ThinkRAG
1.0.0
Inglês | Chinês Simplificado
O sistema de geração de aprimoramento de recuperação de modelos grandes ThinkRAG pode ser facilmente implantado em um laptop para obter respostas inteligentes a perguntas em uma base de conhecimento local.
O sistema é construído com base em LlamaIndex e Streamlit e foi otimizado para usuários domésticos em diversas áreas, como seleção de modelos e processamento de texto.
ThinkRAG é um sistema aplicativo de modelo grande desenvolvido para profissionais, pesquisadores, estudantes e outros trabalhadores do conhecimento. Ele pode ser usado diretamente em laptops e os dados da base de conhecimento são salvos localmente no computador.
ThinkRAG possui os seguintes recursos:
Em particular, ThinkRAG também fez muitas customizações e otimizações para usuários domésticos:
ThinkRAG pode usar todos os modelos suportados pelo quadro de dados LlamaIndex. Para obter informações sobre a lista de modelos, consulte a documentação relevante.
ThinkRAG está comprometido em criar um sistema aplicativo que seja diretamente utilizável, útil e fácil de usar.
Portanto, fizemos escolhas cuidadosas e compensações entre vários modelos, componentes e tecnologias.
Primeiro, usando modelos grandes, ThinkRAG suporta API OpenAI e todas as APIs LLM compatíveis, incluindo grandes fabricantes nacionais de modelos, como:
Se você deseja implantar modelos grandes localmente, o ThinkRAG escolhe o Ollama, que é simples e fácil de usar. Podemos baixar modelos grandes para rodar localmente através do Ollama.
Atualmente, Ollama suporta a implantação localizada de quase todos os grandes modelos convencionais, incluindo Llama, Gemma, GLM, Mistral, Phi, Llava, etc. Para obter detalhes, visite o site oficial da Ollama abaixo.
O sistema também usa modelos incorporados e modelos reorganizados e suporta a maioria dos modelos do Hugging Face. Atualmente, o ThinkRAG usa principalmente os modelos da série BGE da BAAI. Os usuários domésticos podem visitar o site espelho para aprender e fazer download.
Depois de baixar o código do Github, use pip para instalar os componentes necessários.
pip3 install -r requirements.txtPara executar o sistema offline, primeiro baixe o Ollama do site oficial. Em seguida, use o comando Ollama para baixar modelos grandes como GLM, Gemma e QWen.
De forma síncrona, baixe o modelo de incorporação (BAAI/bge-large-zh-v1.5) e o modelo de reclassificação (BAAI/bge-reranker-base) de Hugging Face para o diretório localmodels.
Para etapas específicas, consulte o documento no diretório de documentos: HowToDownloadModels.md
Para obter melhor desempenho, recomenda-se a utilização da API LLM de modelo comercial grande com centenas de bilhões de parâmetros.
Primeiro, obtenha a chave API do provedor de serviços LLM e configure as variáveis de ambiente a seguir.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "Você pode pular esta etapa e configurar a chave API por meio da interface do aplicativo após o sistema estar em execução.
Se você optar por usar uma ou mais APIs LLM, exclua o provedor de serviços que você não usa mais no arquivo de configuração config.py.
Claro, você também pode adicionar outros provedores de serviços compatíveis com a API OpenAI no arquivo de configuração.
ThinkRAG é executado em modo de desenvolvimento por padrão. Neste modo, o sistema utiliza armazenamento de arquivos local e não é necessário instalar nenhum banco de dados.
Para mudar para o modo de produção, você pode configurar as variáveis de ambiente da seguinte maneira.
THINKRAG_ENV = productionNo modo de produção, o sistema usa o banco de dados vetorial Chroma e o banco de dados de valores-chave Redis.
Se você não possui o Redis instalado, é recomendável instalá-lo por meio do Docker ou usar uma instância existente do Redis. Configure as informações de parâmetro da instância Redis no arquivo config.py.
Agora você está pronto para executar o ThinkRAG.
Execute o seguinte comando no diretório que contém o arquivo app.py.
streamlit run app.pyO sistema será executado e abrirá automaticamente o seguinte URL no navegador para exibir a interface do aplicativo.
http://localhost:8501/
A primeira execução pode demorar um pouco. Se o modelo incorporado no Hugging Face não for baixado com antecedência, o sistema fará o download automaticamente do modelo e você precisará esperar mais.
