chat4u
1.0.0
Use os registros de bate-papo do WeChat para treinar um chatbot exclusivo para você.
Os registros de bate-papo do WeChat serão criptografados e armazenados no banco de dados sqlite. Primeiro, você precisa obter a chave do banco de dados. Você precisa de um laptop macOS e seu celular pode ser Android/iPhone.
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log . sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
Os usuários de outros sistemas operacionais podem tentar os seguintes métodos, que foram apenas pesquisados e não verificados, para referência:
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db : https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker No meu laptop macOS, os registros de bate-papo do WeChat são armazenados em msg_0.db - msg_9.db e somente esses bancos de dados podem ser descriptografados.
Você precisa instalar o sqlcipher para que os usuários do sistema macOS possam executar diretamente:
brew install sqlcipher Execute o script a seguir para analisar automaticamente dbtrace.log , descriptografar msg_x.db e exportar para plain_msg_x.db .
python3 decrypt.py Você pode abrir o banco de dados descriptografado plain_msg_x.db por meio de https://sqliteviewer.app/, encontrar a tabela onde os registros de bate-papo necessários estão localizados, preencher o banco de dados e os nomes da tabela em prepare_data.py e executar o seguinte script para gerar dados de treinamento train.json , a estratégia atual é relativamente simples, ela lida apenas com uma única rodada de diálogo e mesclará diálogos consecutivos em 5 minutos.
python3 prepare_data.pyExemplos de dados de treinamento são os seguintes:
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] Prepare uma máquina Linux com GPU e scp train.json para a máquina GPU.
