nim anywhere
1.0.0

Por favor, junte-se ao canal Slack #cdd-nim-anywhere se você for um usuário interno, abra um problema se você for externo para qualquer pergunta e feedback.
Um dos principais benefícios do uso de IA para empresas é a capacidade de trabalhar e aprender com seus dados internos. A geração aumentada de recuperação (RAG) é uma das melhores maneiras de fazer isso. A NVIDIA desenvolveu um conjunto de microsserviços chamado microsserviço NIM para ajudar nossos parceiros e clientes a construir um pipeline RAG eficaz com facilidade.
O NIM Anywhere contém todas as ferramentas necessárias para iniciar a integração de NIMs para RAG. Ele é dimensionado nativamente para laboratórios de tamanho normal e até ambientes de produção. Esta é uma ótima notícia para construir uma arquitetura RAG e adicionar facilmente NIMs conforme necessário. Se você não estiver familiarizado com o RAG, ele recupera dinamicamente informações externas relevantes durante a inferência, sem modificar o próprio modelo. Imagine que você é o líder técnico de uma empresa com um banco de dados local contendo informações confidenciais e atualizadas. Você não quer que o OpenAI acesse seus dados, mas precisa que o modelo os entenda para responder às perguntas com precisão. A solução é conectar seu modelo de linguagem ao banco de dados e alimentá-lo com as informações.
Para saber mais sobre por que o RAG é uma excelente solução para aumentar a precisão e a confiabilidade de seus modelos generativos de IA, leia este blog.
Comece a usar o NIM Anywhere agora com as instruções de início rápido e crie seu primeiro aplicativo RAG usando NIMs!
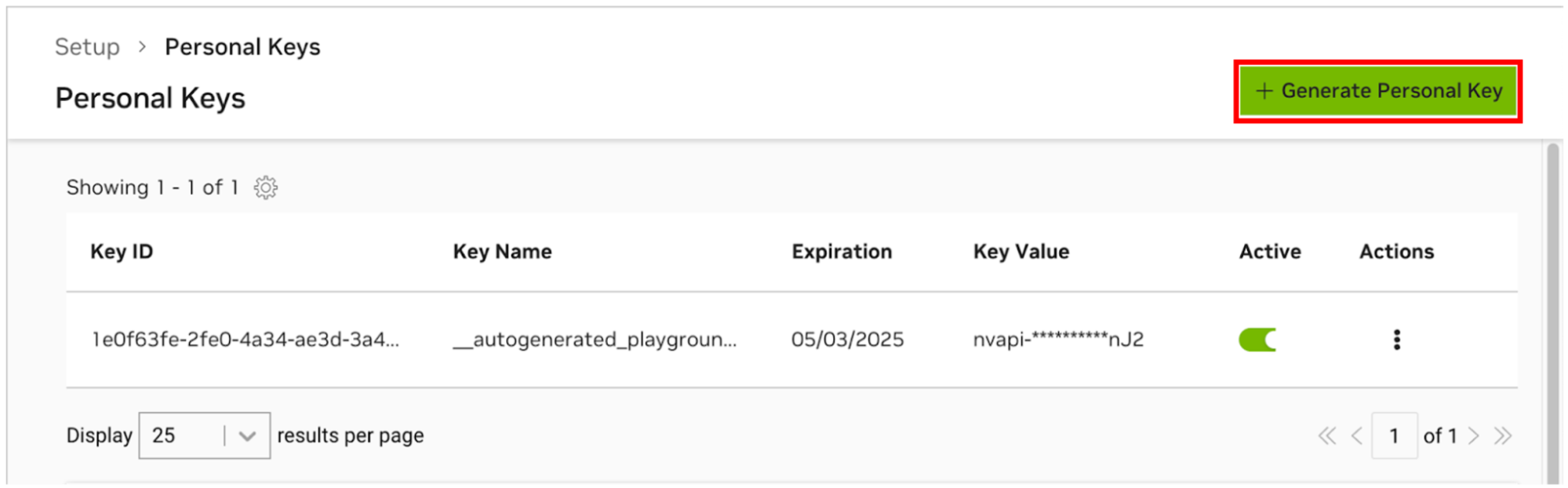
Para permitir que o AI Workbench acesse os recursos de nuvem da NVIDIA, você precisará fornecer uma chave pessoal. Essas chaves começam com nvapi- .
Vá para o Gerenciador de chaves pessoais NGC. Se você for solicitado, registre-se para uma nova conta e faça login.
DICA Você pode encontrar essa ferramenta fazendo login em ngc.nvidia.com, expandindo o menu do seu perfil no canto superior direito, selecionando Configuração e, em seguida, selecionando Gerar chave pessoal .
Selecione Gerar chave pessoal .
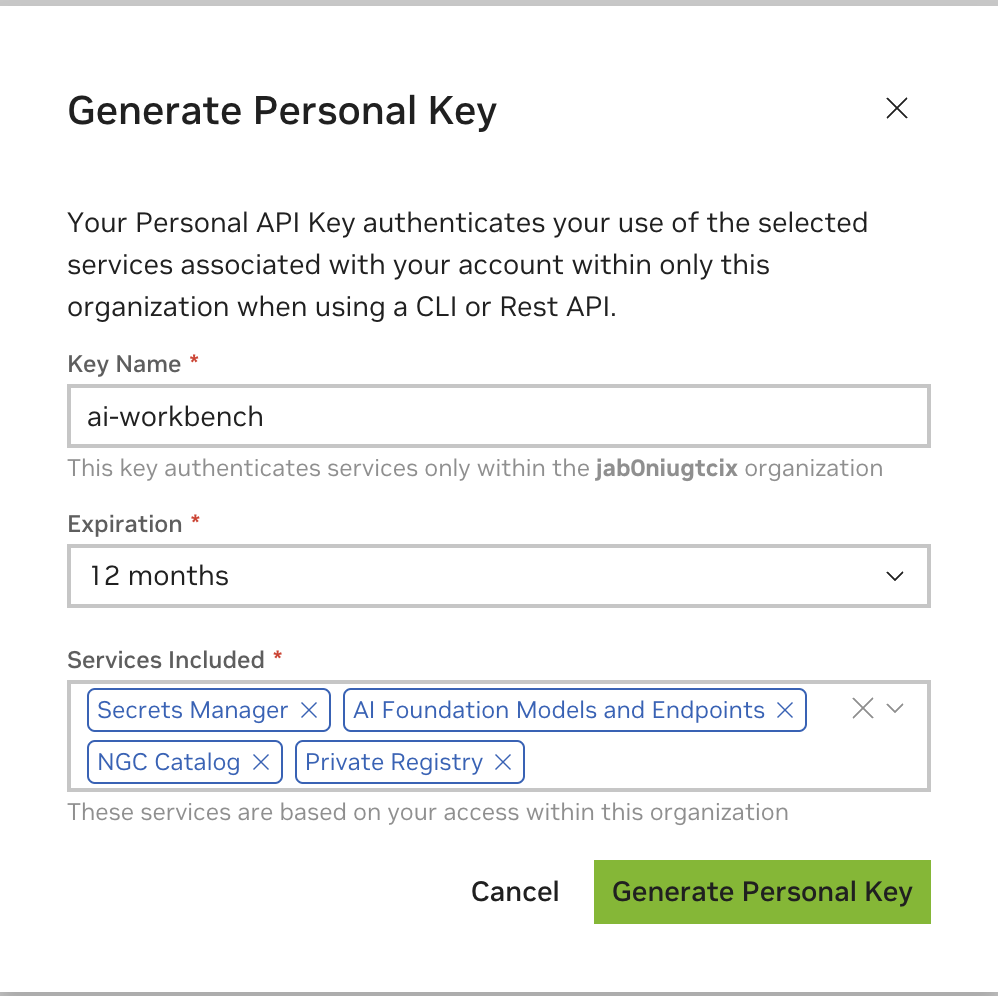
Insira qualquer valor como nome da chave, uma expiração de 12 meses é adequada e selecione todos os serviços. Pressione Gerar chave pessoal quando terminar.
