Resposta de mensagem inteligente
Você já viu ou usou o Google Smart Reply? É um serviço que oferece sugestões de resposta automática para mensagens de usuários. Veja abaixo.
Esta é uma aplicação útil do chatbot baseado em recuperação. Pense nisso. Quantas vezes enviamos uma mensagem como obrigado , ei ou até mais ? Neste projeto, construímos um sistema simples de sugestão de resposta de mensagens.
Parque Kyubyong
Revisão de código por Yj Choe
Grupo sinônimo
- Precisamos definir a lista de sugestões a serem mostradas. Naturalmente, a frequência é considerada em primeiro lugar. Mas e aquelas frases que têm significado semelhante? Por exemplo, deveria muito obrigado e obrigado a ser tratado de forma independente? Nós não pensamos assim. Queremos agrupá-los e salvar nossos slots. Como? Fazemos uso de um corpus paralelo. Muito obrigado e obrigado provavelmente serão traduzidos no mesmo texto. Com base nessa suposição, construímos grupos de sinônimos em inglês que compartilham a mesma tradução.
Modelo
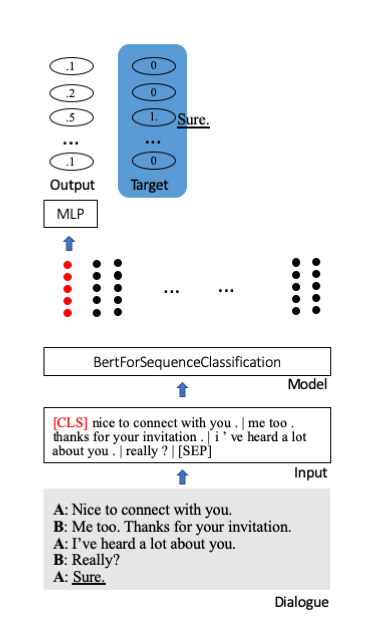
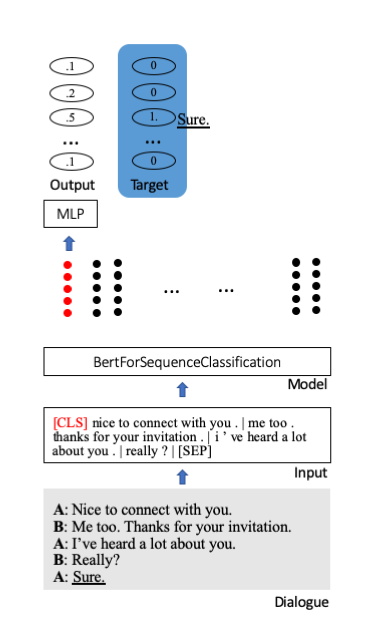
Ajustamos o modelo pré-treinado de Bert do huggingface para classificação de sequência. Nele, um token inicial especial [CLS] armazena todas as informações de uma frase. Camadas extras são anexadas para projetar as informações condensadas em unidades de classificação (aqui 100).
Dados
- Usamos o corpus paralelo espanhol-inglês do OpenSubtitles 2018 para construir grupos de sinônimos. OpenSubtitles é uma grande coleção de legendas de filmes traduzidas. Os dados en-es consistem em mais de 61 milhões de linhas alinhadas.
- Idealmente, é necessário um corpus de diálogo (muito) grande para o treinamento, o que não conseguimos encontrar. Em vez disso, usamos o Cornell Movie Dialogue Corpus. É composto por 83.097 diálogos ou 304.713 linhas.
Requisitos
- píton>=3.6
- tqdm>=4.30.0
- pytorch> = 1,0
- pytorch_pretrained_bert>=0.6.1
- nltk>=3,4
Treinamento
- PASSO 0. Baixe os dados paralelos do OpenSubtitles 2018 espanhol-inglês.
- PASSO 1. Construa grupos de sinônimos a partir do corpus.
- PASSO 2. Faça os dicionários phr2sg_id e sg_id2phr.
