BLIVA
1.0.0
Wenbo Hu*, Yifan Xu*, Yi Li, Weiyue Li, Zeyuan Chen e Zhuowen Tu. *Contribuição igual
UC San Diego , Coinbase Global, Inc.
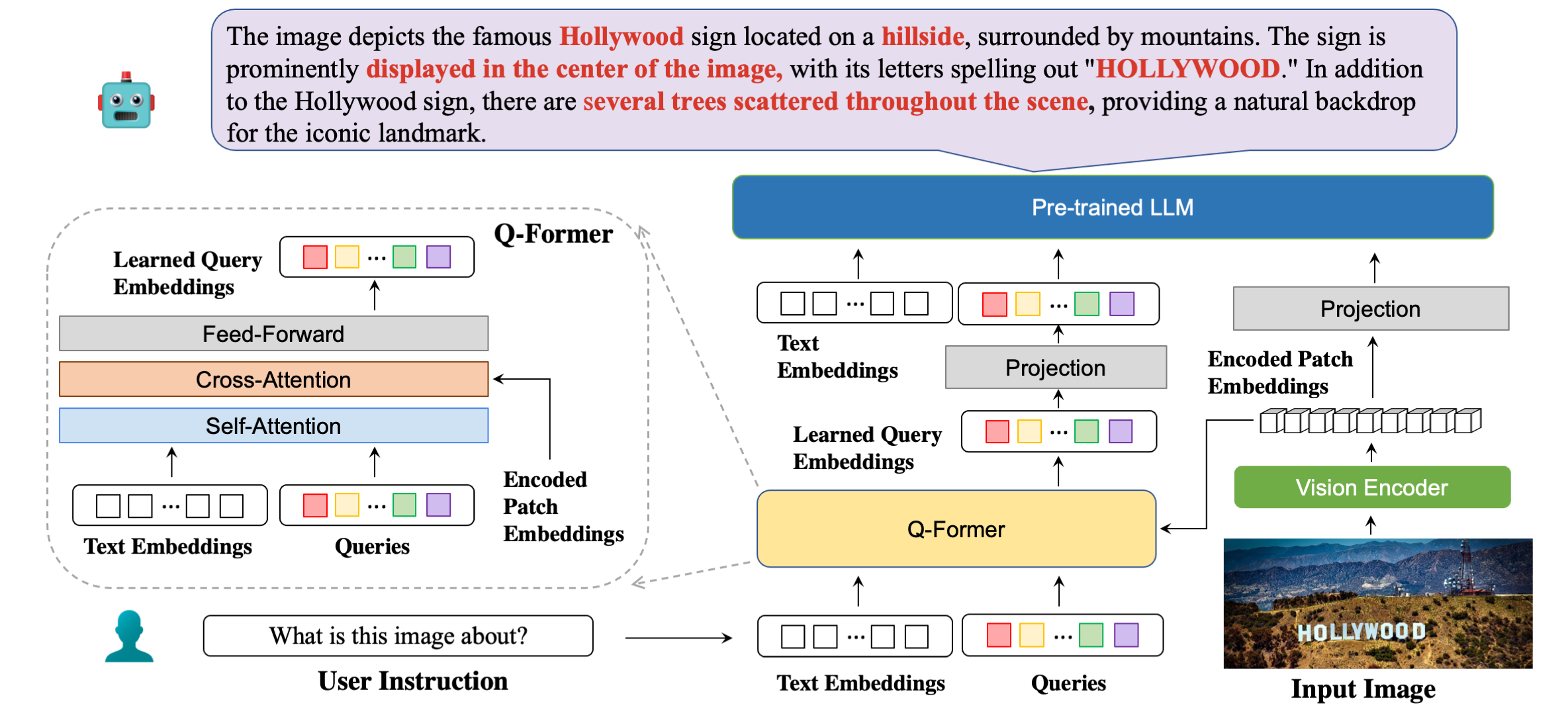
Nossa arquitetura de modelo em detalhes com exemplos de respostas.
