Synonyms
Synonyms
Sinônimos chineses para processamento e compreensão de linguagem natural.
Melhores sinônimos em chinês: chatbot, kit de ferramentas inteligente de perguntas e respostas.
synonyms podem ser usados para muitas tarefas de compreensão de linguagem natural: alinhamento de texto, algoritmos de recomendação, cálculos de similaridade, deslocamento semântico, extração de palavras-chave, extração de conceitos, resumo automático, mecanismos de busca, etc.
Para fornecer serviços estáveis, confiáveis e otimizados de longo prazo, a Synonyms mudou para usar a licença Chunsong, v1.0 e cobranças para download de modelos de aprendizado de máquina, consulte o armazenamento de certificados para obter detalhes. Colaboradores anteriores (colaboradores de código com contribuições pendentes) podem entrar em contato conosco para discutir questões de cobrança. -- Chatopera Inc.
Siga as etapas abaixo para instalar e ativar pacotes.
pip install -U synonymsA versão estável atual é v3.x.
O (s) pacote (s) de modelo de aprendizado de máquina da Synonyms requer uma licença do Chatopera License Store, primeiro compre uma licença e obtenha o license id na página Licenças no Chatopera License Store ( license id : no armazenamento de certificados, na página de detalhes do certificado, clique em [Copiar Identidade do certificado] ).
Em segundo lugar, defina a variável de ambiente em seu terminal ou scripts de shell conforme abaixo.
por exemplo, Shell, scripts CMD em Linux, Windows, macOS.
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'Caderno Jupyter, etc.
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )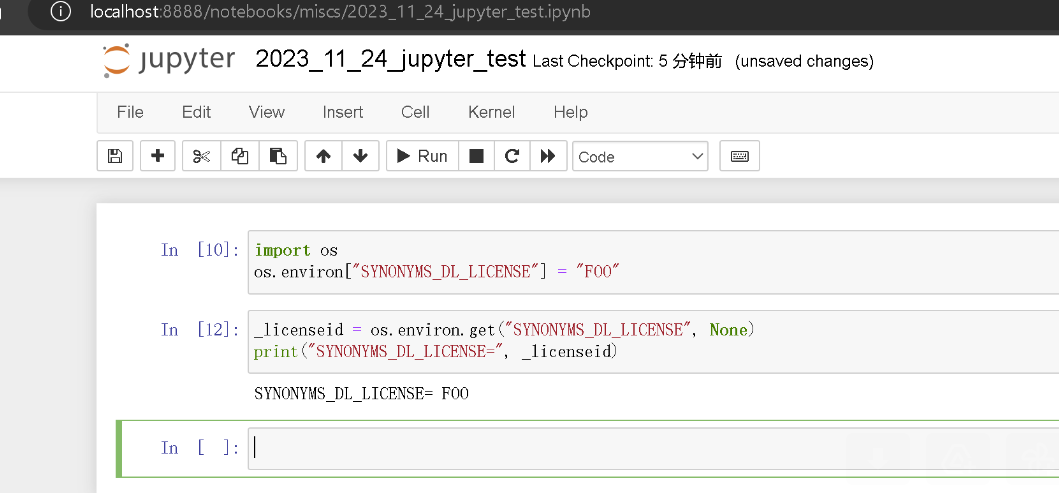
Dica: O arquivo vetorial de palavras será baixado pela primeira vez após a instalação e a velocidade de download depende das condições da rede.
Por último, baixe o pacote do modelo por comando ou script -
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
Suporta o uso de variáveis de ambiente para configurar vocabulário de segmentação de palavras e arquivos vetoriais de palavras word2vec.
| variáveis de ambiente | descrever |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | Arquivo vetorial do Word treinado usando word2vec, formato binário. |
| SYNONYMS_WORDSEG_DICT | Dicionário mestre de segmentação de palavras chinesas, formato e referência de uso |
| SYNONYMS_DEBUG | ["TRUE"|"FALSE"], seja para gerar logs de depuração, definido como saída "TRUE", o padrão é "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) retorna uma tupla A tupla contém dois itens: ([nearby_words], [nearby_words_score]) nearby_words distância Os comprimentos são organizados de perto para longe, nearby_words_score é a pontuação da distância entre as palavras na posição correspondente em nearby_words . A pontuação está no intervalo (0-1). Quanto mais próximo estiver de 1, mais próximo estará SIZE do número de palavras retornadas. o padrão é 10. por exemplo:
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) No caso de OOV, ([], []) é retornado, tamanho atual do dicionário: 435.729.