- PASSO 3. Converta um texto monolíngue em inglês em ids.
- ETAPA 4. Crie dados de treinamento e salve-os como pickle.
Teste (demonstração)
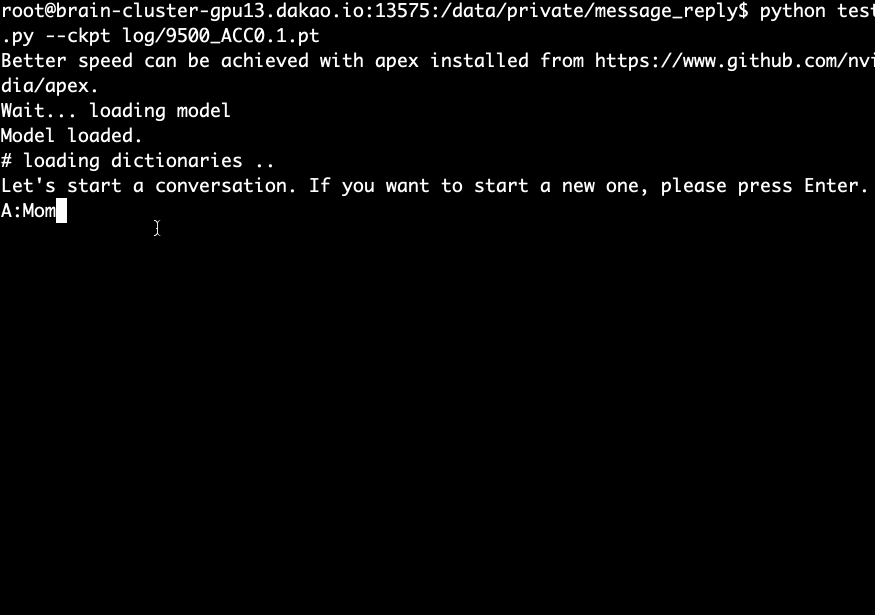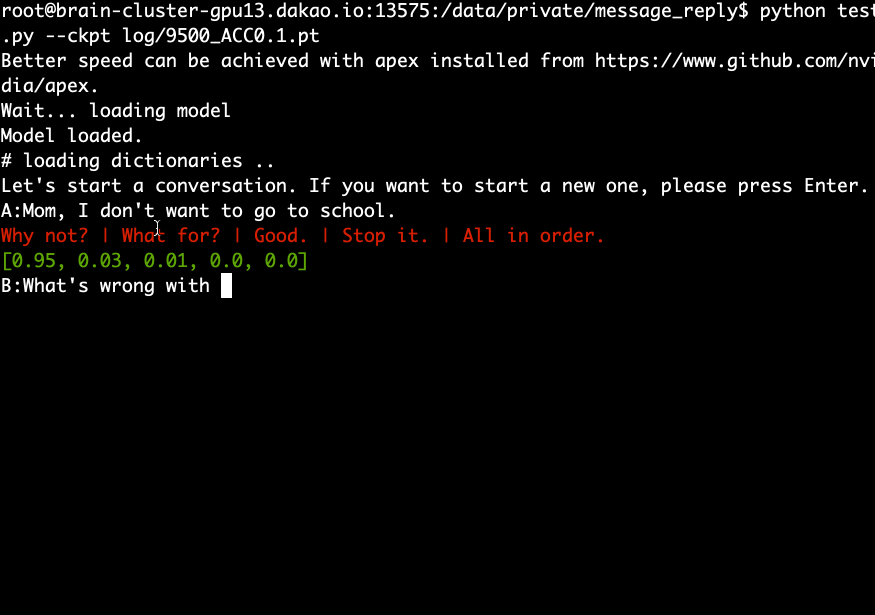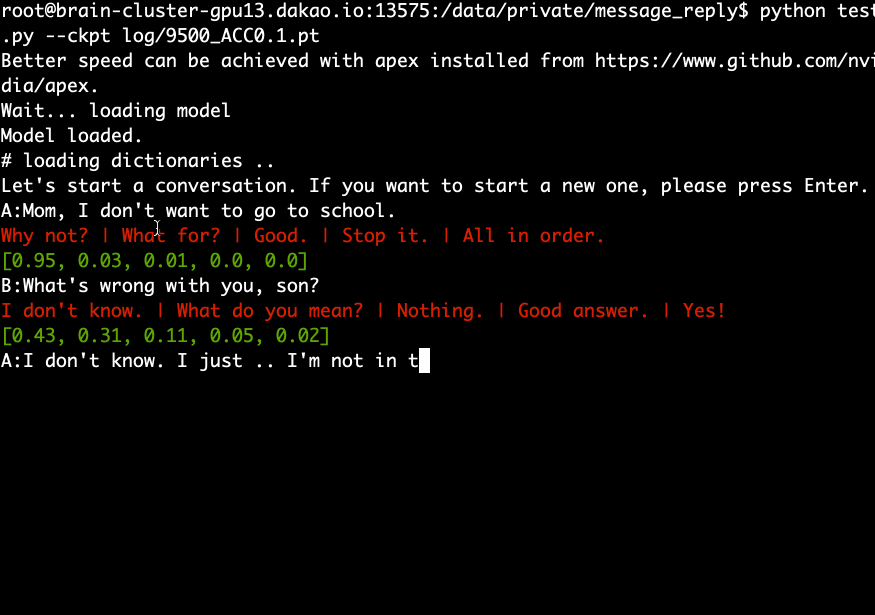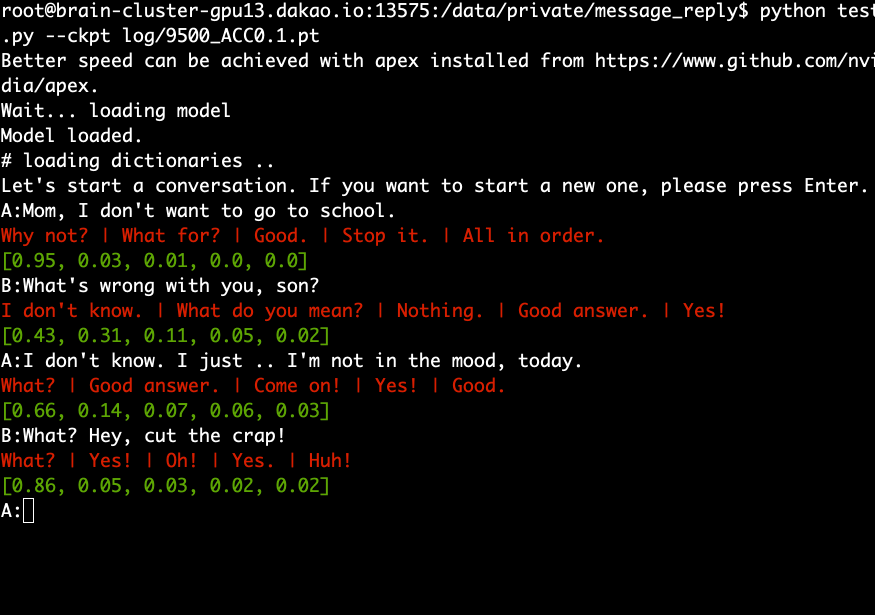
- Baixe e extraia o modelo pré-treinado e execute o seguinte comando.
python test.py --ckpt log/9500_ACC0.1.pt
Notas
- A perda de treinamento diminui lenta mas continuamente.
- Accuracy@5 nos dados de avaliação é de 10 a 20 por cento.
- Para uma aplicação real, é necessário um corpus muito maior.
- Não tenho certeza de quanto os roteiros de filmes são semelhantes aos diálogos de mensagens.
- É necessária uma estratégia melhor para construir grupos de sinônimos.
- Um chatbot baseado em recuperação é um aplicativo realista, pois é mais seguro e fácil do que um chatbot baseado em geração.