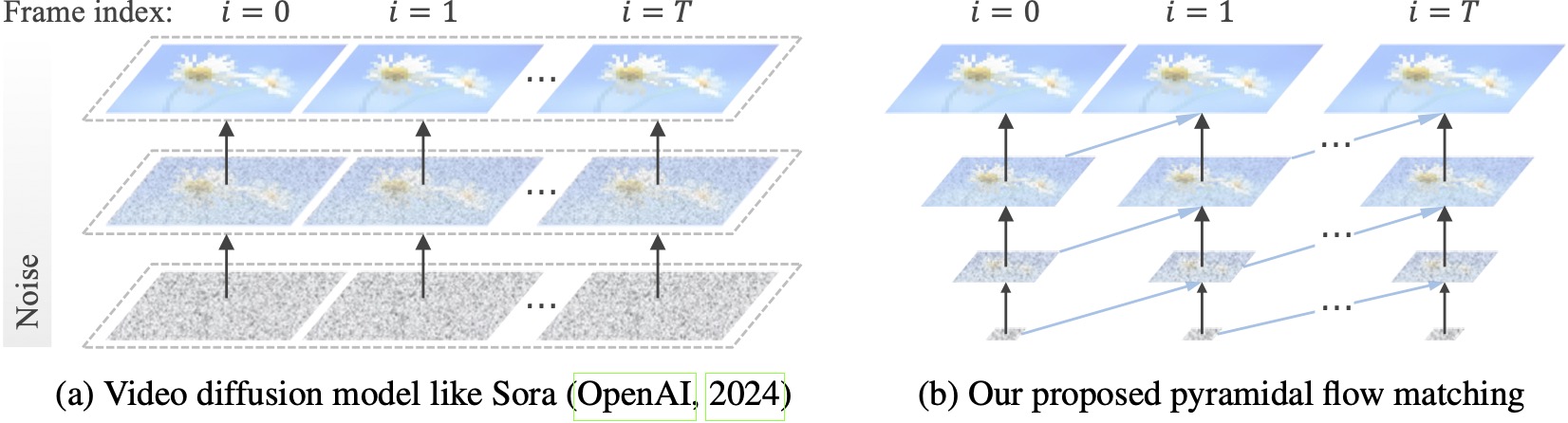
Os modelos de difusão de vídeo existentes operam em resolução total, gastando muito cálculo em latentes muito ruidosas. Por outro lado, nosso método aproveita a flexibilidade da correspondência de fluxo (Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023) para interpolar entre latentes de diferentes resoluções e níveis de ruído, permitindo a geração simultânea e descompressão de conteúdo visual com melhor eficiência computacional. Toda a estrutura é otimizada de ponta a ponta com um único DiT (Peebles & Xie, 2023), gerando vídeos de 10 segundos de alta qualidade com resolução de 768p e 24 FPS em 20,7k horas de treinamento de GPU A100.
Recomendamos configurar o ambiente com conda. A base de código atualmente usa Python 3.8.10 e PyTorch 2.1.2 (guia), e estamos trabalhando ativamente para oferecer suporte a uma gama mais ampla de versões.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtEm seguida, baixe o modelo do Huggingface (existem duas variantes: miniFLUX ou SD3). Os modelos miniFLUX suportam geração de imagem 1024p, vídeo 384p e 768p, e os modelos baseados em SD3 suportam geração de vídeo 768p e 384p. O ponto de verificação de 384p gera vídeo de 5 segundos a 24FPS, enquanto o ponto de verificação de 768p gera vídeo de até 10 segundos a 24FPS.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )Para começar, primeiro instale o Gradio, defina o caminho do modelo como #L36 e execute em sua máquina local:
python app.pyA demonstração do Gradio será aberta em um navegador. Obrigado ao @tpc2233 pelo commit, veja #48 para detalhes.
Ou experimente sem esforço no Hugging Face Space? criado por @multimodalart. Devido aos limites da GPU, esta demonstração online pode gerar apenas 25 frames (exportar a 8FPS ou 24FPS). Duplique o espaço para gerar vídeos mais longos.