Comparação de semelhança entre duas frases
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )Dentre eles, o parâmetro seg indica se sinônimos.compare realiza segmentação de palavras em sen1 e sen2, e o padrão é True. Valor de retorno: [0-1], e quanto mais próximo estiver de 1, mais semelhantes serão as duas sentenças.
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 Imprima sinônimos de maneira amigável para facilitar a depuração display(WORD [, SIZE]) chama synonyms#nearby .
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE é o número de listas de vocabulário impressas, o padrão é 10.
Imprima as informações de descrição do pacote atual:
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
Obtenha um vetor de palavras, que é uma matriz numpy. Quando a palavra é uma palavra não registrada, uma exceção KeyError é lançada.
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )Obtenha um vetor da frase após a segmentação da palavra. O vetor é composto no modo BoW.
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量Segmentação de palavras chinesas
synonyms . seg ( "中文近义词工具包" )O resultado da segmentação de palavras é uma tupla que consiste em duas listas, que são palavras e classes gramaticais correspondentes.
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])Este particípio não remove palavras irrelevantes e pontuação.
Extrair palavras-chave Por padrão, as palavras-chave são extraídas de acordo com a importância.
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
Obtenha mais logs para depuração, defina a variável de ambiente.
SYNONYMS_DEBUG=TRUE
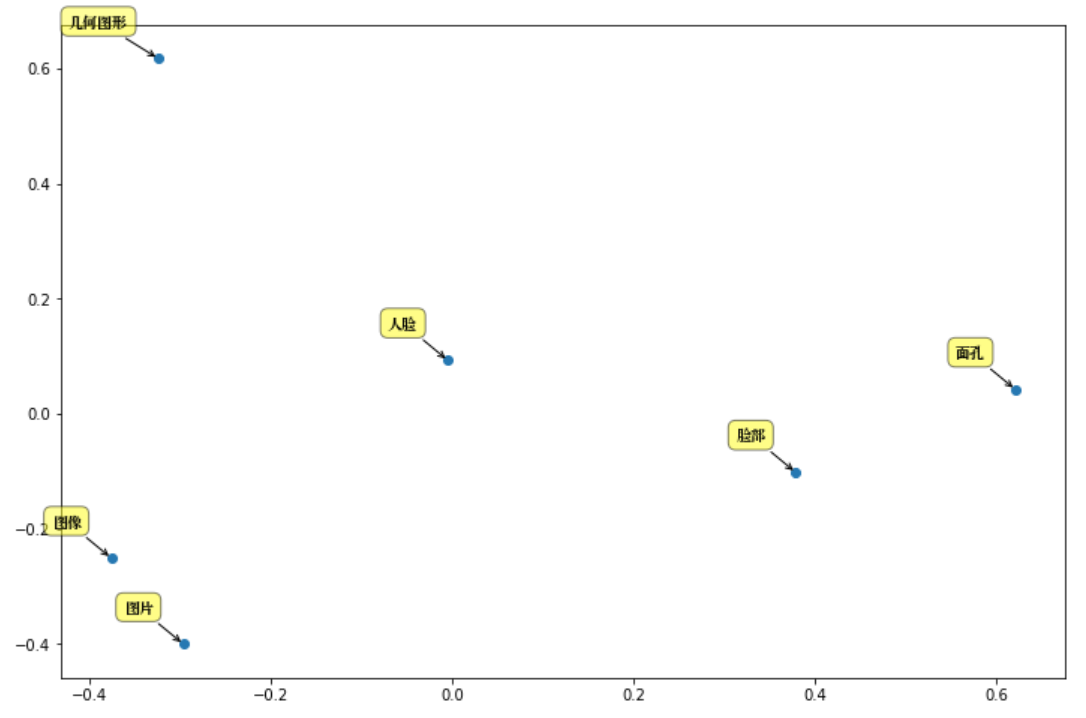
Tomando o “rosto humano” como exemplo para analisar os principais componentes:
$ pip install -r Requirements.txt
$ python demo.pyDeclaração de status atualizada.