Usei LLaMA-7B de ajuste fino de imagem completa stanford_alpaca e treinei dados de 90k por 3 épocas em um V100-SXM2-32GB de 8 placas, o que levou apenas 1 hora.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3 salvará pesos em fatias e eles precisam ser mesclados em um arquivo de ponto de verificação pytorch:
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binEm placas gráficas de consumo, você pode experimentar o alpaca-lora. Somente o ajuste fino dos pesos do lora pode reduzir significativamente a memória gráfica e os custos de treinamento.
Você pode usar alpaca-lora para implantar o front end gradiente para depuração. Se estiver ajustando a imagem inteira, você precisará comentar o código relacionado ao peft e carregar apenas o modelo básico.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatEfeito da operação:

É necessário implantar um serviço modelo compatível com a API OpenAI. Aqui está uma adaptação simples baseada em llama4openai-api.py. Veja llama4openai-api.py neste warehouse para iniciar o serviço:
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyTeste se a interface está disponível:
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'Use wechat-chatgpt para acessar o WeChat e preencha seu endereço de serviço de modelo local para o endereço API:
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestEfeito da operação:
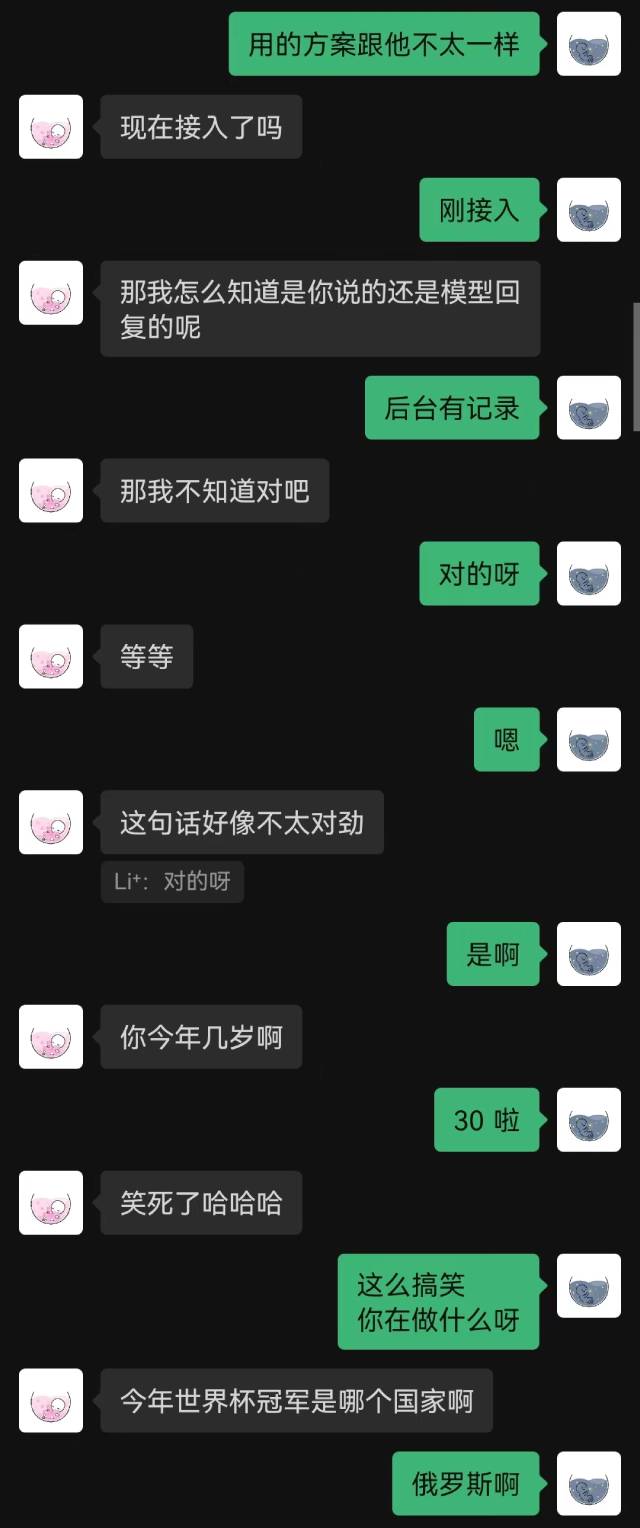 | 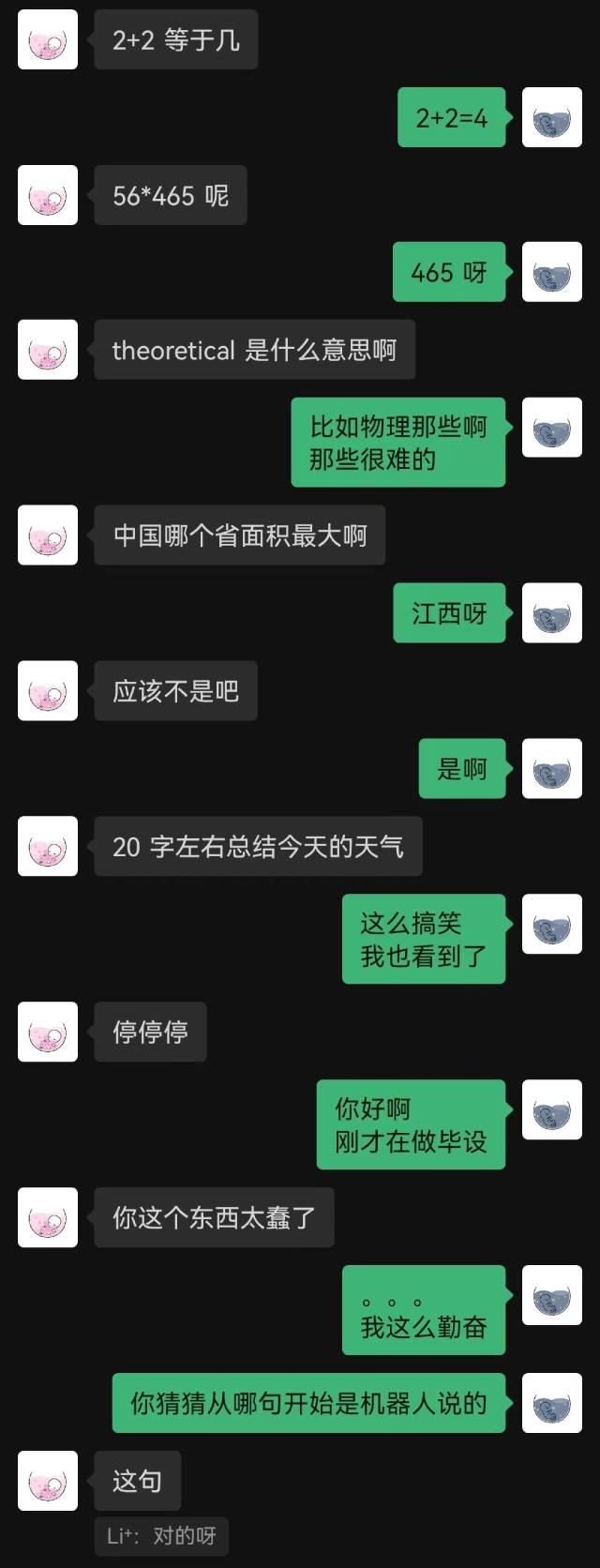 |
|---|
“Acabei de conectar” foi a primeira frase que o robô disse, e a outra parte não adivinhou até o final.
De modo geral, os robôs treinados com registros de bate-papo inevitavelmente cometerão alguns erros de bom senso, mas imitaram melhor o estilo do bate-papo.