Para experimentar rapidamente o Pyramid Flow no Google Colab, execute o código abaixo:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
Para usar nosso modelo, siga o código de inferência em video_generation_demo.ipynb neste link. Recomendamos fortemente que você experimente o último miniflux em pirâmide publicado, que mostra grandes melhorias na estrutura humana e na estabilidade do movimento. Defina o parâmetro model_name como pyramid_flux para usar. Simplificamos ainda mais no seguinte procedimento de duas etapas. Primeiro, carregue o modelo baixado:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()Em seguida, você pode tentar a geração de texto para vídeo de acordo com seus próprios prompts. Observando que a versão 384p suporta apenas 5s agora (defina a temperatura para 16)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )Como um modelo autorregressivo, nosso modelo também suporta geração de imagem para vídeo (condicionado em texto):
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )Também oferecemos suporte a dois tipos de descarregamento de CPU para reduzir os requisitos de memória da GPU. Observe que eles podem sacrificar a eficiência.
cpu_offloading=True à função generate permite inferência com menos de 12 GB de memória GPU. Este recurso foi contribuído por @Ednaordinary, consulte o item 23 para obter detalhes.model.enable_sequential_cpu_offload() antes do procedimento acima permite inferência com menos de 8 GB de memória GPU. Este recurso foi contribuído por @rodjjo, veja #75 para detalhes. Graças ao @niw, os usuários do Apple Silicon (por exemplo, MacBook Pro com M2 24GB) também podem experimentar nosso modelo usando o backend MPS! Consulte #113 para obter detalhes.
Para usuários com múltiplas GPUs, fornecemos um script de inferência que usa paralelismo de sequência para economizar memória em cada GPU. Isso também traz uma grande aceleração, levando apenas 2,5 minutos para gerar um vídeo de 5s, 768p, 24fps em 4 GPUs A100 (contra 5,5 minutos em uma única GPU A100). Execute-o em 2 GPUs com o seguinte comando:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shAtualmente suporta 2 ou 4 GPUs (para versão SD3), com mais configurações disponíveis no script original. Você também pode iniciar uma demonstração Gradio multi-GPU criada por @ tpc2233, consulte o item 59 para obter detalhes.