| Método | STVQA | OCRVQA | TextoVQA | DocVQA | InformaçõesVQA | GráficoQA | ESTVQA | FUNSD | SROIE | POIE | Média |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenFlamingo | 19h32 | 27,82 | 29.08 | 5.05 | 14,99 | 9.12 | 28h20 | 0,85 | 0,12 | 2.12 | 13,67 |
| BLIP2-OPT | 13h36 | 10.58 | 21.18 | 0,82 | 8,82 | 7,44 | 27.02 | 0,00 | 0,00 | 0,02 | 8,92 |
| BLIP2-FLanT5XXL | 21h38 | 30.28 | 30,62 | 4h00 | 10.17 | 7h20 | 42,46 | 1.19 | 0,20 | 2,52 | 15h00 |
| MiniGPT4 | 14.02 | 11.52 | 18,72 | 2,97 | 13h32 | 4.32 | 28.36 | 1.19 | 0,04 | 1.31 | 9,58 |
| LLaVA | 22,93 | 15.02 | 28h30 | 4h40 | 13,78 | 7,28 | 33,48 | 1.02 | 0,12 | 2.09 | 12,84 |
| mPLUG-Coruja | 26.32 | 35h00 | 37,44 | 6.17 | 16h46 | 9,52 | 49,68 | 1.02 | 0,64 | 3.26 | 18h56 |
| InstruirBLIP (FLANT5XXL) | 26.22 | 55.04 | 36,86 | 4,94 | 10.14 | 8.16 | 43,84 | 1,36 | 0,50 | 1,91 | 18h90 |
| InstruirBLIP (Vicuna-7B) | 28,64 | 47,62 | 39,60 | 5,89 | 13h10 | 5.52 | 47,66 | 0,85 | 0,64 | 2,66 | 19.22 |
| BLIVA (FLANT5XXL) | 28.24 | 61,34 | 39,36 | 5.22 | 10,82 | 9.28 | 45,66 | 1,53 | 0,50 | 2,39 | 20h43 |
| BLIVA (Vicuna-7B) | 29.08 | 65,38 | 42,18 | 6.24 | 13h50 | 8.16 | 48.14 | 1.02 | 0,88 | 2,91 | 21h75 |
| Método | VSR | Ícone QA | TextoVQA | Visdial | Flickr30K | HM | VizWiz | MSRVTT |
|---|---|---|---|---|---|---|---|---|
| Flamingo-3B | - | - | 30.1 | - | 60,6 | - | - | - |
| Flamingo-9B | - | - | 31,8 | - | 61,5 | - | - | - |
| Flamingo-80B | - | - | 35,0 | - | 67,2 | - | - | - |
| MiniGPT-4 | 50,65 | - | 18h56 | - | - | 29,0 | 34,78 | - |
| LLaVA | 56,3 | - | 37,98 | - | - | 9.2 | 36,74 | - |
| BLIP-2 (Vicuna-7B) | 50,0 | 39,7 | 40,1 | 44,9 | 74,9 | 50,2 | 49,34 | 4.17 |
| InstruirBLIP (Vicuna-7B) | 54,3 | 43,1 | 50,1 | 45,2 | 82,4 | 54,8 | 43,3 | 18,7 |
| BLIVA (Vicuna-7B) | 62,2 | 44,88 | 57,96 | 45,63 | 87,1 | 55,6 | 42,9 | 23,81 |
conda create -n bliva python=3.9
conda activate blivagit clone https://github.com/mlpc-ucsd/BLIVA
cd BLIVA
pip install -e . BLIVA Vicunha 7B
Nosso modelo da versão Vicuna é lançado aqui. Baixe o peso do nosso modelo e especifique o caminho na configuração do modelo aqui na linha 8.
O LLM que usamos é a versão v0.1 do Vicuna-7B. Para preparar o peso da Vicuna, consulte nossas instruções aqui. Em seguida, defina o caminho para o peso da vicunha no arquivo de configuração do modelo aqui na Linha 21.
BLIVA FlanT5 XXL (disponível para uso comercial)
O modelo da versão FlanT5 é lançado aqui. Baixe o peso do nosso modelo e especifique o caminho na configuração do modelo aqui na linha 8.
O peso LLM para Flant5 começará a ser baixado automaticamente do huggingface ao executar nosso código de inferência.
Para responder a uma pergunta da imagem, execute o código de avaliação a seguir. Por exemplo,
python evaluate.py --answer_qs
--model_name bliva_vicuna
--img_path images/example.jpg
--question " what is this image about? "Também apoiamos a resposta a perguntas de múltipla escolha, que é a mesma que usamos para tarefas de avaliação em papel. Para fornecer uma lista de chioce, deve ser uma string dividida por vírgula. Por exemplo,
python evaluate.py --answer_mc
--model_name bliva_vicuna
--img_path images/mi6.png
--question " Which genre does this image belong to? "
--candidates " play, tv show, movie " Nossa demonstração está disponível publicamente aqui. Para executar nossa demonstração localmente em sua máquina. Correr:
python demo.pyDepois de baixar os conjuntos de dados de treinamento e especificar seu caminho nas configurações do conjunto de dados, estamos prontos para o treinamento. Utilizamos 8x A6000 Ada em nossos experimentos. Ajuste os hiperparâmetros de acordo com os recursos da sua GPU. Os transformadores podem levar cerca de 2 minutos para carregar o modelo, dê algum tempo para o modelo iniciar o treinamento. Aqui damos um exemplo de treinamento da versão BLIVA Vicuna, a versão Flant5 segue o mesmo formato.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/pretrain_bliva_vicuna.yamltorchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_vicuna.yamlOu também apoiamos o treinamento de Vicuna7b junto com BLIVA usando LoRA durante a segunda etapa, por padrão não usamos esta versão.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_and_vicuna.yamlSe você achar o BLIVA útil para suas pesquisas e aplicações, cite usando este BibTeX:
@misc { hu2023bliva ,
title = { BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions } ,
author = { Wenbo Hu and Yifan Xu and Yi Li and Weiyue Li and Zeyuan Chen and Zhuowen Tu } ,
publisher = { arXiv:2308.09936 } ,
year = { 2023 } ,
}O código deste repositório está sob licença BSD de 3 cláusulas. Muitos códigos são baseados em Lavis com licença BSD de 3 cláusulas aqui.
Para nossos parâmetros de modelo da versão BLIVA Vicuna, eles devem ser usados sob a licença de modelo da LLaMA. Para o peso do modelo BLIVA FlanT5, está sob a licença Apache 2.0. Para nossos dados YTTB-VQA, estão sob CC BY NC 4.0