O que os usuários dizem:
os dados são construídos com base no wikidata-corpus.
"Sinônimos Cilin" foi compilado por Mei Jiaju e outros em 1983. A versão mais amplamente usada agora é "Sinônimos Cilin Expanded Edition", mantida pelo Centro de Pesquisa de Computação Social e Recuperação de Informação do Instituto de Tecnologia de Harbin. Ela divide detalhadamente o vocabulário chinês em grandes. Categorias e subcategorias classificam a relação entre palavras. A versão expandida de Sinônimos Cilin contém mais de 70.000 palavras, das quais mais de 30.000 são compartilhadas na forma de dados abertos.
HowNet, também conhecido como HowNet, não é apenas um dicionário semântico, mas um sistema de conhecimento. A relação entre palavras é um de seus cenários básicos de uso. CNKI contém mais de 8 palavras.
O padrão internacional de avaliação para algoritmos de similaridade de palavras geralmente adota o valor de julgamento manual do conjunto de pares de palavras em inglês publicado pela Miller&Charles. O conjunto de pares de palavras consiste em dez pares de palavras em inglês altamente relacionadas, dez pares de moderadamente relacionadas e dez pares de pares de palavras em inglês pouco relacionadas e, em seguida, 38 sujeitos são solicitados a julgar a relevância semântica desses 30 pares e, finalmente, calcular sua média. o valor serve como critério manual. Em seguida, diferentes ferramentas de sinônimos também pontuam a similaridade dessas palavras e as comparam com critérios de julgamento manual, como o uso do coeficiente de correlação de Pearson. No campo chinês, também é um método comum usar a versão traduzida desta lista de vocabulário para comparar sinônimos chineses.
A capacidade da lista de vocabulário de Sinônimos é 435.729 Abaixo selecionamos algumas palavras que existem em Sinônimos Cilin, CNKI e Sinônimos para comparar sua semelhança:
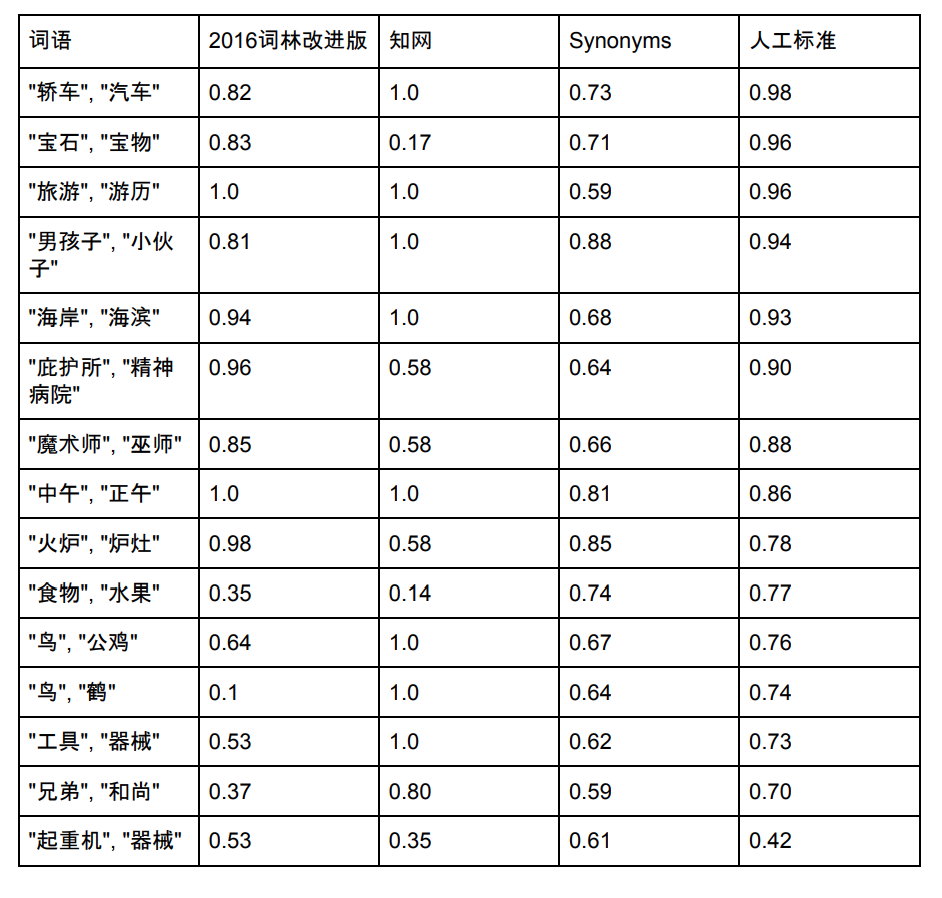
Nota: Fontes de dados e pontuações da Synonym Forest e CNKI. Os sinônimos também estão sendo constantemente otimizados e as novas pontuações podem ser inconsistentes com a imagem acima.