ThinkRAG suporta a configuração e seleção de modelos grandes na interface do usuário, incluindo: o URL base e a chave de API da API LLM de modelo grande, e você pode selecionar o modelo específico a ser usado, por exemplo: glm-4 do ThinkRAG.
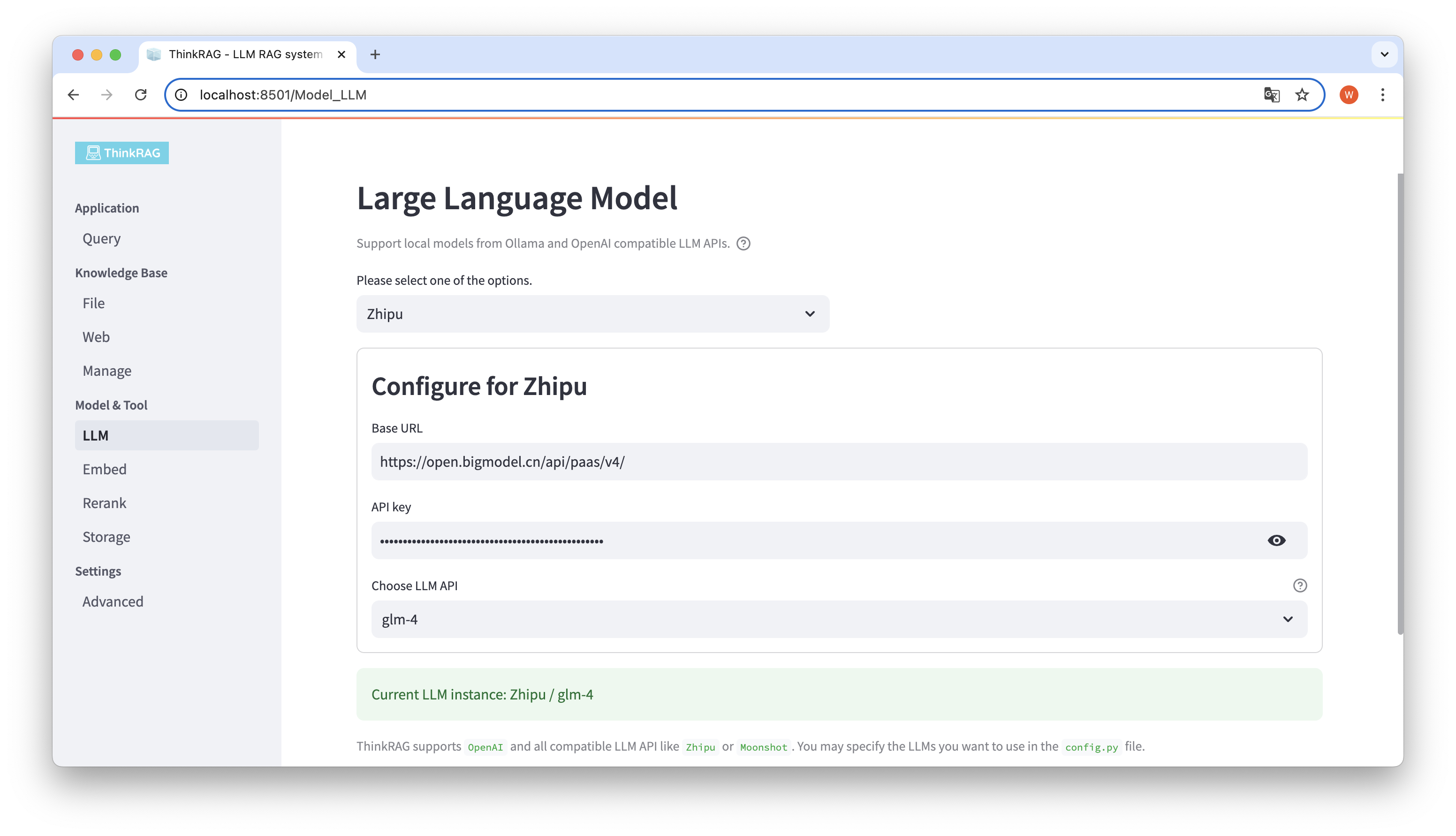
O sistema detectará automaticamente se a API e a chave estão disponíveis. Se disponíveis, a instância do modelo grande atualmente selecionada será exibida em texto verde na parte inferior.
