snips nlu
0.20.2
Snips NLU (Natural Language Understanding) é uma biblioteca Python que permite extrair informações estruturadas de frases escritas em linguagem natural.
Por trás de cada chatbot e assistente de voz existe uma tecnologia comum: Natural Language Understanding (NLU). Sempre que um usuário interage com uma IA usando linguagem natural, suas palavras precisam ser traduzidas em uma descrição legível por máquina do que elas significam.
O mecanismo NLU primeiro detecta qual é a intenção do usuário (também conhecida como intenção) e, em seguida, extrai os parâmetros (chamados de slots) da consulta. O desenvolvedor pode então usar isso para determinar a ação ou resposta apropriada.
Vamos dar um exemplo para ilustrar isso e considerar a seguinte frase:
"Como estará o tempo em Paris às 21h?"
Devidamente treinado, o motor Snips NLU será capaz de extrair dados estruturados como:
{
"intent" : {
"intentName" : " searchWeatherForecast " ,
"probability" : 0.95
},
"slots" : [
{
"value" : " paris " ,
"entity" : " locality " ,
"slotName" : " forecast_locality "
},
{
"value" : {
"kind" : " InstantTime " ,
"value" : " 2018-02-08 20:00:00 +00:00 "
},
"entity" : " snips/datetime " ,
"slotName" : " forecast_start_datetime "
}
]
} Neste caso, a intenção identificada é searchWeatherForecast e dois slots foram extraídos, uma localidade e uma data e hora. Como você pode ver, o Snips NLU realiza uma etapa extra além da extração de entidades: ele as resolve. O valor de data e hora extraído foi de fato convertido em um formato ISO útil.
Confira nossa postagem no blog para obter mais detalhes sobre por que criamos o Snips NLU e como ele funciona nos bastidores. Também publicamos um artigo sobre arxiv, apresentando a arquitetura de aprendizado de máquina da plataforma Snips Voice.
pip install snips - nlu Atualmente temos binários pré-construídos (wheels) para snips-nlu e suas dependências para MacOS (10.11 e posterior), Linux x86_64 e Windows.
Para qualquer outra arquitetura/sistema operacional, o snips-nlu pode ser instalado a partir da distribuição fonte. Para fazer isso, Rust e setuptools_rust devem ser instalados antes de executar o comando pip install snips-nlu .
Snips NLU depende de recursos de linguagem externos que devem ser baixados antes que a biblioteca possa ser usada. Você pode buscar recursos para um idioma específico executando o seguinte comando:
python -m snips_nlu download enOu simplesmente:
snips-nlu download enA lista de idiomas suportados está disponível neste endereço.
A maneira mais fácil de testar as capacidades desta biblioteca é através da interface de linha de comando.
Primeiro, comece treinando a NLU com um dos conjuntos de dados de amostra:
snips-nlu train path/to/dataset.json path/to/output_trained_engine Onde path/to/dataset.json é o caminho para o conjunto de dados que será usado durante o treinamento e path/to/output_trained_engine é o local onde o mecanismo treinado deve persistir após a conclusão do treinamento.
Depois disso, você pode começar a analisar frases interativamente executando:
snips-nlu parse path/to/trained_engine Onde path/to/trained_engine corresponde ao local onde você armazenou o mecanismo treinado durante a etapa anterior.
Aqui está um exemplo de código que você pode executar em sua máquina após instalar o snips-nlu, buscar os recursos em inglês e baixar um dos conjuntos de dados de exemplo:
>> > from __future__ import unicode_literals , print_function
>> > import io
>> > import json
>> > from snips_nlu import SnipsNLUEngine
>> > from snips_nlu . default_configs import CONFIG_EN
>> > with io . open ( "sample_datasets/lights_dataset.json" ) as f :
... sample_dataset = json . load ( f )
>> > nlu_engine = SnipsNLUEngine ( config = CONFIG_EN )
>> > nlu_engine = nlu_engine . fit ( sample_dataset )
>> > text = "Please turn the light on in the kitchen"
>> > parsing = nlu_engine . parse ( text )
>> > parsing [ "intent" ][ "intentName" ]
'turnLightOn'O que ele faz é treinar um mecanismo NLU em um conjunto de dados meteorológicos de amostra e analisar uma consulta meteorológica.
Aqui está uma lista de alguns conjuntos de dados que podem ser usados para treinar um mecanismo Snips NLU:
Em janeiro de 2018, reproduzimos um benchmark acadêmico publicado durante o verão de 2017. Neste artigo, os autores avaliaram o desempenho de API.ai (agora Dialogflow, Google), Luis.ai (Microsoft), IBM Watson e Rasa NLU. Para ser justo, usamos uma versão atualizada do Rasa NLU e a comparamos com a versão mais recente do Snips NLU (ambos em azul escuro).
