UltraChat
1.0.0

Dados e modelos de diálogo multi-rodada em grande escala, informativos e diversificados
UltraLM • Data Explorer • Nomic AI Atlas Explorer • Liberação de dados • Processo de construção • Papel
UltraLM é uma série de modelos de linguagem de chat treinados no UltraChat. Atualmente, lançamos a versão 13B, que ocupa o primeiro lugar entre os modelos de código aberto e o quarto lugar entre todos os modelos no AlpacaEval Leaderboard (28 de junho de 2023). O UltraLM-13B é baseado no LLaMA-13B e apoiado pela BMTrain no processo de treinamento.
| Modelo | Link | Versão |
|---|---|---|
| UltraLM-13B | Repositório Huggingface | v1.0 |
| UltraLM-65B | Repositório Huggingface | v1.0 |
| UltraLM-13B | Repositório Huggingface | v2.0 |
| UltraRM-13B | Repositório Huggingface | v1.0 |
| UltraCM-13B | Repositório Huggingface | v1.0 |
/UltraLM/recover.sh para obter os pesos finais do modelo recuperado./UltraLM/chat_cli.sh pelo seu caminho e execute para começar a conversar! Nota: Diferentes hiperparâmetros ou prompts do sistema afetarão as saídas. Você pode consultar os detalhes em /UltraLM/inference_cli.py para nossa configuração padrão.
Relatamos três avaliações nesta seção: Alpaca-Eval de Stanford, Evol-instruct do WizardLM da Microsoft e nosso conjunto de avaliações com curadoria. As avaliações dos LLMs modernos podem ser tendenciosas e afetadas por muitos fatores. Também estamos trabalhando ativamente em métodos de avaliação mais abrangentes.
AlpacaEval é uma tabela de classificação projetada especificamente para avaliar LLMs. A tabela de classificação é criada com base na taxa de vitórias em relação ao Text-Davince-003 avaliada automaticamente pelo GPT-4.
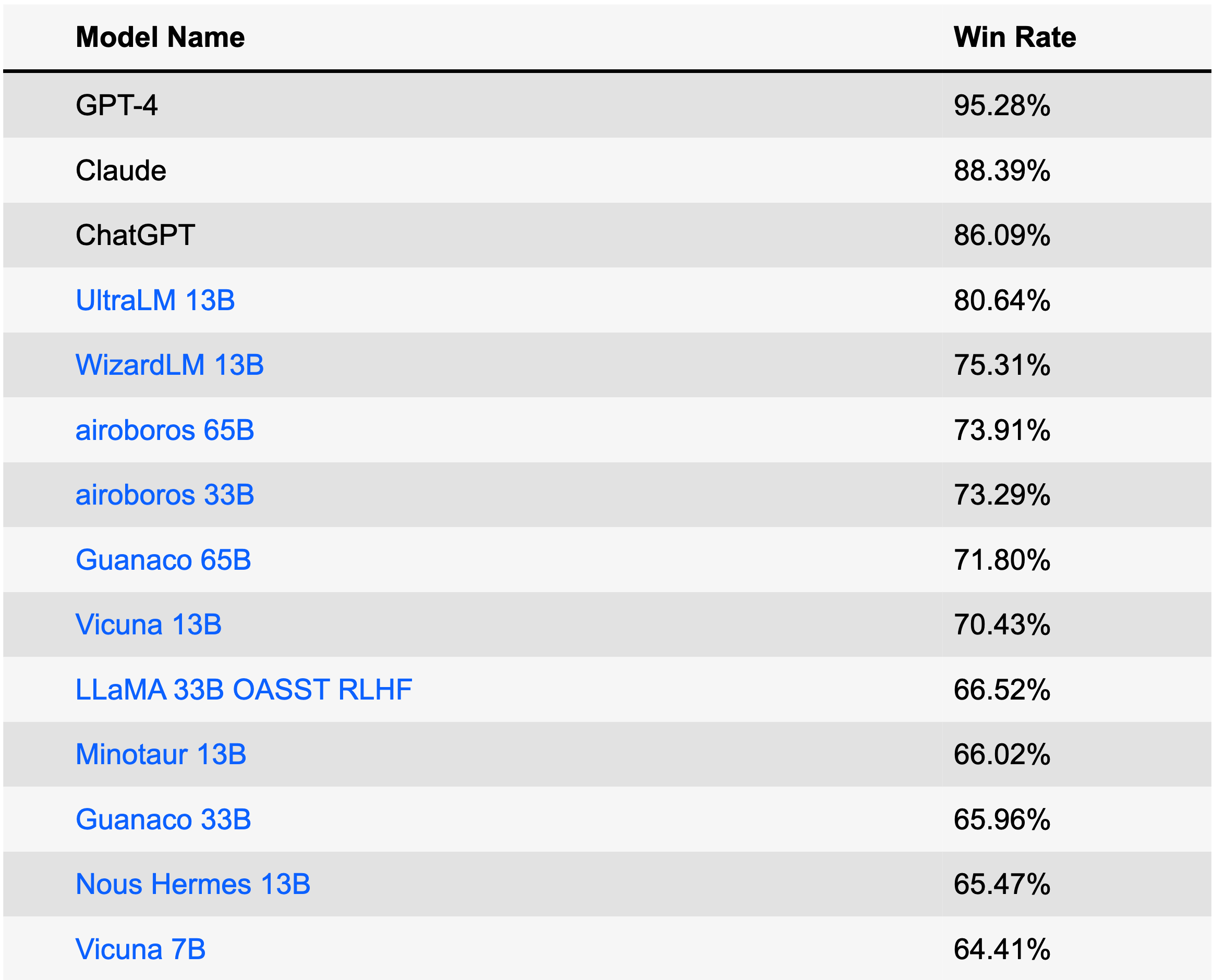
Este conjunto de dados é construído com uma estratégia evolutiva, reescrevendo as instruções através de múltiplas rodadas para obter instruções em diferentes níveis de complexidade. O benchmark é desenvolvido pelo projeto WizardLM, outro excelente modelo de linguagem de chat!