Da mesma forma, o sistema pode obter automaticamente os modelos baixados pelo Ollama, e o usuário pode selecionar o modelo desejado na interface do usuário.
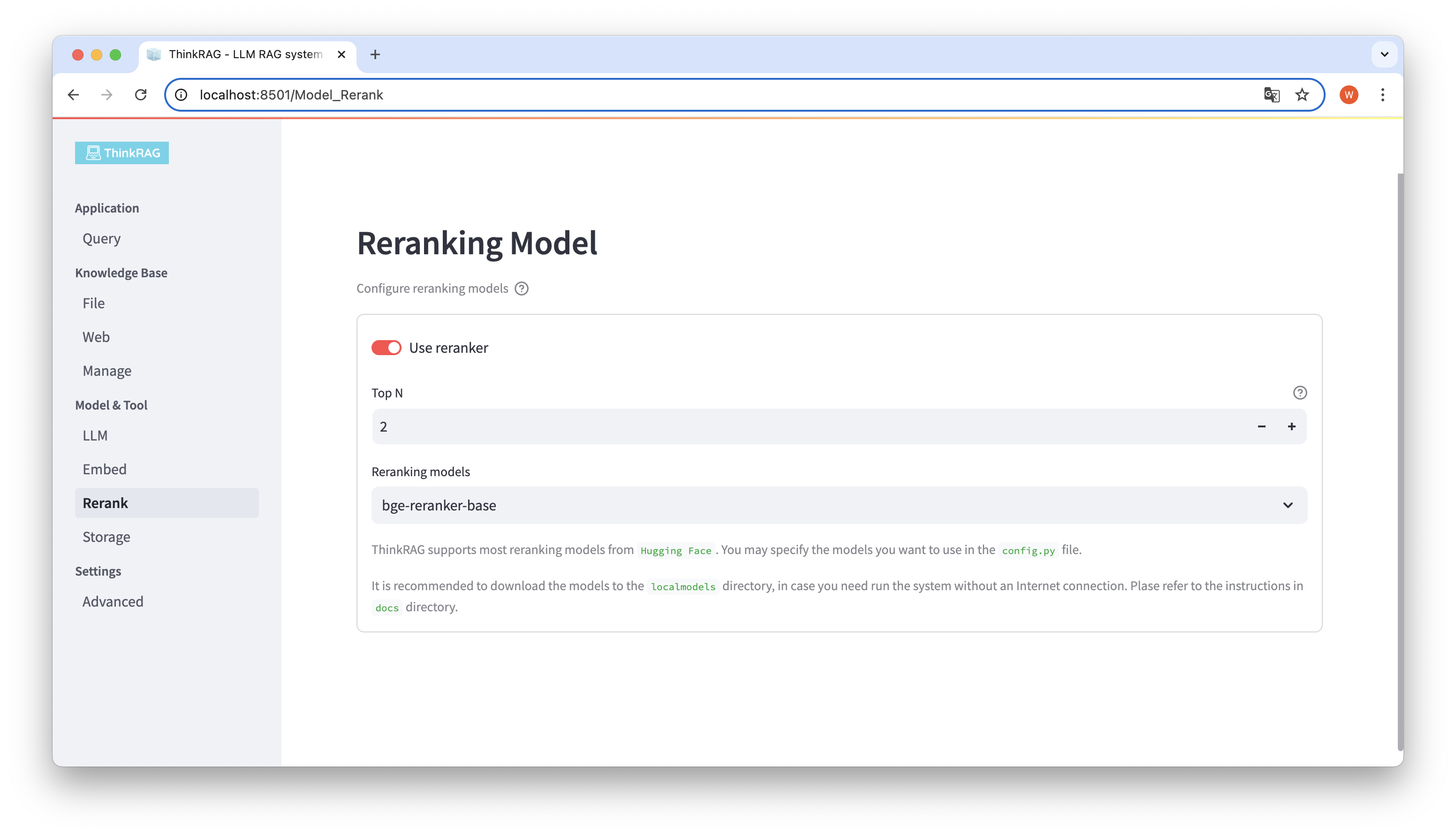
Se você baixou o modelo incorporado e o modelo reorganizado para o diretório localmodels. Na interface do usuário, você pode alternar o modelo selecionado e definir os parâmetros do modelo reorganizado, como Top N.