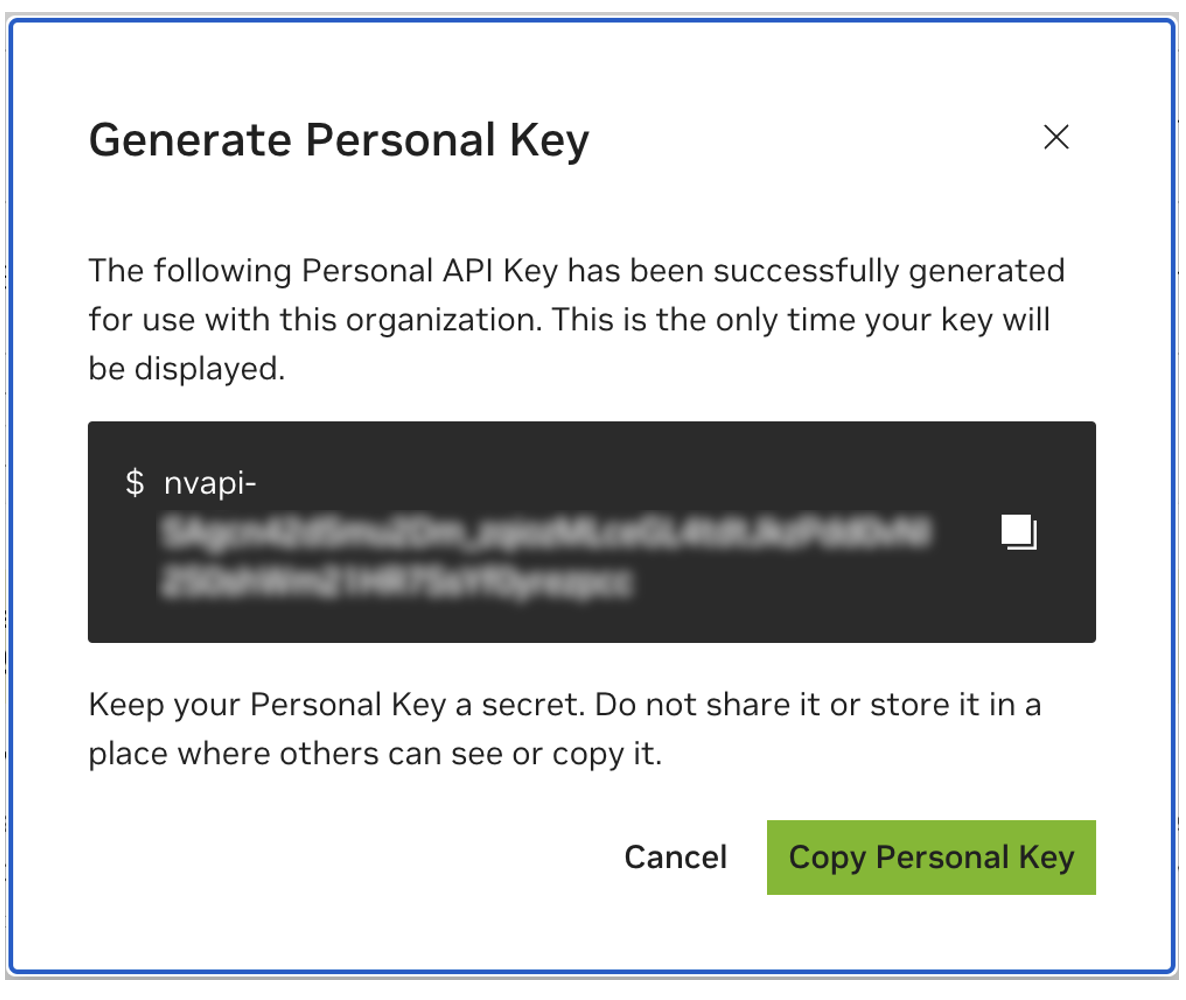
Salve sua chave pessoal para mais tarde. O Workbench precisará dele e não há como recuperá-lo mais tarde. Se a chave for perdida, uma nova deverá ser criada. Proteja esta chave como se fosse uma senha.
Este projeto foi projetado para ser usado com NVIDIA AI Workbench. Embora isso não seja um requisito, executar esta demonstração sem o AI Workbench exigirá trabalho manual, pois a automação e as integrações pré-configuradas podem não estar disponíveis.
Este guia de início rápido assumirá que uma máquina de laboratório remoto está sendo usada para desenvolvimento e que a máquina local é um thin client para acessar remotamente a máquina de desenvolvimento. Isso permite que os recursos de computação permaneçam localizados centralmente e que os desenvolvedores sejam mais portáteis. Observe que a máquina do laboratório remoto deve executar Ubuntu, mas o cliente local pode executar Windows, MacOS ou Ubuntu. Para instalar este projeto apenas localmente, simplesmente ignore a instalação remota.
fluxograma LR
local
ambiente de laboratório subgrafo
máquina de laboratório remoto
fim
local <-.ssh.-> máquina de laboratório remoto
O Ubuntu é necessário se o cliente local também for usado para desenvolvimento. Ao usar uma máquina de laboratório remoto, pode ser Windows, MacOS ou Ubuntu.
Para obter instruções completas, consulte o Guia do usuário do NVIDIA AI Workbench.
Instale o software de pré-requisito
Baixe o instalador NVIDIA AI Workbench e execute-o. Autorize o Windows a permitir que o instalador faça alterações.
Siga as instruções do assistente de instalação. Se você precisar instalar o WSL2, autorize o Windows a fazer as alterações e reinicialize a máquina local quando solicitado. Quando o sistema for reiniciado, o instalador do NVIDIA AI Workbench deverá ser retomado automaticamente.
Selecione Docker como seu tempo de execução do contêiner.
Faça login em sua conta GitHub usando a opção Entrar através de GitHub.com .
Insira suas informações de autor do git, se solicitado.
