cambrian
1.0.0
Curiosidade: a visão surgiu nos animais durante o período Cambriano! Essa foi a inspiração para o nome do nosso projeto, Cambriano.
eval/ para mais detalhes.dataengine/ para obter mais detalhes.Atualmente, oferecemos suporte ao treinamento em TPU usando TorchXLA
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " Aqui estão nossos pontos de verificação cambrianos, juntamente com instruções sobre como usar os pesos. Nossos modelos se destacam em diversas dimensões, nos níveis de parâmetro 8B, 13B e 34B. Eles demonstram desempenho competitivo em comparação com modelos proprietários de código fechado, como GPT-4V, Gemini-Pro e Grok-1.4V em vários benchmarks.
| Modelo | #Vis. Tok. | MMB | SQA-I | MathVistaM | GráficoQA | MMVP |
|---|---|---|---|---|---|---|
| GPT-4V | DESCONHECIDO | 75,8 | - | 49,9 | 78,5 | 50,0 |
| Gêmeos-1.0 Pró | DESCONHECIDO | 73,6 | - | 45,2 | - | - |
| Gêmeos-1.5 Pró | DESCONHECIDO | - | - | 52.1 | 81,3 | - |
| Grok-1.5 | DESCONHECIDO | - | - | 52,8 | 76,1 | - |
| MM-1-8B | 144 | 72,3 | 72,6 | 35,9 | - | - |
| MM-1-30B | 144 | 75,1 | 81,0 | 39,4 | - | - |
| Base LLM: Phi-3-3.8B | ||||||
| Cambriano-1-8B | 576 | 74,6 | 79,2 | 48,4 | 66,8 | 40,0 |
| LLM básico: LLaMA3-8B-Instruir | ||||||
| Mini-Gêmeos-HD-8B | 2880 | 72,7 | 75,1 | 37,0 | 59,1 | 18,7 |
| LLaVA-NeXT-8B | 2880 | 72,1 | 72,8 | 36,3 | 69,5 | 38,7 |
| Cambriano-1-8B | 576 | 75,9 | 80,4 | 49,0 | 73,3 | 51.3 |
| Base LLM: Vicuna1.5-13B | ||||||
| Mini-Gêmeos-HD-13B | 2880 | 68,6 | 71,9 | 37,0 | 56,6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70,0 | 73,5 | 35.1 | 62,2 | 36,0 |
| Cambriano-1-13B | 576 | 75,7 | 79,3 | 48,0 | 73,8 | 41,3 |
| Base LLM: Hermes2-Yi-34B | ||||||
| Mini-Gêmeos-HD-34B | 2880 | 80,6 | 77,7 | 43,4 | 67,6 | 37,3 |
| LLaVA-NeXT-34B | 2880 | 79,3 | 81,8 | 46,5 | 68,7 | 47,3 |
| Cambriano-1-34B | 576 | 81,4 | 85,6 | 53,2 | 75,6 | 52,7 |
Para a tabela completa, consulte nosso artigo Cambrian-1.
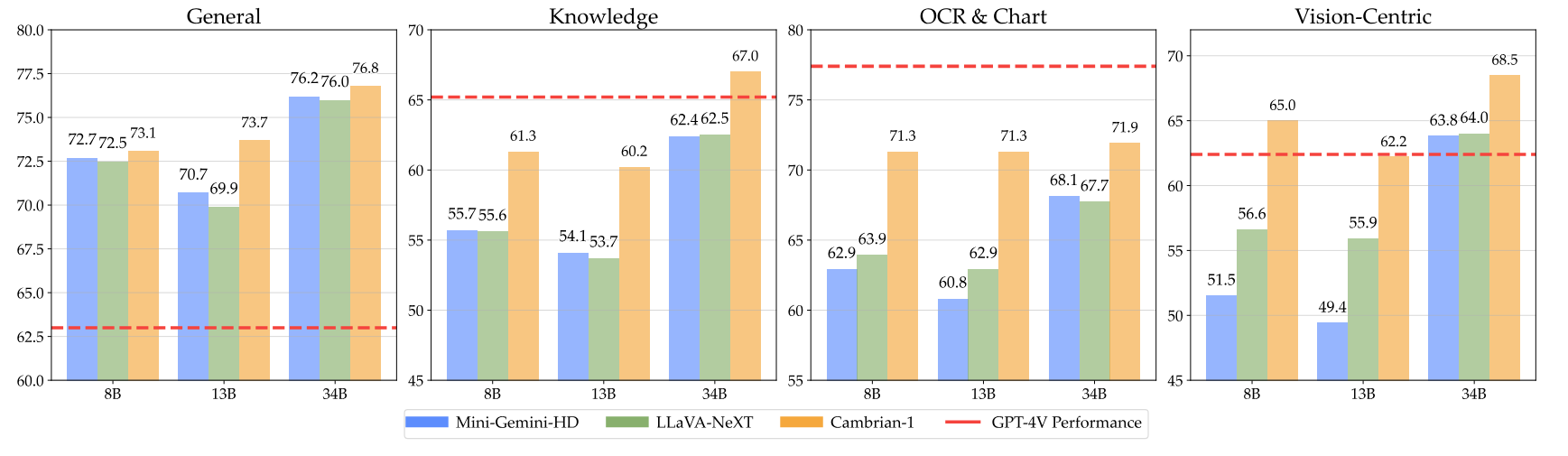
Nossos modelos oferecem desempenho altamente competitivo ao usar um número fixo menor de tokens visuais.
