Facebook Messenger Bot
1.0.0
O chatbot do FB Messenger que treinei para falar como eu. A postagem do blog associada.
Para este projeto, eu queria treinar um modelo Sequence To Sequence em meus registros de conversas anteriores de vários sites de mídia social. Você pode ler mais sobre a motivação por trás dessa abordagem, os detalhes do modelo de ML e o propósito de cada script Python na postagem do blog, mas quero usar este README para explicar como você pode treinar seu próprio chatbot para falar como você .
Para executar esses scripts, você precisará das seguintes bibliotecas.
Baixe e descompacte todo este repositório do GitHub, de forma interativa ou digitando o seguinte em seu Terminal.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitNavegue até o diretório superior do repositório em sua máquina
cd Facebook-Messenger-BotNosso primeiro trabalho é baixar todos os dados de suas conversas de vários sites de mídia social. Para mim, usei Facebook, Google Hangouts e LinkedIn. Se você tiver outros sites dos quais está obtendo dados, tudo bem. Você apenas terá que criar um novo método em createDataset.py.
Dados do Facebook : Baixe seus dados aqui. Depois de baixado, você deverá ter um arquivo bastante grande chamado messages.htm . Será um arquivo bem grande (mais de 190 MB para mim). Precisaremos analisar esse arquivo grande e extrair todas as conversas. Para fazer isso, usaremos esta ferramenta que Dillon Dixon gentilmente abriu o código. Você irá em frente e instalará essa ferramenta executando
pip install fbchat-archive-parsere então executando:
fbcap ./messages.htm > fbMessages.txtIsso fornecerá todas as suas conversas do Facebook em um arquivo de texto bastante unificado. Obrigado Dillon! Vá em frente e armazene esse arquivo na pasta Facebook-Messenger-Bot.
Dados do LinkedIn : Baixe seus dados aqui. Depois de baixado, você deverá ver um arquivo inbox.csv . Não precisaremos realizar nenhuma outra etapa aqui, apenas queremos copiá-lo para nossa pasta.
Dados do Google Hangouts : Baixe seu formulário de dados aqui. Depois de baixado, você obterá um arquivo JSON que precisaremos analisar. Para fazer isso, usaremos este analisador encontrado nesta fenomenal postagem do blog. Queremos salvar os dados em arquivos de texto e depois copiar a pasta para a nossa.
No final de tudo isso, você deverá ter uma estrutura de diretórios parecida com esta. Certifique-se de renomear as pastas e os nomes dos arquivos se os seus forem diferentes.
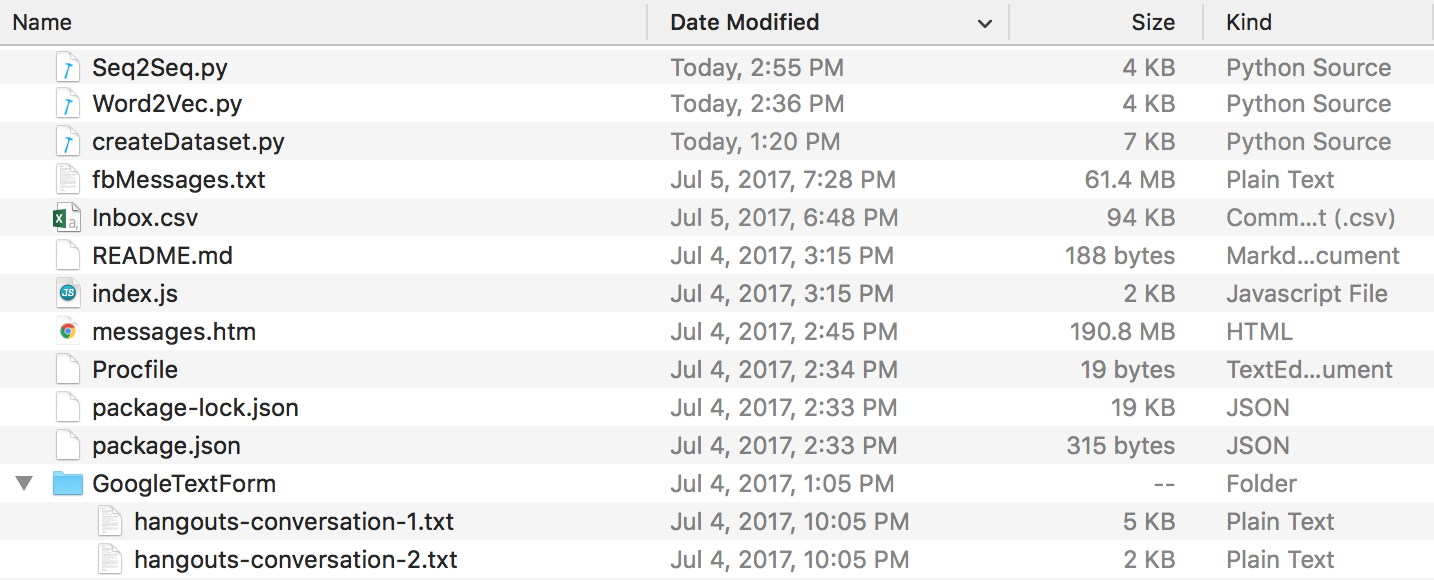
Dados do Discord : Você pode extrair seus chatlogs do Discord usando este incrível DiscordChatExporter feito por Tyrrrz. Siga a documentação para extrair os logs de bate-papo individuais desejados no formato .txt (isso é importante). Você pode então colocá-los todos em uma pasta chamada DiscordChatLogs no diretório repo.