Para obter instruções completas, consulte o Guia do usuário do NVIDIA AI Workbench.
Instale o software de pré-requisito
Baixe a imagem de disco NVIDIA AI Workbench (arquivo .dmg ) e abra-a.
Arraste o AI Workbench para a pasta Aplicativos e execute o NVIDIA AI Workbench no inicializador de aplicativos. 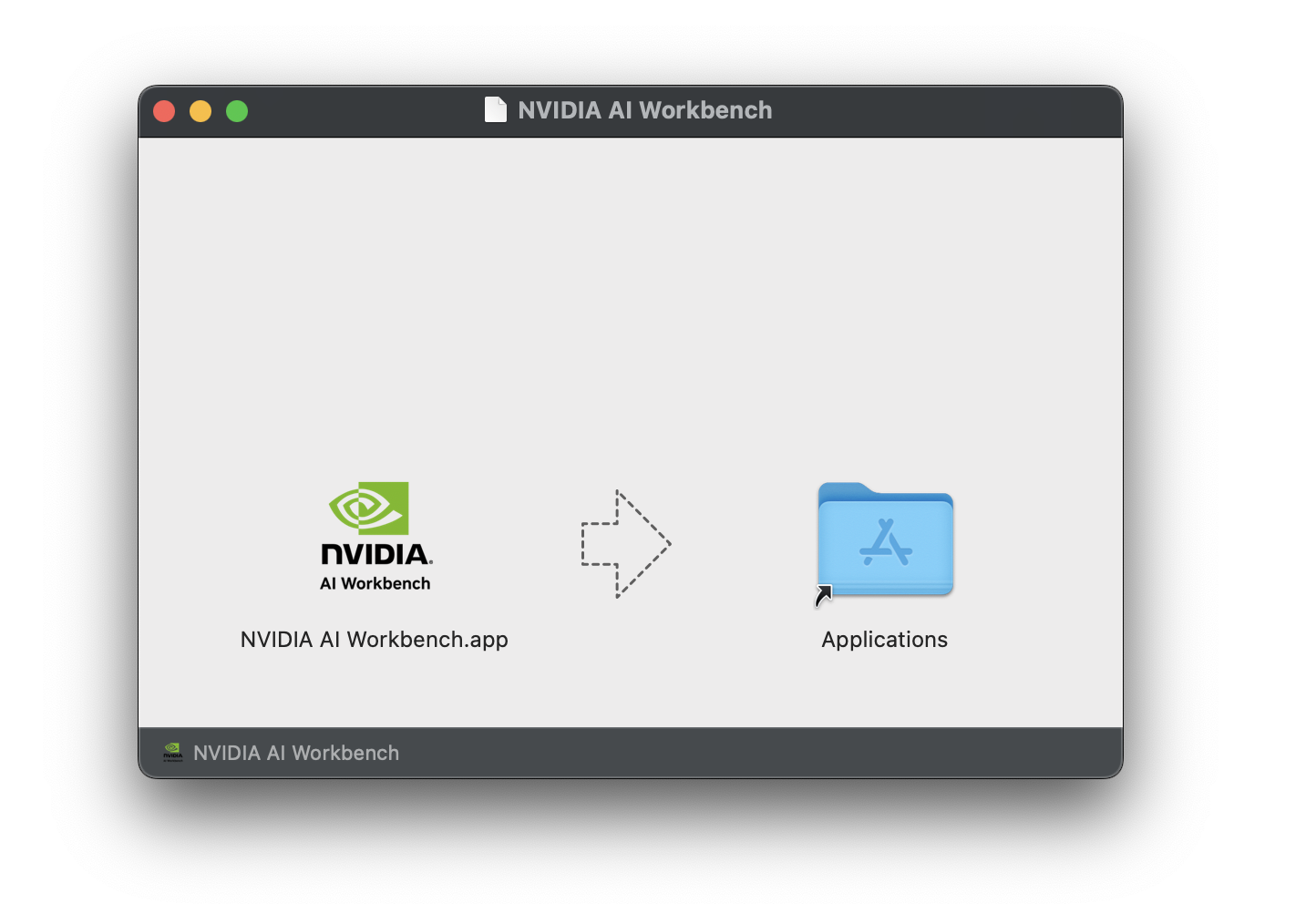
Selecione Docker como seu tempo de execução do contêiner.
Faça login em sua conta GitHub usando a opção Entrar através de GitHub.com .
Insira suas informações de autor do git, se solicitado.
Para obter instruções completas, consulte o Guia do usuário do NVIDIA AI Workbench. Execute esta instalação como o usuário que será o usuário Workbench. Não execute essas etapas como root .
Instale o software de pré-requisito
Baixe o instalador NVIDIA AI Workbench, torne-o executável e execute-o. Você pode tornar o arquivo executável com o seguinte comando:
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench instalará os drivers NVIDIA para você (se necessário). Você precisará reinicializar sua máquina local após a instalação dos drivers e, em seguida, reiniciar a instalação do AI Workbench clicando duas vezes no ícone NVIDIA AI Workbench em sua área de trabalho.
Selecione Docker como seu tempo de execução do contêiner.
Faça login em sua conta GitHub usando a opção Entrar através de GitHub.com .
Insira suas informações de autor do git, se solicitado.
Apenas o Ubuntu é compatível com máquinas remotas.
Para obter instruções completas, consulte o Guia do usuário do NVIDIA AI Workbench. Execute esta instalação como o usuário que usará o Workbench. Não execute essas etapas como root .
Certifique-se de que a autenticação baseada em chave SSH esteja habilitada da máquina local para a máquina remota. Se isso não estiver ativado no momento, os comandos a seguir ativarão isso na maioria das situações. Altere REMOTE_USER e REMOTE-MACHINE para refletir seu endereço remoto.
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINESSH no host remoto. Em seguida, use os seguintes comandos para baixar e executar o NVIDIA AI Workbench Installer.
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench instalará os drivers NVIDIA para você (se necessário). Você precisará reinicializar sua máquina remota após a instalação dos drivers e, em seguida, reiniciar a instalação do AI Workbench executando novamente os comandos da etapa anterior.
Selecione Docker como seu tempo de execução do contêiner.
Faça login em sua conta GitHub usando a opção Entrar através de GitHub.com .
Insira suas informações de autor do git, se solicitado.
Assim que a instalação remota for concluída, o local remoto poderá ser adicionado à instância local do AI Workbench. Abra o aplicativo AI Workbench, clique em Adicionar local remoto e insira as informações necessárias. Quando terminar, clique em Adicionar local .
REMOTE-MACHINE .REMOTE_USER ./home/USER/.ssh/id_rsa .Existem duas maneiras de baixar este projeto para uso local: Clonagem e Bifurcação.
Clonar este repositório é a maneira recomendada de começar. Isso não permitirá modificações locais, mas é o mais rápido para começar. Isso também permite a maneira mais fácil de obter atualizações.