Para usar os pesos do modelo, baixe-os em Hugging Face:
Fornecemos um exemplo de script de carregamento e geração de modelo em inference.py .

Neste trabalho, coletamos um conjunto muito grande de dados de ajuste de instruções, Cambrian-10M, para nós e trabalhos futuros para estudar dados no treinamento de MLLMs. Em nosso estudo preliminar, filtramos os dados para um conjunto de 7 milhões de pontos de dados selecionados de alta qualidade, que chamamos de Cambrian-7M. Ambos os conjuntos de dados estão disponíveis no seguinte conjunto de dados Hugging Face: Cambrian-10M.
Coletamos uma ampla gama de dados de ajuste de instrução visual de várias fontes, incluindo VQA, conversação visual e interação visual incorporada. Para garantir dados de conhecimento de alta qualidade, confiáveis e em grande escala, projetamos um Internet Data Engine.
Além disso, observamos que os dados VQA tendem a gerar resultados muito curtos, criando uma mudança na distribuição dos dados de treinamento. Para resolver esse problema, aproveitamos o GPT-4v e o GPT-4o para criar respostas estendidas e dados mais criativos.
Para resolver a inadequação dos dados relacionados à ciência, projetamos um Internet Data Engine para coletar dados VQA confiáveis relacionados à ciência. Este mecanismo pode ser aplicado para coletar dados sobre qualquer tema. Usando este mecanismo, coletamos 161 mil pontos de dados adicionais de ajuste de instruções visuais relacionados à ciência, aumentando o total de dados neste domínio em 400%! Se você quiser usar esta parte dos dados, use este jsonl.
Usamos GPT-4v para criar 77 mil pontos de dados adicionais. Esses dados usam GPT-4v para reescrever o VQA somente de resposta original em respostas mais longas com respostas mais detalhadas ou geram dados de ajuste de instrução visual com base na imagem fornecida. Se você quiser usar esta parte dos dados, use este jsonl.
Usamos GPT-4o para criar 60 mil pontos de dados criativos adicionais. Esses dados incentivam o modelo a gerar respostas muito longas e geralmente contêm perguntas altamente criativas, como escrever um poema, compor uma música e muito mais. Se você quiser usar esta parte dos dados, use este jsonl.
Conduzimos um estudo inicial sobre curadoria de dados por:
Empiricamente, descobrimos que esse cenário
| Categoria | Proporção de dados |
|---|---|
| Linguagem | 21,00% |
| Em geral | 34,52% |
| OCR | 27,22% |
| Contando | 8,71% |
| Matemática | 7,20% |
| Código | 0,87% |
| Ciência | 0,88% |
Em comparação com o modelo LLaVA-665K anterior, a ampliação e a melhoria da curadoria de dados melhoram significativamente o desempenho do modelo, conforme mostrado na tabela abaixo:
| Modelo | Média | Conhecimento Geral | OCR | Gráfico | Centrado na Visão |
|---|---|---|---|---|---|
| LLaVA-665K | 40,4 | 64,7 | 45,2 | 20,8 | 31,0 |
| Cambriano-10M | 53,8 | 68,7 | 51,6 | 47,1 | 47,6 |
| Cambriano-7M | 54,8 | 69,6 | 52,6 | 47,3 | 49,5 |
Embora o treinamento com Cambrian-7M forneça resultados de benchmark competitivos, observamos que o modelo tende a produzir respostas mais curtas e a agir como uma máquina de perguntas e respostas. Esse comportamento, que chamamos de fenômeno da “Secretária Eletrônica”, pode limitar a utilidade do modelo em interações mais complexas.