Dados do WhatsApp : certifique-se de ter um telefone celular e coloque-o no formato de data dos EUA, se ainda não o tiver (isso será importante mais tarde, quando você analisar o arquivo de log para .csv). Você não pode usar o WhatsApp web para essa finalidade. Abra o bate-papo que deseja enviar, toque no botão de menu, toque em mais e clique em "Bate-papo por e-mail". Envie o e-mail para você mesmo e baixe-o para o seu computador. Isso lhe dará um arquivo .txt. Para analisá-lo, iremos convertê-lo para .csv. Para fazer isso acesse este link e insira todo o texto em seu arquivo de log. Clique em exportar, baixe o arquivo csv e simplesmente armazene-o na pasta Facebook-Messenger-Bot com o nome "whatsapp_chats.csv".
NOTA : O analisador fornecido no link acima parece ter sido removido. Se você ainda tiver um arquivo .csv no formato correto , ainda poderá usá-lo. Caso contrário, baixe os logs de bate-papo do WhatsApp como arquivos .txt e coloque-os todos em uma pasta chamada WhatsAppChatLogs no diretório repo. createDataset.py funcionará com esses arquivos se, e somente se, NÃO encontrar um arquivo .csv chamado whatsapp_chats.csv .
Caso você use logs de bate-papo .txt , observe que o formato esperado é-
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(OU)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
Agora que temos todos os nossos registros de conversas em um formato limpo, podemos prosseguir e criar nosso conjunto de dados. Em nosso diretório, vamos executar:
python createDataset.pyEm seguida, você será solicitado a inserir seu nome (para que o script saiba quem procurar) e de quais sites de mídia social você possui dados. Este script criará um arquivo chamado conversaDictionary.npy que é um objeto Numpy que contém pares na forma de (FRIENDS_MESSAGE, YOUR RESPONSE). Um arquivo chamado conversaData.txt também será criado. Este é simplesmente um grande arquivo de texto com os dados do dicionário em um formato unificado.
Agora que temos esses 2 arquivos, podemos começar a criar nossos vetores de palavras através de um modelo Word2Vec. Esta etapa é um pouco diferente das outras. A função Tensorflow que vemos mais tarde (em seq2seq.py) na verdade também lida com a parte de incorporação. Portanto, você pode decidir treinar seus próprios vetores ou fazer com que a função seq2seq faça isso em conjunto, que foi o que acabei fazendo. Se você deseja criar seus próprios vetores de palavras através do Word2Vec, diga y no prompt (depois de executar o seguinte). Caso contrário, tudo bem, responda n e esta função criará apenas o wordList.txt.
python Word2Vec.pySe você executar word2vec.py completo, serão criados 4 arquivos diferentes. Word2VecXTrain.npy e Word2VecYTrain.npy são as matrizes de treinamento que o Word2Vec usará. Nós os salvamos em nossa pasta, caso precisemos treinar nosso modelo Word2Vec novamente com diferentes hiperparâmetros. Também salvamos wordList.txt , que simplesmente contém todas as palavras exclusivas em nosso corpus. O último arquivo salvo é embeddingMatrix.npy que é uma matriz Numpy que contém todos os vetores de palavras gerados.