A bifurcação deste repositório é recomendada para desenvolvimento, pois as alterações poderão ser salvas. No entanto, para obter atualizações, o mantenedor do fork terá que extrair regularmente do repositório upstream. Para trabalhar a partir de uma bifurcação, siga as instruções do GitHub e faça referência à URL da sua bifurcação pessoal no restante desta seção.
Abra a janela local do NVIDIA AI Workbench. Na lista de locais exibida, selecione o remoto que você acabou de configurar ou o local, se for trabalhar localmente.
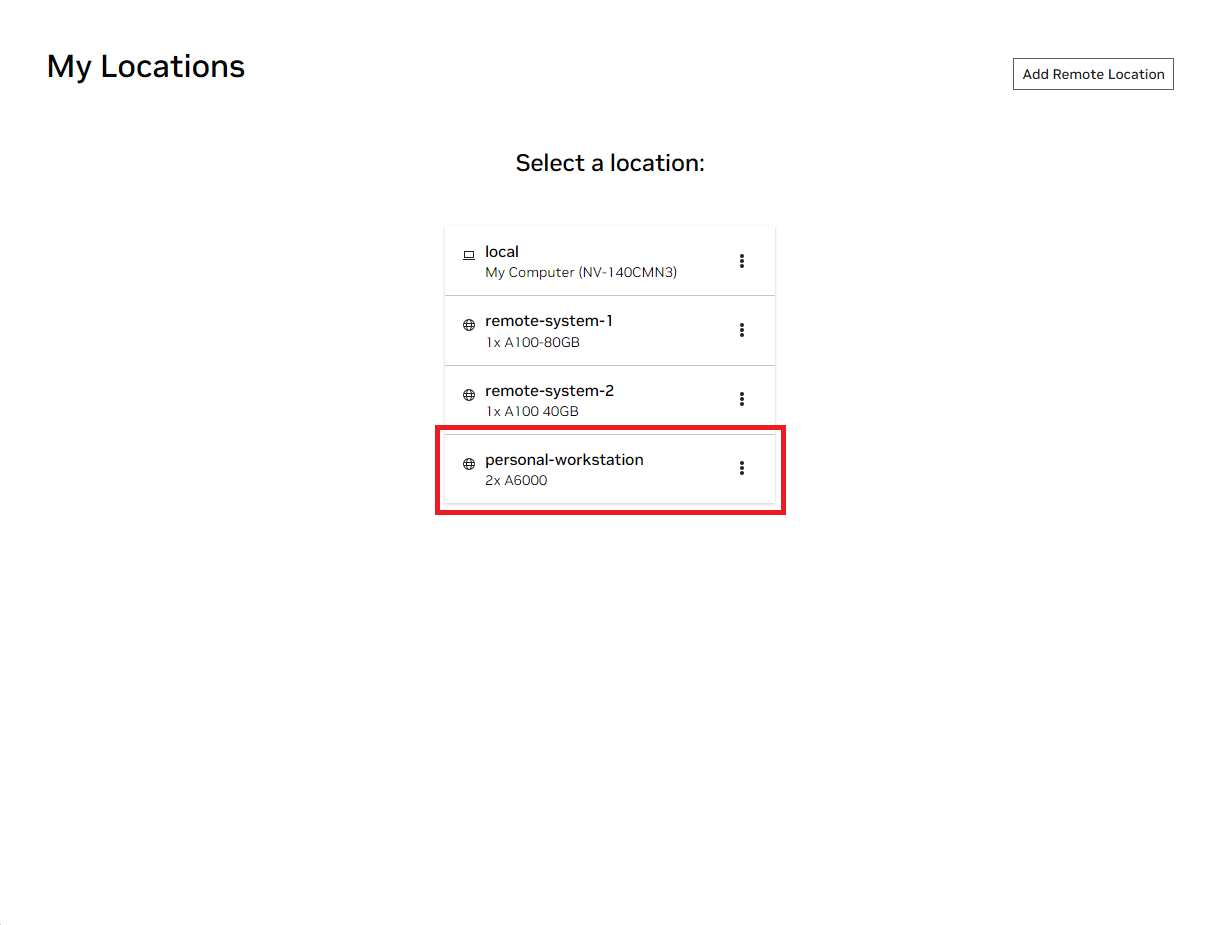
Uma vez dentro do local, selecione Clone Project .