Descobrimos que adicionar um prompt do sistema como “Responda à pergunta usando uma única palavra ou frase”. pode ajudar a mitigar o problema. Esta abordagem incentiva o modelo a fornecer respostas tão concisas apenas quando for contextualmente apropriado. Para mais detalhes, consulte nosso artigo.
Também selecionamos um conjunto de dados, Cambrian-7M com prompt do sistema, que inclui o prompt do sistema para aprimorar a criatividade e a capacidade de bate-papo do modelo.
Abaixo está a configuração de treinamento mais recente para Cambrian-1.
No artigo Cambrian-1, conduzimos estudos extensos para demonstrar a necessidade de treinamento em dois estágios. O treinamento Cambrian-1 consiste em duas etapas:
Cambrian-1 é treinado em TPU-V4-512, mas também pode ser treinado em TPUs a partir de TPU-V4-64. O código de treinamento da GPU será lançado em breve. Para treinamento de GPU em menos GPUs, reduza per_device_train_batch_size e aumente gradient_accumulation_steps adequadamente, garantindo que o tamanho global do lote permaneça o mesmo: per_device_train_batch_size x gradient_accumulation_steps x num_gpus .
Ambos os hiperparâmetros usados no pré-treinamento e no ajuste fino são fornecidos abaixo.
| Base LLM | Tamanho global do lote | Taxa de aprendizagem | Taxa de aprendizagem SVA | Épocas | Comprimento máximo |
|---|---|---|---|---|---|
| LLaMA-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Vicunha-1.5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048 |
| Base LLM | Tamanho global do lote | Taxa de aprendizagem | Épocas | Comprimento máximo |
|---|---|---|---|---|
| LLaMA-3 8B | 512 | 4e-5 | 1 | 2048 |
| Vicunha-1.5 13B | 512 | 4e-5 | 1 | 2048 |
| Hermes Yi-34B | 1024 | 2e-5 | 1 | 2048 |
Para o ajuste fino das instruções, conduzimos experimentos para determinar a taxa de aprendizado ideal para o treinamento do nosso modelo. Com base em nossas descobertas, recomendamos usar a seguinte fórmula para ajustar sua taxa de aprendizado com base na disponibilidade do seu dispositivo:
optimal lr = base_lr * sqrt(bs / base_bs)
Para obter o LLM básico e treinar os modelos 8B, 13B e 34B:
Usamos uma combinação de dados de alinhamento LLaVA, ShareGPT4V, Mini-Gemini e ALLaVA para pré-treinar nosso conector visual (SVA). No Cambrian-1, conduzimos estudos extensos para demonstrar a necessidade e os benefícios do uso de dados adicionais de alinhamento.
Para começar, visite nossa página de dados de alinhamento do Hugging Face para obter mais detalhes. Você pode baixar os dados de alinhamento nos seguintes links:
Fornecemos exemplos de scripts de treinamento em:
Se você deseja treinar com outras fontes de dados ou dados personalizados, oferecemos suporte ao formato de dados LLaVA comumente usado. Para lidar com arquivos muito grandes, usamos o formato JSONL em vez do formato JSON para carregamento lento de dados para otimizar o uso de memória.
Semelhante ao Training SVA, visite nossos dados Cambrian-10M para obter mais detalhes sobre os dados de ajuste de instrução.
Fornecemos exemplos de scripts de treinamento em:
--mm_projector_type : Para usar nosso módulo SVA, defina este valor como sva . Para usar o projetor MLP de 2 camadas estilo LLaVA, defina esse valor como mlp2x_gelu .--vision_tower_aux_list : A lista de modelos de visão a serem usados (por exemplo '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : A lista do número de tokens de visão para cada torre de visão; cada número deve ser um número quadrado (por exemplo '[576, 576, 576, 9216]' ). O mapa de características de cada torre de visão será interpolado para atender a este requisito.--image_token_len : O número final de tokens de visão que serão fornecidos ao LLM; o número deve ser um número quadrado (por exemplo, 576 ). Observe que se mm_projector_type for mlp, cada número em vision_tower_aux_token_len_list deve ser igual a image_token_len . Os argumentos abaixo são significativos apenas para projetores SVA--num_query_group : O valor G para o módulo SVA.--query_num_list : Uma lista de números de consulta para cada grupo de consulta em SVA (por exemplo, '[576]' ). O comprimento da lista deve ser igual a num_query_group .--connector_depth : O valor D para o módulo SVA.--vision_hidden_size : O tamanho oculto do módulo SVA.--connector_only : Se verdadeiro, o módulo SVA só aparecerá antes do LLM, caso contrário será inserido múltiplas vezes dentro do LLM. Os três argumentos a seguir só são significativos quando definido como False .--num_of_vision_sampler_layers : O número total de módulos SVA inseridos dentro do LLM.--start_of_vision_sampler_layers : O índice da camada LLM após o qual começa a inserção do SVA.--stride_of_vision_sampler_layers : O passo da inserção do módulo SVA dentro do LLM. Lançamos nosso código de avaliação na subpasta eval/ . Por favor, consulte o README para obter mais detalhes.