Agora, podemos criar e treinar nosso modelo Seq2Seq.
python Seq2Seq.pyIsso criará 3 ou mais arquivos diferentes. Seq2SeqXTrain.npy e Seq2SeqYTrain.npy são as matrizes de treinamento que o Seq2Seq usará. Novamente, nós os salvamos caso queiramos fazer alterações em nossa arquitetura de modelo e não queiramos recalcular nosso conjunto de treinamento. Os últimos arquivos serão arquivos .ckpt que contêm nosso modelo Seq2Seq salvo. Os modelos serão salvos em diferentes períodos de tempo no ciclo de treinamento. Eles serão usados e implantados assim que criarmos nosso chatbot.
Agora que temos um modelo salvo, vamos criar nosso chatbot do Facebook. Para fazer isso, recomendo seguir este tutorial. Você não precisa ler nada abaixo da seção “Personalizar o que o bot diz”. Nosso modelo Seq2Seq cuidará dessa parte. IMPORTANTE - O tutorial solicitará que você crie uma nova pasta onde ficará o projeto Node. Tenha em mente que esta pasta será diferente da nossa pasta. Você pode pensar nesta pasta como sendo onde fica nosso pré-processamento de dados e treinamento de modelo, enquanto a outra pasta é estritamente reservada para o aplicativo Express (EDIT: acredito que você pode seguir os passos do tutorial dentro de nossa pasta e apenas criar o projeto Node, Procfile e index.js aqui, se desejar). O tutorial em si deve ser suficiente, mas aqui está um resumo das etapas.
Depois de seguir as etapas corretamente, você poderá enviar mensagens ao chatbot e obter respostas.
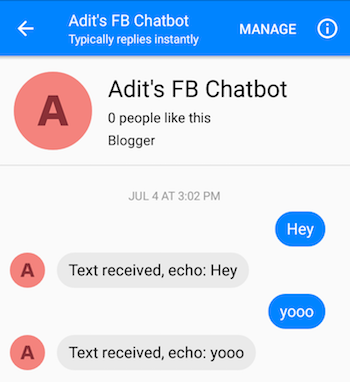
Ah, você está quase terminando! Agora, temos que criar um servidor Flask onde possamos implantar nosso modelo Seq2Seq salvo. Eu tenho o código desse servidor aqui. Vamos falar sobre a estrutura geral. Os servidores Flask normalmente têm um arquivo .py principal onde você define todos os endpoints. Este será app.py no nosso caso. Será aqui que carregaremos nosso modelo. Você deve criar uma pasta chamada 'models' e preenchê-la com 4 arquivos (um arquivo de checkpoint, um arquivo de dados, um arquivo de índice e um meta-arquivo). Esses são os arquivos criados quando você salva um modelo do Tensorflow.

Neste arquivo app.py, queremos criar uma rota (/prediction no meu caso) onde a entrada da rota será alimentada em nosso modelo salvo, e a saída do decodificador será a string retornada. Vá em frente e dê uma olhada em app.py se ainda estiver um pouco confuso. Agora que você tem seu app.py e seus modelos (e outros arquivos auxiliares, se precisar deles), você pode implantar seu servidor. Usaremos o Heroku novamente. Existem muitos tutoriais diferentes sobre como implantar servidores Flask no Heroku, mas eu gosto deste em particular (não precisa das seções Foreman e Logging).
Aí está. Você deverá ser capaz de enviar mensagens para o chatbot e ver algumas respostas interessantes que (espero) se pareçam com você de alguma forma.