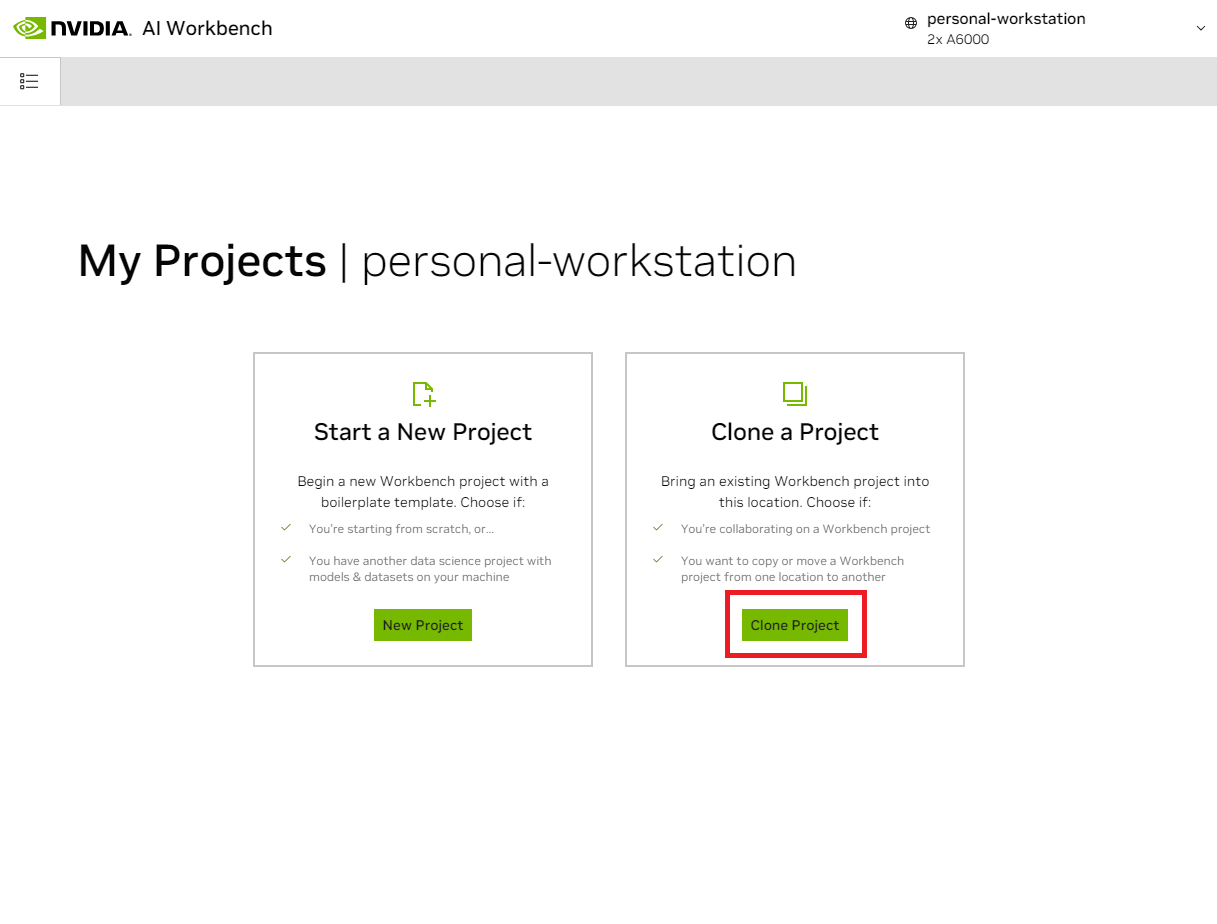
Na janela pop-up 'Clone Project', defina o URL do repositório como https://github.com/NVIDIA/nim-anywhere.git . Você pode deixar o caminho como padrão de /home/REMOTE_USER/nvidia-workbench/nim-anywhere.git . Clique em Clonar.`
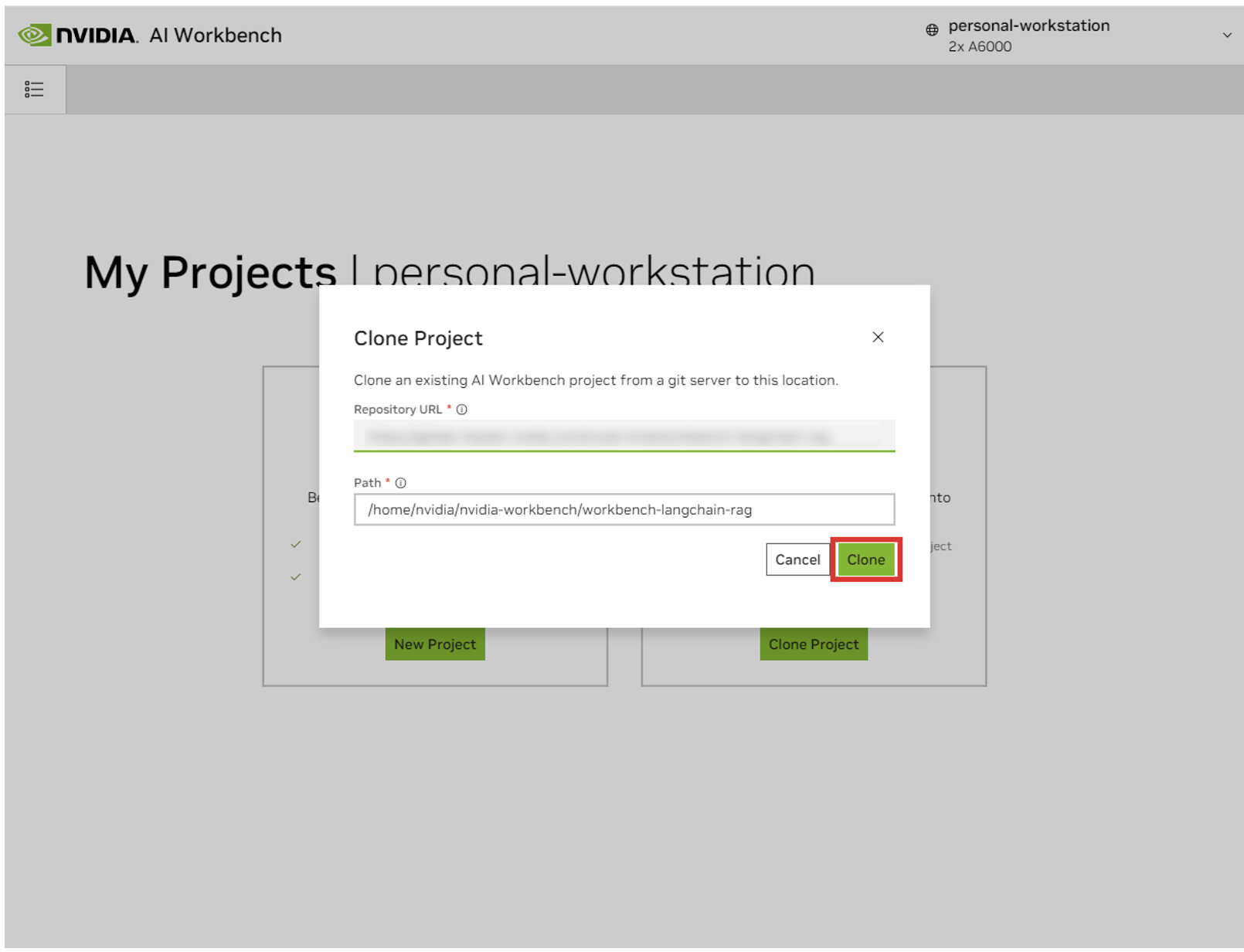
Você será redirecionado para a página do novo projeto. O Workbench inicializará automaticamente o ambiente de desenvolvimento. Você pode visualizar o progresso em tempo real expandindo a Saída na parte inferior da janela.
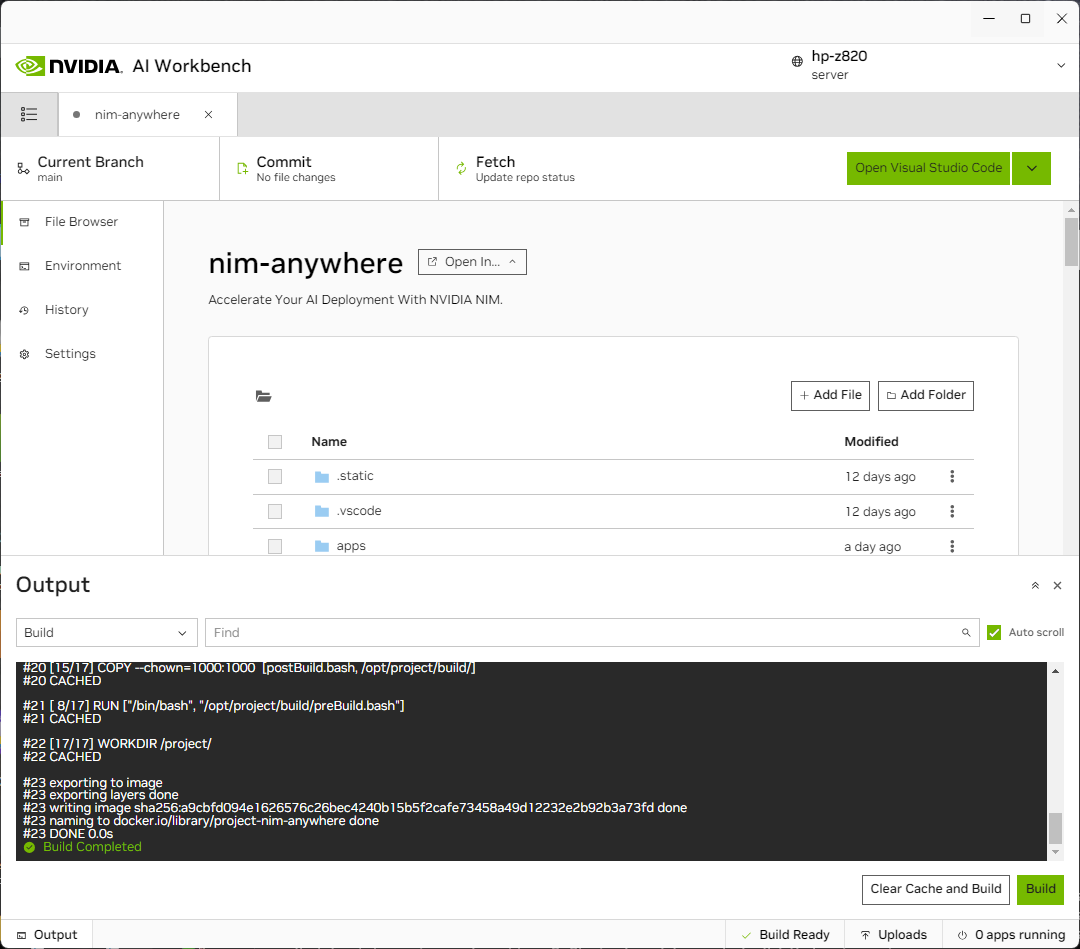
O projeto deve ser configurado para funcionar com recursos locais da máquina.