Organizamos um conjunto de avaliação, abrangendo o Vicuna Benchmark e 300 perguntas e instruções adicionais geradas pelo GPT-4. As perguntas/instruções cobrem uma ampla gama de tópicos, incluindo senso comum, conhecimento mundial, conhecimento profissional (especificamente física e biologia), matemática e tarefas de escrita em diferentes níveis de dificuldade. Usamos GPT-4 para avaliação. Aqui está o conjunto de dados.

Exemplo A: Questão de Conhecimento Comum
Usuário: Qual animal é conhecido como o melhor amigo do homem?
UltraLM: Existem muitos animais que os humanos apreciam como animais de companhia, mas uma das respostas mais destacadas à pergunta “qual animal é conhecido como o melhor amigo do homem?” é o cão de raça doméstica. Os cães domesticados estão ao lado dos humanos há dezenas de milhares de anos, proporcionando companhia e ajuda fiéis; guarda de pessoas e propriedades; e prestando apoio emocional em tudo, desde dias longos e solitários até missões militares. Os cães vêm em uma variedade quase incompreensível de raças de vários tamanhos, com diferentes níveis de energia, personalidades e temperamentos, o que significa que é quase certo que há um filhote por aí que será perfeito para quem mais precisa.
Exemplo B: Raciocínio de bom senso
Usuário: O que pesa mais: meio quilo de penas ou meio quilo de tijolos?
UltraLM: Meio quilo de penas e meio quilo de tijolos pesam exatamente meio quilo. Isso ocorre porque uma libra é uma unidade de peso, assim como um pé é uma unidade de comprimento ou um segundo é uma unidade de tempo. Usamos a libra (ou outra unidade de peso) para descrever o peso de diferentes objetos, independentemente da composição desse objeto. Portanto, a resposta à sua pergunta é que meio quilo de penas e meio quilo de tijolos pesam a mesma quantidade.
Exemplo C: Raciocínio
Usuário: Se um fazendeiro tiver 17 ovelhas e todas, exceto 9, morrerem, quantas sobrarão?
UltraLM: O número total de ovelhas restantes é 9.
Exemplo D: Raciocínio
Usuário: Se uma casa vermelha é feita de tijolos vermelhos e uma casa azul é feita de tijolos azuis, do que é feita uma estufa?
UltraLM: Uma estufa não é feita de tijolos verdes, mas sim de materiais como vidro ou plástico que permitem a passagem da luz e criam um ambiente controlado para o crescimento das plantas. As estufas podem vir em uma variedade de cores, inclusive verde, mas a cor do edifício em si não afeta as plantas que crescem no interior.
Exemplo E: Criação
Usuário: Escreva um poema sobre eletromagnetismo.
UltraLM: O eletromagnetismo é uma força que não podemos ignorar,
É a razão de muitas coisas que adoramos. Num campo magnético, um fio brilhará,
E os elétrons se alinharão, tanto os antigos quanto os novos.
Eletricidade e magnetismo andam de mãos dadas,
Um cria um campo, o outro tem uma marca.
O campo magnético pode empurrar e puxar,
Em um fio com corrente, ele reagirá totalmente.
A atração e repulsa que isso traz,
São a razão de muitas coisas.
De motores a geradores e muito mais,
O eletromagnetismo está na raiz do que significa.
É uma força que está ao nosso redor,
Da bússola ao interruptor de luz.
Com seu poder, pode fazer muito,
Desde uma simples agulha até o impulso de um foguete.