As instruções a seguir irão guiá-lo no lançamento de uma demonstração local do Gradio com Cambrian. Fornecemos uma interface web simples para você interagir com o modelo. Você também pode usar a CLI para inferência. Esta configuração é fortemente inspirada no LLaVA.
Siga as etapas abaixo para lançar uma demonstração local do Gradio. Um diagrama do código de veiculação local está abaixo de 1 .
%%{init: {"tema": "base"}}%%
fluxograma BT
%% Declarar nós
estilo gws fill:#f9f,stroke:#333,stroke-width:2px
estilo c preenchimento:#bbf,traço:#333,largura do traço:2px
estilo mw8b preenchimento:#aff,traço:#333,largura do traço:2px
estilo mw13b preenchimento:#aff,traço:#333,largura do traço:2px
%% estilo sglw13b preenchimento:#ffa,traço:#333,largura do traçado:2px
%% estilo lsglw13b preenchimento:#ffa,traço:#333,largura do traçado:2px
gws["Gradio (servidor UI)"]
c["Controlador (servidor API):<br/>PORTA: 10000"]
mw8b["Trabalhador modelo:<br/><b>Cambrian-1-8B</b><br/>PORTA: 40000"]
mw13b["Trabalhador modelo:<br/><b>Cambrian-1-13B</b><br/>PORTA: 40001"]
%% sglw13b["Backend SGLang:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["Trabalhador SGLang:<br/><b>Cambrian-1-34B<b><br/>PORTA: 40002"]
subparágrafo "Arquitetura de demonstração"
direção BT
c <--> gws
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
fim
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadVocê acabou de lançar a interface web do Gradio. Agora você pode abrir a interface web com a URL impressa na tela. Você pode notar que não há nenhum modelo na lista de modelos. Não se preocupe, pois ainda não lançamos nenhum modelo de trabalhador. Ele será atualizado automaticamente quando você iniciar um modelo de trabalho.
Em breve.
Este é o trabalhador real que realiza a inferência na GPU. Cada trabalhador é responsável por um único modelo especificado em --model-path .
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bEspere até que o processo termine de carregar o modelo e você veja "Uvicorn rodando em ...". Agora, atualize sua interface web do Gradio e você verá o modelo que acabou de lançar na lista de modelos.
Você pode iniciar quantos trabalhadores desejar e comparar diferentes pontos de verificação de modelo na mesma interface Gradio. Por favor, mantenha o --controller igual e modifique --port e --worker para um número de porta diferente para cada trabalhador.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> Se você estiver usando um dispositivo Apple com chip M1 ou M2, poderá especificar o dispositivo mps usando o sinalizador --device : --device mps .
Se a VRAM da sua GPU for inferior a 24 GB (por exemplo, RTX 3090, RTX 4090, etc.), você pode tentar executá-la com várias GPUs. Nossa base de código mais recente tentará usar automaticamente várias GPUs se você tiver mais de uma GPU. Você pode especificar quais GPUs usar com CUDA_VISIBLE_DEVICES . Abaixo está um exemplo de execução com as duas primeiras GPUs.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bPENDÊNCIA
Se você achar o Cambriano útil para suas pesquisas e aplicações, cite o uso deste BibTeX:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
Avisos de uso e licença : Este projeto utiliza determinados conjuntos de dados e pontos de verificação que estão sujeitos às suas respectivas licenças originais. Os usuários devem cumprir todos os termos e condições dessas licenças originais, incluindo, entre outros, os Termos de Uso da OpenAI para o conjunto de dados e as licenças específicas para modelos de linguagem base para pontos de verificação treinados usando o conjunto de dados (por exemplo, licença comunitária Llama para LLaMA-3, e Vicunha-1,5). Este projecto não impõe quaisquer restrições adicionais além das estipuladas nas licenças originais. Além disso, os usuários são lembrados de garantir que o uso do conjunto de dados e dos pontos de verificação esteja em conformidade com todas as leis e regulamentos aplicáveis.
Copiado do diagrama do LLaVA. ↩