Antes de executar pela primeira vez, a configuração específica do projeto deve ser fornecida. A configuração do projeto é feita usando a aba Ambiente no painel esquerdo.
Role para baixo até a seção Variáveis e encontre a entrada NGC_HOME . Deve ser definido como algo como ~/.cache/nvidia-nims . O valor aqui é usado pelo ambiente de trabalho. Esse mesmo local também aparece na seção Montagens que monta esse diretório no contêiner.
Role para baixo até a seção Segredos e encontre a entrada NGC_API_KEY . Pressione Configurar e forneça a chave pessoal para NGC gerada anteriormente.
Role para baixo até a seção Montagens . Aqui, existem duas montagens para configurar.
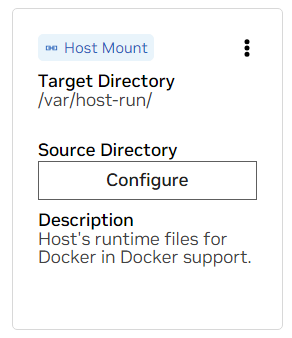
um. Encontre a montagem para /var/host-run. Isso é usado para permitir que o ambiente de desenvolvimento acesse o daemon Docker do host em um padrão chamado Docker out of Docker. Pressione Configurar e forneça o diretório /var/run .
b. Encontre a montagem para /home/workbench/.cache/nvidia-nims. Essa montagem é usada como cache de tempo de execução para NIMs, onde eles podem armazenar arquivos de modelo em cache. Compartilhar esse cache com o host reduz o uso do disco e a largura de banda da rede.
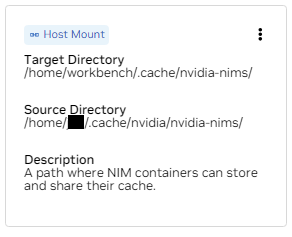
Se você ainda não tem um cache nim ou não tem certeza, use os comandos a seguir para criar um em /home/USER/.cache/nvidia-nims .
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nimsUma reconstrução ocorrerá depois que essas configurações forem alteradas.
Assim que a compilação for concluída com uma mensagem Build Ready , todos os aplicativos serão disponibilizados para você.
Mesmo as cadeias LLM mais básicas dependem de alguns microsserviços adicionais. Eles podem ser ignorados durante o desenvolvimento de alternativas na memória, mas então serão necessárias alterações no código para ir para a produção. Felizmente, o Workbench gerencia esses microsserviços adicionais para ambientes de desenvolvimento.
DICA: Para cada aplicativo, a saída de depuração pode ser monitorada na UI clicando no link Saída no canto inferior esquerdo, selecionando o menu suspenso e escolhendo o aplicativo de interesse.
Todos os aplicativos incluídos neste espaço de trabalho podem ser controlados navegando até Environment > Applications .
Primeiro, ative Milvus Vector DB e Redis . Milvus é usado como uma base de conhecimento não estruturada e Redis é usado para armazenar históricos de conversas.
Depois que esses serviços forem iniciados, o Chain Server poderá ser iniciado com segurança. Contém o código LangChain personalizado para realizar nossa cadeia de raciocínio. Por padrão, ele usará Milvus e Redis locais, mas usará ai.nvidia.com para inferência de modelo LLM e incorporação.
[OPCIONAL]: Em seguida, inicie o LLM NIM . Na primeira vez que o LLM NIM for iniciado, levará algum tempo para baixar a imagem e os modelos otimizados.
um. Durante um início longo, para confirmar que o LLM NIM está iniciando, o progresso pode ser observado visualizando os logs usando o painel Saída na parte inferior esquerda da UI.
b. Se os logs indicarem um erro de autenticação, isso significa que o NGC_API_KEY fornecido não tem acesso aos NIMs. Verifique se ele foi gerado corretamente e em uma organização NGC que tenha suporte ou avaliação NVIDIA AI Enterprise.
c. Se os logs parecerem travados em ..........: Pull complete . ..........: Verifying complete ou ..........: Download complete ; tudo isso é uma saída normal do Docker de que as várias camadas da imagem do contêiner foram baixadas.
d. Quaisquer outras falhas aqui precisam ser abordadas.
Assim que o Chain Server estiver ativo, a interface de bate-papo poderá ser iniciada. Iniciar a interface irá abri-la automaticamente em uma janela do navegador.