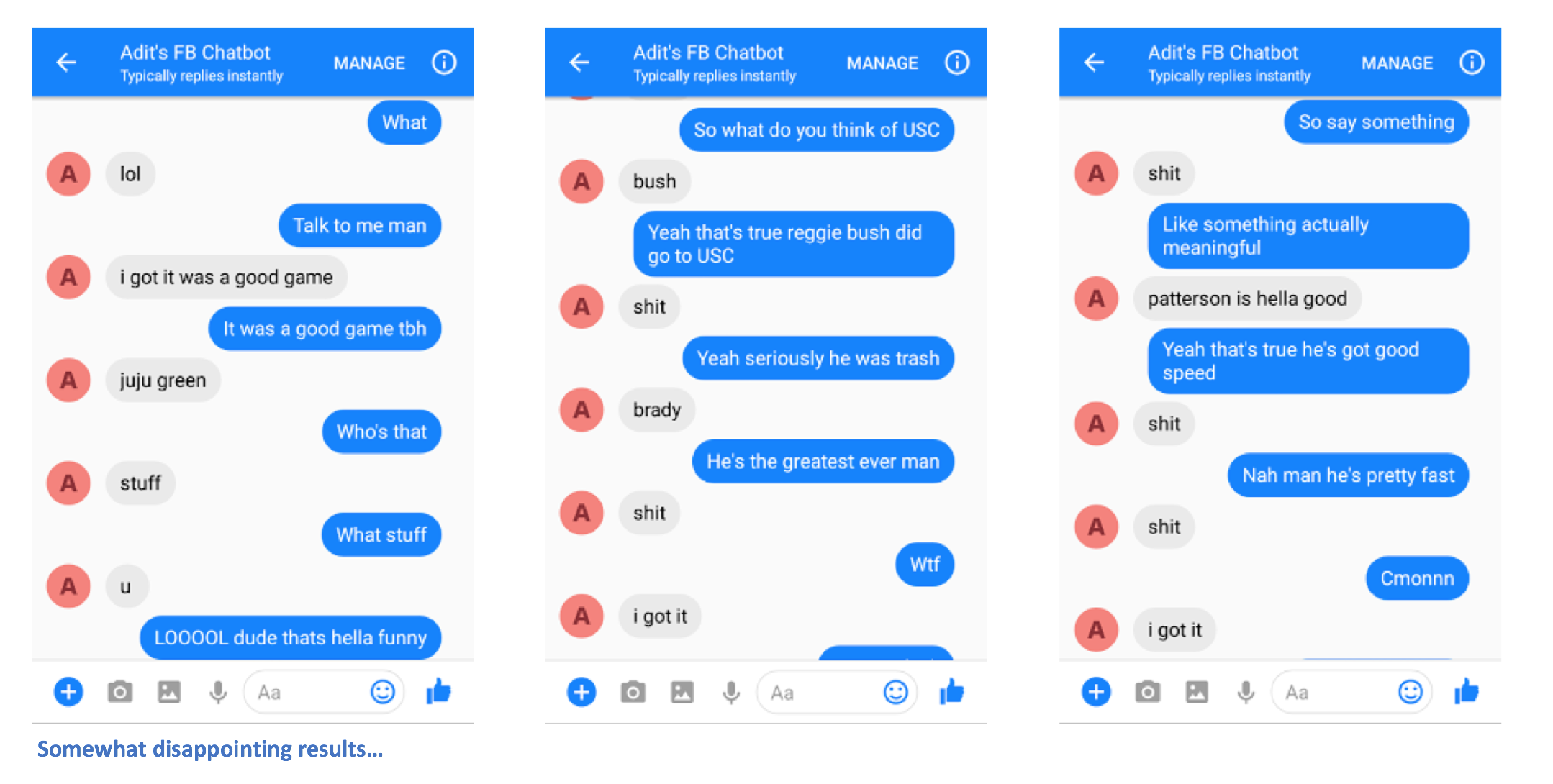
Por favor, deixe-me saber se você tiver algum problema ou se tiver alguma sugestão para melhorar este README. Se você achou que uma determinada etapa não estava clara, me avise e farei o possível para editar o README e fazer quaisquer esclarecimentos.