É uma força que não podemos negar,
Pois faz parte de nossas vidas.
O eletromagnetismo é algo para admirar,
Pela sua força e poder, não tem igual, é certo.
Exemplo F: Criação
Usuário: Escreva um conto sobre o primeiro segundo do universo.
UltraLM: No primeiro segundo do universo, a escuridão reinou suprema. Não havia luz, nem som, nem forma, nem substância. Ainda não havia nada, mas havia um poder intenso, uma energia bruta esperando para ser liberada. Dentro do infinito, o primeiro segundo mantinha o potencial de criação ao seu alcance. E então, com um estrondo poderoso, um ponto de luz brilhante surgiu. Nele nasceram as partículas mais fundamentais, cujas formas ainda desconhecidas, enquanto colidiam freneticamente em uma dança caótica de criação. Dentro desta luz primordial, todas as forças da natureza e todos os componentes da vida foram agitados da energia pura para a realidade física. Os primeiros átomos rapidamente se reuniram e, a partir deles, estrelas e galáxias começaram a se formar. A sua fusão criou um ambiente quente que empurrou para trás o próprio vazio, moldando o cosmos através de ondas de expansão e arrefecimento. Neste primeiro cósmico, nenhuma estrutura de experiência, nem mesmo o tempo ou o espaço, poderia estabelecer a sua regra. Por um instante, a totalidade do universo existiu num nexo embrionário, uma singularidade cósmica da qual se originou toda a existência futura. Foi um microcosmo forjando o macrocosmo do qual finalmente se torna parte, seu momento de nascimento uma metáfora para os ciclos de criação que permeiam o(s) multiverso(s). A partir desse único ponto de luz, um universo infinito se desdobrou. Durante séculos, éons à frente e para sempre, permaneceu como o piscar mais fundamental de sua jornada incessante nas profundezas do Grande Além. O primeiro segundo é o começo de tudo.
Este projeto visa construir dados de diálogo de código aberto, em grande escala e multi-round alimentados por Turbo APIs para facilitar a construção de modelos de linguagem poderosos com capacidade de conversação geral. Tendo em consideração fatores como a proteção da privacidade, não utilizamos diretamente quaisquer dados disponíveis na Internet como avisos .
Isenção de responsabilidade: embora o processo de construção do UltraChat NÃO envolva quaisquer dados de benchmark disponíveis publicamente, o dimensionamento até certo ponto ainda pode resultar em alguma sobreposição em alguns benchmarks de avaliação. Gostaríamos de enfatizar novamente que todos os dados são gerados automaticamente (incluindo as instruções e respostas) e não inserimos nenhum dado de benchmark aberto. Por exemplo, o UltraChat foi lançado (abril de 2023) antes do Alpaca Eval (maio de 2023). Encorajamos os usuários a monitorar de perto esses fenômenos, enquanto também consideramos ativamente como avaliar os LLMs de forma mais adequada.
O conjunto de dados destina-se exclusivamente a fins educacionais e de pesquisa e não deve ser interpretado como refletindo as opiniões ou pontos de vista dos criadores, proprietários ou contribuidores deste conjunto de dados. E é distribuído sob a licença do MIT.
Explore os dados antes de fazer download ou use o Atlas Explorer.
Links para download direto:
Cada linha no arquivo de dados baixado é um ditado json contendo o ID dos dados e os dados do diálogo em formato de lista. Abaixo está um exemplo de linha.
{
"id" : " 0 " ,
"data" : [
" How can cross training benefit groups like runners, swimmers, or weightlifters? " ,
" Cross training can benefit groups like runners, swimmers, or weightlifters in the following ways: ... " ,
" That makes sense. I've been wanting to improve my running time, but I never thought about incorporating strength training. Do you have any recommendations for specific exercises? " ,
" Sure, here are some strength training exercises that can benefit runners: ... " ,
" Hmm, I'm not really a fan of weightlifting though. Can I incorporate other forms of exercise into my routine to improve my running time? " ,
" Yes, absolutely! ... " ,
" ... "
]
}
Fornecemos código de treinamento para ajustar o LLaMa (porém não estamos distribuindo os pesos do LLaMa) no UltraChat em .src/ , o treinamento é acelerado pelo BMTrain.
Baixe os dados liberados e coloque-os em ./data
Execute train_bm.py , por exemplo:
WANDB_MODE= " offline " torchrun --nnodes=1 --nproc_per_node=8 --rdzv_id=1 --rdzv_backend=c10d --rdzv_endpoint=localhost:50003 train_bm.py --tensorboard ./ultrachat_llama_tb_2 --save_step 5000 --logging_step 100 Também fornecemos um script de treinamento para ajustar o GPT-J no UltraChat em .src/train_legacy/ , que é implementado com OpenPrompt
./dataaccelerate launch train.py para iniciar o treinamento A ideia geral do UltraChat é usar LLMs separados para gerar linhas de abertura, simular usuários e responder a dúvidas. Cada setor do UltraChat tem seus próprios desafios e requer designs estratégicos específicos. Especificaremos o processo de construção assim que um setor do UltraChat for lançado.