Mais resultados de comparação.
Lista de usuários associados ao Github
Teste com py3, MacBook Pro.
python benchmark.py
++++++++++ Nome e versão do sistema operacional ++++++++++
Plataforma: Darwin
Núcleo: 16.7.0
Arquitetura: ('64 bits', '')
++++++++++ Núcleos de CPU ++++++++++
Núcleos: 4
Carga da CPU: 60
++++++++++ Memória do sistema ++++++++++
meminfo 8GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
Coração da máquina
Registro de compartilhamento on-line: Kit de ferramentas de sinônimos em chinês para sinônimos @ 07/02/2018
Sinônimos publica certificado MIT. Dados e procedimentos podem ser utilizados em pesquisas e produtos comerciais e devem ser citados e abordados, como em qualquer mídia, periódico, revista ou blog publicado.
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
wikidata-corpus
derivação do princípio word2vec e análise de código
Não suportado, consulte o nº 5 para obter mais informações
Word2vec lançada pelo Google, esta biblioteca é escrita em linguagem C, possui alta eficiência de uso de memória e rápida velocidade de treinamento. gensim pode carregar arquivos de modelo produzidos por word2vec.
Consulte o nº 64 para obter detalhes
Hai Liang Wang
Hu Yingxi
Este livro foi escrito em coautoria pelos autores da Synonyms.
Link para compra rápida de livro 
"Resposta inteligente a perguntas e aprendizado profundo" Este livro é para estudantes e engenheiros de software que estão se preparando para começar com aprendizado de máquina e processamento de linguagem natural. Ele apresenta muitos princípios e algoritmos em teoria e também fornece muitos programas de exemplo para aumentar a praticidade. estão resumidos na biblioteca de códigos de programa de exemplo. Esses programas servem principalmente para ajudar todos a compreender os princípios e algoritmos. Você pode baixá-los e executá-los. O endereço da base de código é:
https://github.com/l11x0m7/book-of-qna-code
Word2vec do Google
Wikimedia: Fonte do corpus de treinamento
gensim: word2vec.py
SentenceSim: corpus de avaliação de similaridade
jieba: segmentação de palavras chinesas
Licença Pública Chunsong, versão 1.0
https://bot.chatopera.com/
O serviço de nuvem Chatopera é um serviço de nuvem completo para implementação de robôs de bate-papo e é cobrado com base no número de chamadas de interface. Chatopera Cloud Service é uma instância de software como serviço da plataforma de bot Chatopera. Baseado na computação em nuvem, o serviço em nuvem Chatopera é um serviço em nuvem chatbot como serviço .
A plataforma de robô Chatopera inclui componentes como base de conhecimento, diálogo multi-rodada, reconhecimento de intenção e reconhecimento de fala, desenvolvimento de robô de bate-papo padronizado e oferece suporte a cenários como perguntas e respostas inteligentes de OA empresarial, perguntas e respostas inteligentes de RH, atendimento inteligente ao cliente e marketing online. Os departamentos de TI corporativos e de negócios usam os serviços em nuvem do Chatopera para colocar chatbots online rapidamente!