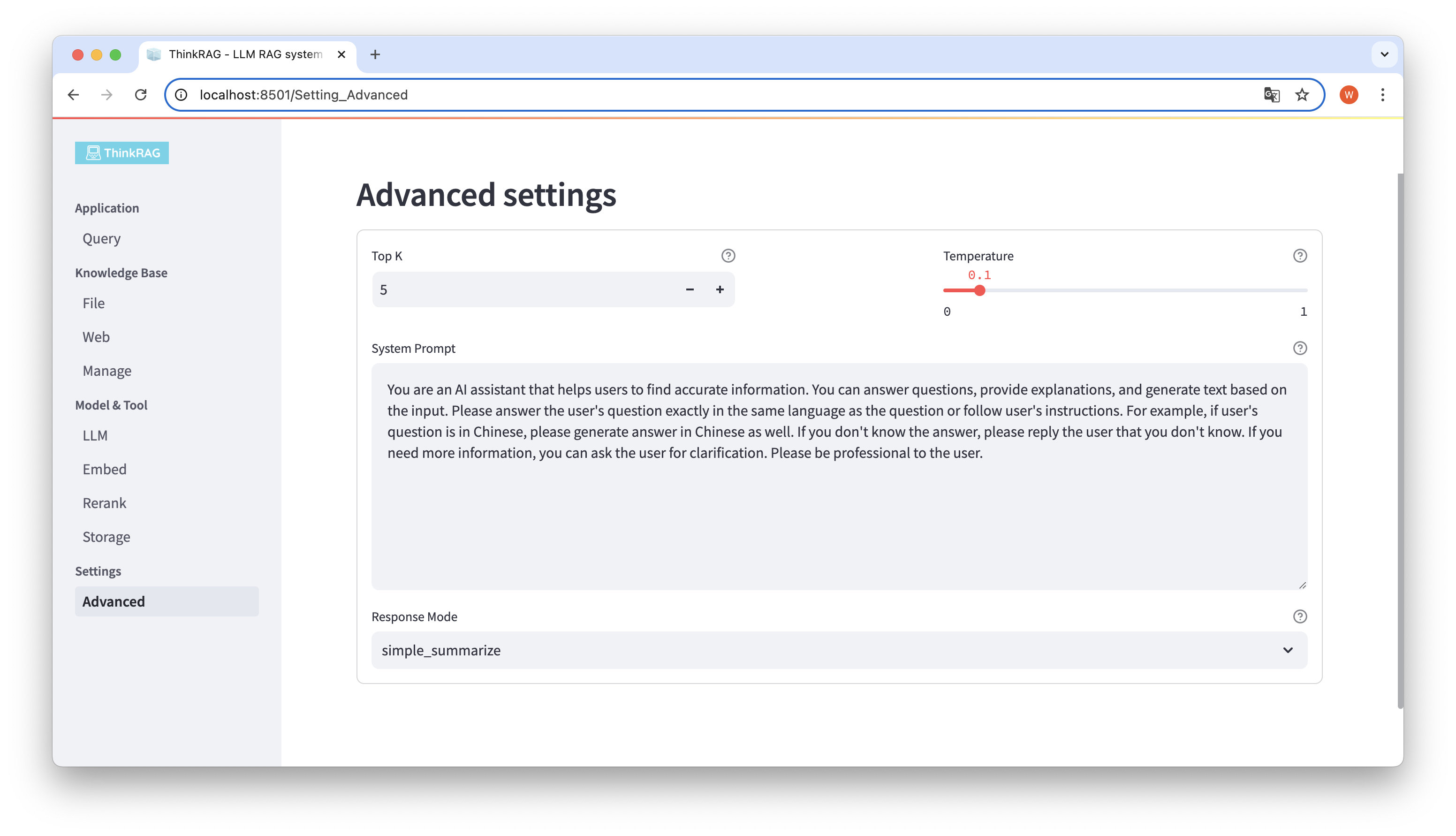
Na barra de navegação esquerda, clique em Configurações avançadas (Configurações-Avançado). Você também pode definir os seguintes parâmetros:
Usando parâmetros diferentes, podemos comparar resultados de grandes modelos e encontrar a combinação de parâmetros mais eficaz.
ThinkRAG suporta o upload de vários arquivos, como PDF, DOCX, PPTX, etc., e também suporta o upload de URLs de páginas da web.