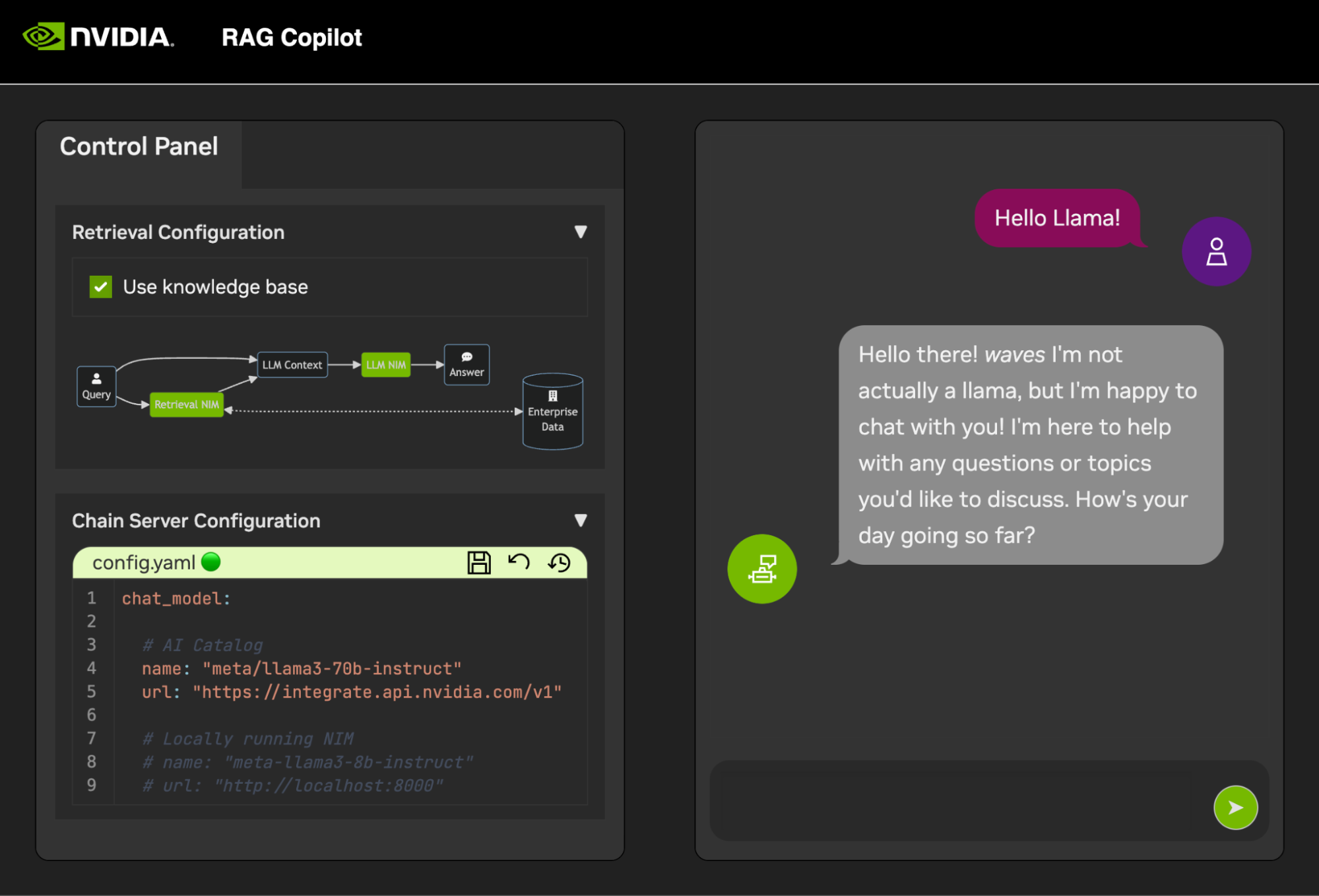
Para começar a desenvolver demonstrações, um conjunto de dados de amostra é fornecido junto com um Jupyter Notebook mostrando como os dados são ingeridos em um banco de dados vetorial.
Para importar a documentação PDF para o banco de dados vetorial, abra o Jupyter usando o inicializador de aplicativos no AI Workbench.
Use o Jupyter Notebook em code/upload-pdfs.ipynb para ingerir o conjunto de dados padrão. Se estiver usando o conjunto de dados padrão, nenhuma alteração será necessária.
Se estiver usando um conjunto de dados personalizado, carregue-o no diretório data/ no Jupyter e modifique o notebook fornecido conforme necessário.
Este projeto contém aplicações para alguns serviços de demonstração, bem como integrações com serviços externos. Tudo isso é orquestrado pelo NVIDIA AI Workbench.
Os serviços de demonstração estão todos na pasta code . O nível raiz da pasta de código possui alguns blocos de anotações interativos destinados a aprofundamentos técnicos. O Chain Server é um aplicativo de exemplo que utiliza NIMs com LangChain. (Observe que o Chain Server aqui oferece a opção de experimentar com e sem RAG). A pasta Chat Frontend contém um servidor de UI interativo para exercitar o servidor de cadeia. Por fim, blocos de anotações de amostra são fornecidos no diretório Avaliação para demonstrar pontuação e validação de recuperação.
mapa mental
raiz((AI Workbench))
Serviços de demonstração
Servidor de cadeia<br />LangChain + NIMs
Frontend<br />IU de demonstração interativa
Avaliação<br />Validar os resultados
Notebooks<br />Uso avançado
Integrações
Redis</br>Histórico de conversas
Banco de dados de vetores Milvus
LLM NIM</br>LLMs otimizados
O Chain Server pode ser configurado com um arquivo de configuração ou variáveis de ambiente.
Por padrão, o aplicativo procurará um arquivo de configuração em todos os locais a seguir. Se vários arquivos de configuração forem encontrados, os valores dos arquivos inferiores na lista terão precedência.
Um caminho de arquivo de configuração adicional pode ser especificado por meio de uma variável de ambiente chamada APP_CONFIG . O valor neste arquivo terá precedência sobre todos os locais de arquivo padrão.
export APP_CONFIG=/etc/my_config.yaml A configuração também pode ser definida usando variáveis de ambiente. Os nomes das variáveis estarão no formato: APP_FIELD__SUB_FIELD Os valores especificados como variáveis de ambiente terão precedência sobre todos os valores dos arquivos.
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
A interface de bate-papo também possui algumas opções de configuração. Eles podem ser configurados da mesma maneira que o servidor da cadeia.
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
Todos os comentários e contribuições para este projeto são bem-vindos. Ao fazer alterações neste projeto, seja para uso pessoal ou para contribuição, é recomendado trabalhar em um fork neste projeto. Assim que as alterações forem concluídas na bifurcação, uma solicitação de mesclagem deverá ser aberta.
Este projeto foi configurado com Linters que foram ajustados para ajudar o código a permanecer consistente sem ser excessivamente pesado. Usamos os seguintes Linters:
O ambiente VSCode incorporado é configurado para executar linting e verificação em tempo real.
Para executar manualmente o linting feito pelos pipelines de CI, execute /project/code/tools/lint.sh . Testes individuais podem ser executados especificando-os por nome: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] . Executar a ferramenta lint no modo de correção corrigirá automaticamente o que for possível executando o Black, atualizando o README e limpando a saída da célula em todos os Jupyter Notebooks.
O frontend foi projetado em um esforço para minimizar o desenvolvimento necessário de HTML e Javascript. É fornecido um Application Shell com marca e estilo, criado com HTML, Javascript e CSS simples. Ele foi projetado para ser fácil de personalizar, mas nunca deve ser obrigatório. Os componentes interativos do frontend são todos criados no Gradio e montados no shell do aplicativo usando iframes.
Na parte superior do shell do aplicativo há um menu que lista as visualizações disponíveis. Cada visualização pode ter seu próprio layout composto por uma ou algumas páginas.
As páginas contêm os componentes interativos para uma demonstração. O código das páginas está no diretório code/frontend/pages . Para criar uma nova página:
__init__.py no novo diretório que usa Gradio para definir a UI. O layout dos Gradio Blocks deve ser definido em uma variável chamada page .chat .code/frontend/pages/__init__.py , importe a nova página e adicione-a à lista __all__ .NOTA: Criar uma nova página não a adicionará ao frontend. Deve ser adicionado a uma visualização para aparecer no Frontend.