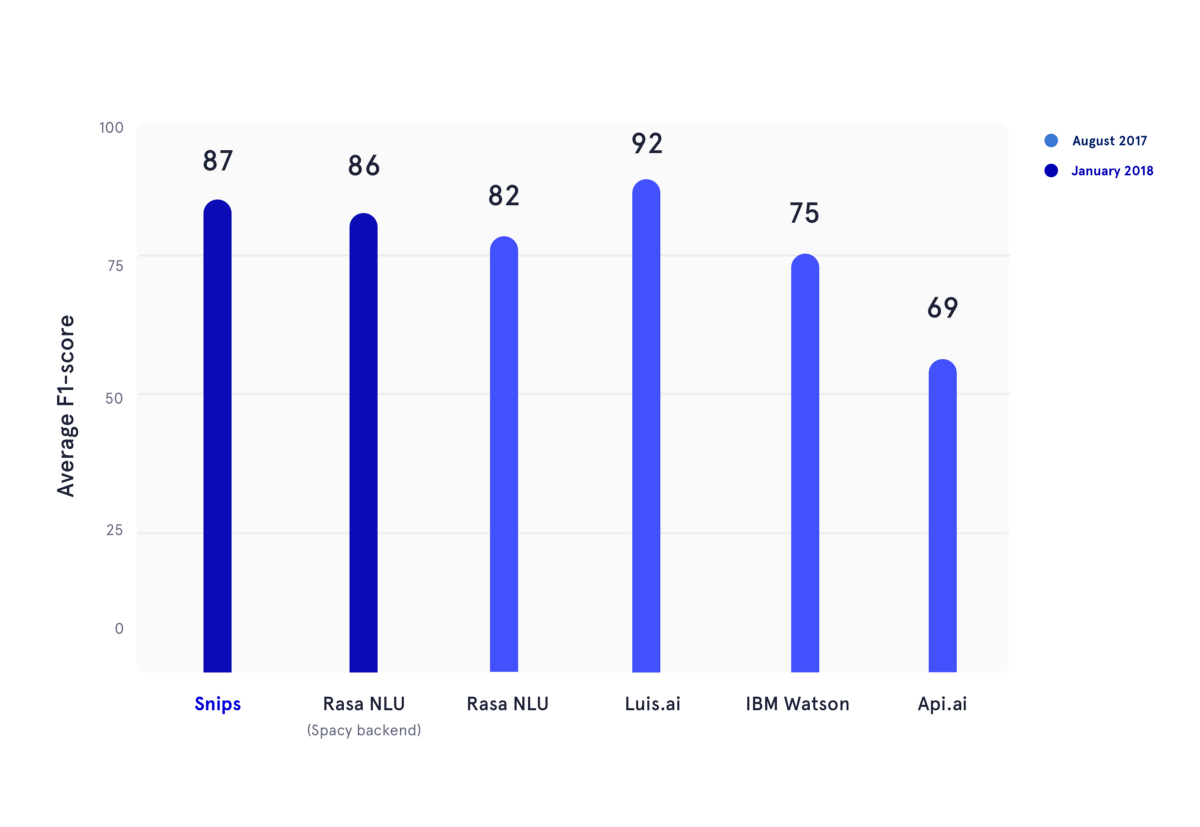
Na figura acima, as pontuações F1 de classificação de intenção e preenchimento de slots foram calculadas para vários provedores de NLU e calculadas a média dos três conjuntos de dados usados no benchmark acadêmico mencionado anteriormente. Todos os resultados subjacentes podem ser encontrados aqui.
Para saber como usar o Snips NLU, consulte a documentação do pacote, ela fornecerá um guia passo a passo sobre como configurar e usar esta biblioteca.
Por favor, cite o seguinte artigo ao usar Snips NLU:
@article { coucke2018snips ,
title = { Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces } ,
author = { Coucke, Alice and Saade, Alaa and Ball, Adrien and Bluche, Th{'e}odore and Caulier, Alexandre and Leroy, David and Doumouro, Cl{'e}ment and Gisselbrecht, Thibault and Caltagirone, Francesco and Lavril, Thibaut and others } ,
journal = { arXiv preprint arXiv:1805.10190 } ,
pages = { 12--16 } ,
year = { 2018 }
}Participe do fórum para fazer suas perguntas e obter feedback da comunidade.
Consulte as Diretrizes de Contribuição.
Esta biblioteca é fornecida pela Snips como software de código aberto. Consulte LICENÇA para obter mais informações.
As entidades integradas snips/city, snips/country e snips/region contam com software da Geonames, que é disponibilizado sob uma licença internacional Creative Commons Attribution 4.0. Para obter a licença e garantias para Geonames, consulte: https://creativecommons.org/licenses/by/4.0/legalcode.