Spoiler: nem usamos paralelismo de sequência no treinamento, graças aos nossos projetos eficientes de fluxo em pirâmide.
guidance_scale controla a qualidade visual. Sugerimos usar uma orientação em [7, 9] para o ponto de verificação de 768p durante a geração de texto para vídeo e 7 para o ponto de verificação de 384p.video_guidance_scale controla o movimento. Um valor maior aumenta o grau dinâmico e mitiga a degradação da geração autoregressiva, enquanto um valor menor estabiliza o vídeo.Os requisitos de hardware para treinamento VAE são pelo menos 8 GPUs A100. Consulte este documento. Este é um VAE 3D contínuo tipo MAGVIT-v2, que deve ser bastante flexível. Sinta-se à vontade para construir seu próprio modelo gerador de vídeo nesta parte do código de treinamento VAE.
Os requisitos de hardware para o ajuste fino do DiT são pelo menos 8 GPUs A100. Consulte este documento. Fornecemos instruções para versões autorregressivas e não autorregressivas do Pyramid Flow. O primeiro é mais orientado para a investigação e o último é mais estável (mas menos eficiente sem pirâmide temporal).
Os exemplos de vídeo a seguir são gerados em 5s, 768p, 24fps. Para mais resultados, visite a página do nosso projeto.
Tóquio.mp4 | eiffel.mp4 |
ondas.mp4 | trilho.mp4 |
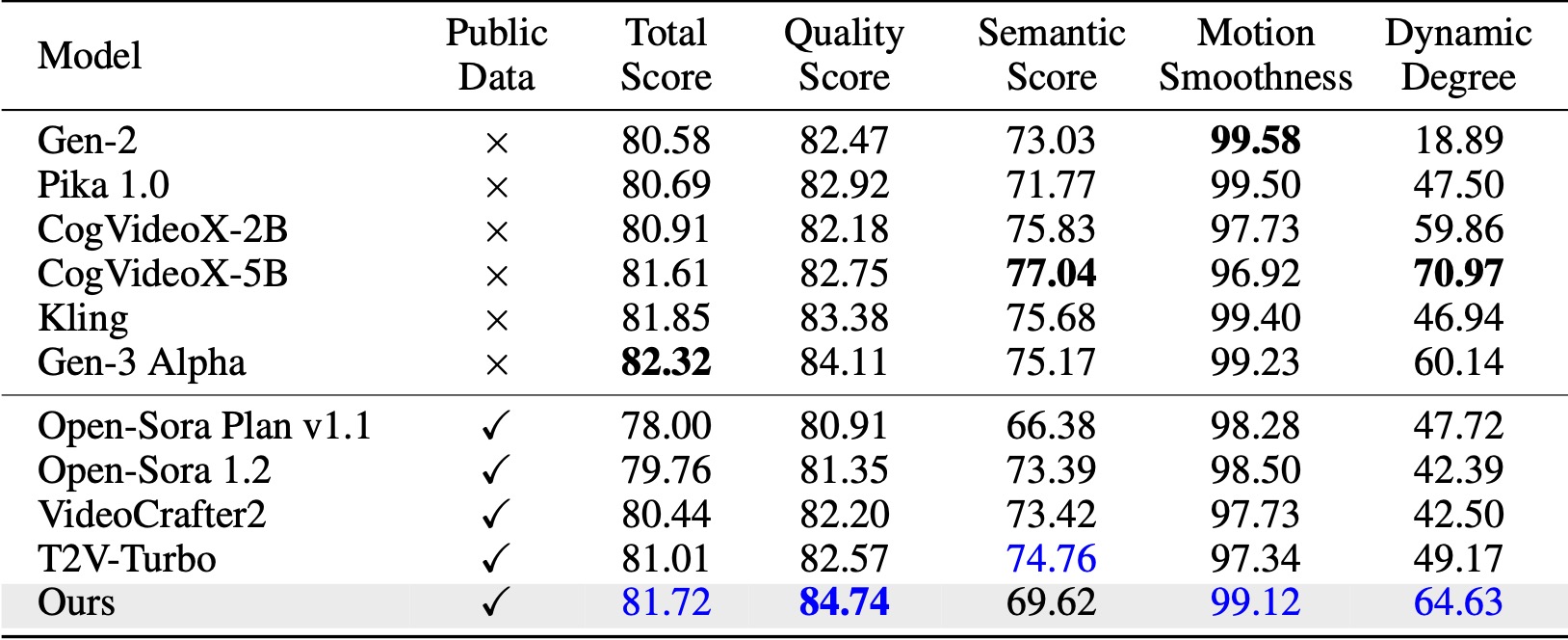
No VBench (Huang et al., 2024), nosso método supera todas as linhas de base de código aberto comparadas. Mesmo com apenas dados de vídeo públicos, ele alcança desempenho comparável a modelos comerciais como Kling (Kuaishou, 2024) e Gen-3 Alpha (Runway, 2024), especialmente no índice de qualidade (84,74 vs. 84,11 da Gen-3) e suavidade de movimento .
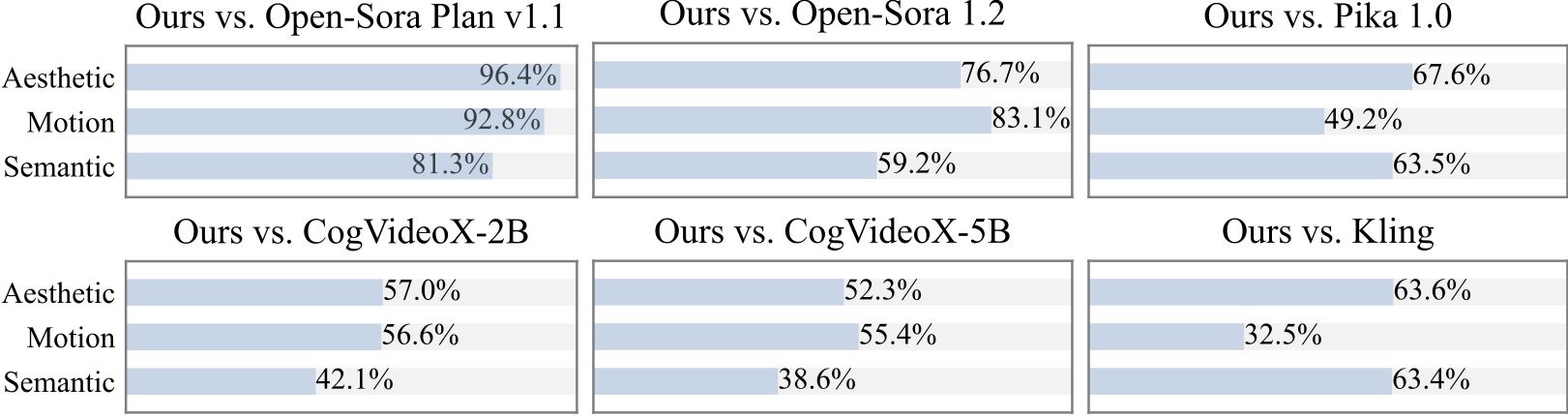
Conduzimos um estudo de usuário adicional com mais de 20 participantes. Como pode ser visto, nosso método é preferido aos modelos de código aberto, como Open-Sora e CogVideoX-2B, especialmente em termos de suavidade de movimento.
Somos gratos pelos seguintes projetos incríveis ao implementar o Pyramid Flow:
Considere dar uma estrela a este repositório e cite o Pyramid Flow em suas publicações se isso ajudar em sua pesquisa.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