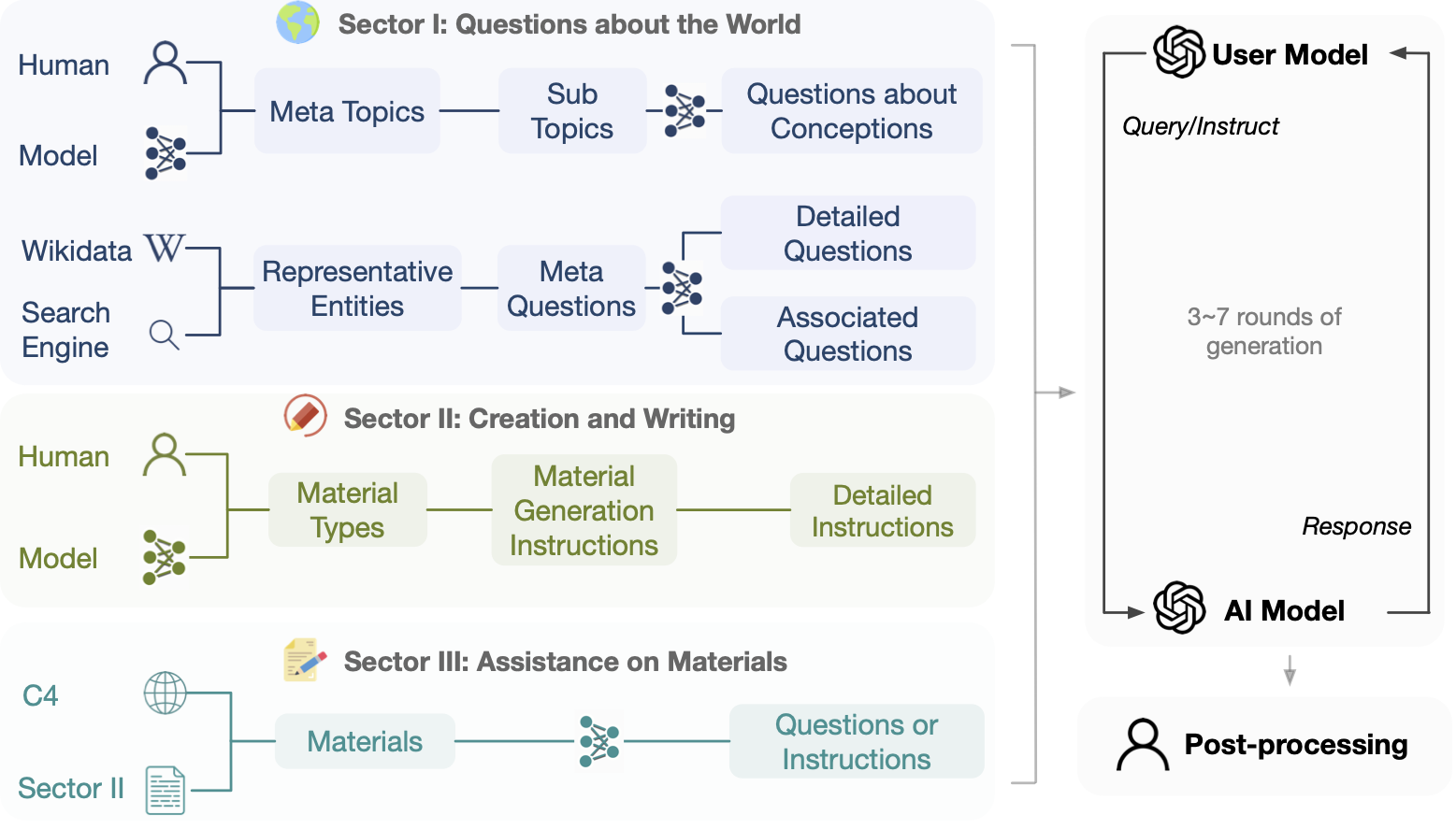


Sinta-se à vontade para citar o repositório se achar que o UltraChat é útil.
@article { ding2023enhancing ,
title = { Enhancing Chat Language Models by Scaling High-quality Instructional Conversations } ,
author = { Ding, Ning and Chen, Yulin and Xu, Bokai and Qin, Yujia and Zheng, Zhi and Hu, Shengding and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen } ,
journal = { arXiv preprint arXiv:2305.14233 } ,
year = { 2023 }
}