A visualização consiste em uma ou algumas páginas e deve funcionar independentemente umas das outras. As visualizações são todas definidas no módulo code/frontend/server.py . Todas as visualizações declaradas serão automaticamente adicionadas à barra de menu do Frontend e disponibilizadas na UI.
Para definir uma nova visualização, modifique a lista denominada views . Esta é uma lista de objetos View . A ordem dos objetos definirá sua ordem no menu Frontend. A primeira visualização definida será o padrão.
Os objetos de visualização descrevem o nome e o layout da visualização. Eles podem ser declarados da seguinte forma:
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
) Todas as declarações de página, View.left ou View.right , são opcionais. Se não forem declarados, os iframes associados no layout da web ficarão ocultos. Os outros iframes serão expandidos para preencher as lacunas. Os diagramas a seguir mostram os vários layouts.
bloco-beta
colunas 1
menu["barra de menu"]
bloquear
colunas 2
esquerda direita
fim
bloco-beta
colunas 1
menu["barra de menu"]
bloquear
colunas 1
esquerda:1
fim
O frontend contém alguns ativos de marca que podem ser personalizados para diferentes casos de uso.
O frontend contém um logotipo no canto superior esquerdo da página. Para modificar o logotipo, é necessário um SVG do logotipo desejado. O shell do aplicativo pode então ser facilmente modificado para usar o novo SVG, modificando o arquivo code/frontend/_assets/index.html . Existe um único div com um ID de logo . Esta caixa contém um único SVG. Atualize isso para a definição SVG desejada.
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > O estilo do App Shell é definido em code/frontend/_static/css/style.css . As cores neste arquivo podem ser modificadas com segurança.
O estilo das várias páginas é definido em code/frontend/pages/*/*.css . Esses arquivos também podem exigir modificação para esquemas de cores personalizados.
O tema Gradio é definido no arquivo code/frontend/_assets/theme.json . As cores neste arquivo podem ser modificadas com segurança para a marca desejada. Outros estilos neste arquivo também podem ser alterados, mas podem causar alterações significativas no frontend. A documentação do Gradio contém mais informações sobre os temas do Gradio.
NOTA: Este é um tópico avançado que a maioria dos desenvolvedores nunca irá exigir.
Ocasionalmente, pode ser necessário ter diversas páginas em uma visualização que se comuniquem entre si. Para isso, é utilizada a estrutura de mensagens postMessage do Javascript. Qualquer mensagem confiável postada no shell do aplicativo será encaminhada para cada iframe onde as páginas podem tratar a mensagem conforme desejado. A página control usa esse recurso para modificar a configuração da página chat .
A seguir, uma mensagem será postada no shell do aplicativo ( window.top ). A mensagem conterá um dicionário com a chave use_kb e um valor true. Usando Gradio, este Javascript pode ser executado por qualquer evento Gradio.
window . top . postMessage ( { "use_kb" : true } , '*' ) ; Esta mensagem será enviada automaticamente para todas as páginas pelo shell do aplicativo. O código de exemplo a seguir consumirá a mensagem em outra página. Este código será executado de forma assíncrona quando um evento message for recebido. Se a mensagem for confiável, um componente Gradio com elem_id de use_kb será atualizado para o valor especificado na mensagem. Desta forma, o valor de um componente Gradio pode ser duplicado nas páginas.
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; O README é renderizado automaticamente; edições diretas serão substituídas. Para modificar o README você precisará editar os arquivos de cada seção separadamente. Todos esses arquivos serão combinados e o README será gerado automaticamente. Você pode encontrar todos os arquivos relacionados na pasta docs .
A documentação é escrita em Github Flavored Markdown e depois renderizada em um arquivo Markdown final pelo Pandoc. Os detalhes deste processo são definidos no Makefile. A ordem dos arquivos gerados é definida em docs/_TOC.md . A documentação pode ser visualizada na janela do navegador de arquivos do Workbench.
O arquivo de cabeçalho é o primeiro arquivo usado para compilar a documentação. Este arquivo pode ser encontrado em docs/_HEADER.md . O conteúdo deste arquivo será escrito literalmente, sem qualquer manipulação, no README antes de mais nada.
O arquivo de resumo contém uma descrição rápida e um gráfico que descreve este projeto. O conteúdo deste arquivo será adicionado ao README imediatamente após o cabeçalho e logo antes do índice. Este arquivo é processado pelo Pandoc para incorporar imagens antes de gravá-las no README.
O arquivo mais importante para a documentação é o arquivo do índice em docs/_TOC.md . Este arquivo define uma lista de arquivos que devem ser concatenados para gerar o manual README final. Os arquivos devem estar nesta lista para serem incluídos.
Salve todo o conteúdo estático, incluindo imagens, na pasta _static . Isso ajudará na organização.
Pode ser útil ter documentos que se atualizem e se escrevam sozinhos. Para criar um documento dinâmico, basta criar um arquivo executável que grave o documento formatado Markdown em stdout. Durante o tempo de construção, se uma entrada no arquivo de índice for executável, ela será executada e seu stdout será usado em seu lugar.
Quando um commit relacionado à documentação é enviado, uma ação do GitHub renderizará a documentação. Quaisquer alterações no README serão automaticamente confirmadas.
A maior parte da configuração do ambiente de desenvolvimento acontece com variáveis de ambiente. Para fazer alterações permanentes nas variáveis de ambiente, modifique variables.env ou use a interface do usuário do Workbench.
Este projeto usa um ambiente Python em /usr/bin/python3 e as dependências são gerenciadas com pip . Como todo o desenvolvimento é feito dentro de um contêiner, quaisquer alterações no ambiente Python serão efêmeras. Para instalar permanentemente um pacote Python, adicione-o ao arquivo requirements.txt ou use a IU do Workbench.
O ambiente de desenvolvimento é baseado no Ubuntu 22.04. O usuário principal tem acesso sudo sem senha, mas todas as alterações no sistema serão efêmeras. Para fazer alterações permanentes nos pacotes instalados, adicione-os ao arquivo [ apt.txt ]. Para fazer outras alterações no sistema operacional, como manipulação de arquivos, adição de variáveis de ambiente, etc; use os arquivos postBuild.bash e preBuild.bash .
Normalmente, é uma boa prática atualizar as dependências mensalmente para garantir que nenhum CVE seja exposto através de dependências mal utilizadas. O processo a seguir pode ser usado para corrigir este projeto. Recomenda-se executar o teste de regressão após o patch para garantir que nada foi quebrado na atualização.
/project/code/tools/bump.sh ./project/code/tools/audit.sh . Este script imprimirá um relatório de todos os pacotes Python em estado de aviso e todos os pacotes em estado de erro. Qualquer coisa em estado de erro deve ser resolvida, pois terá CVEs ativos e vulnerabilidades conhecidas.