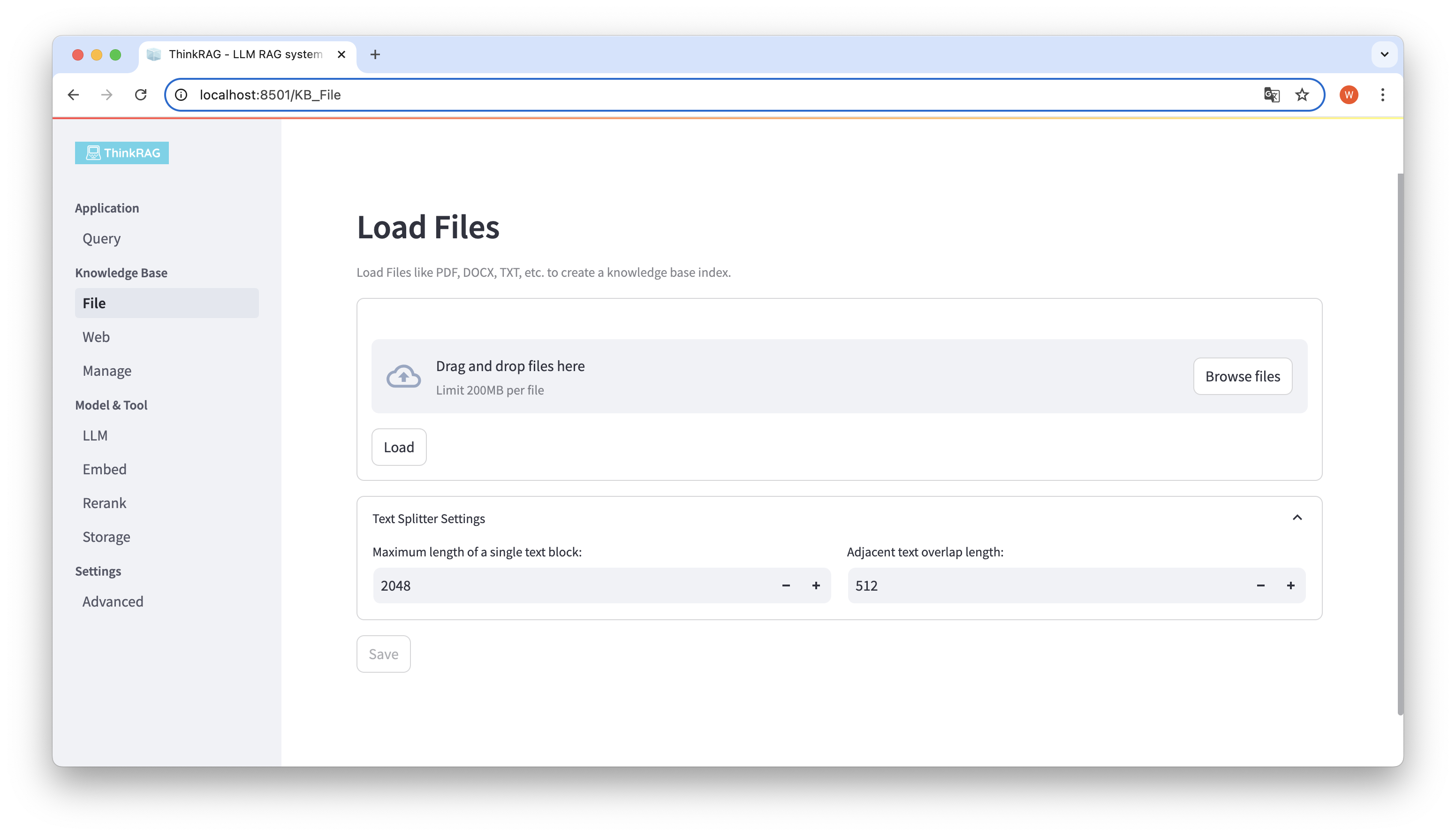
Clique no botão Procurar arquivos, selecione o arquivo em seu computador e clique no botão Carregar para carregar todos os arquivos carregados.
Em seguida, clique no botão Salvar e o sistema processará o arquivo, incluindo segmentação e incorporação de texto, e o salvará na base de conhecimento.
Da mesma forma, você pode inserir ou colar o URL da página da web, obter as informações da página da web e salvá-las na base de conhecimento após o processamento.
O sistema suporta o gerenciamento da base de conhecimento.
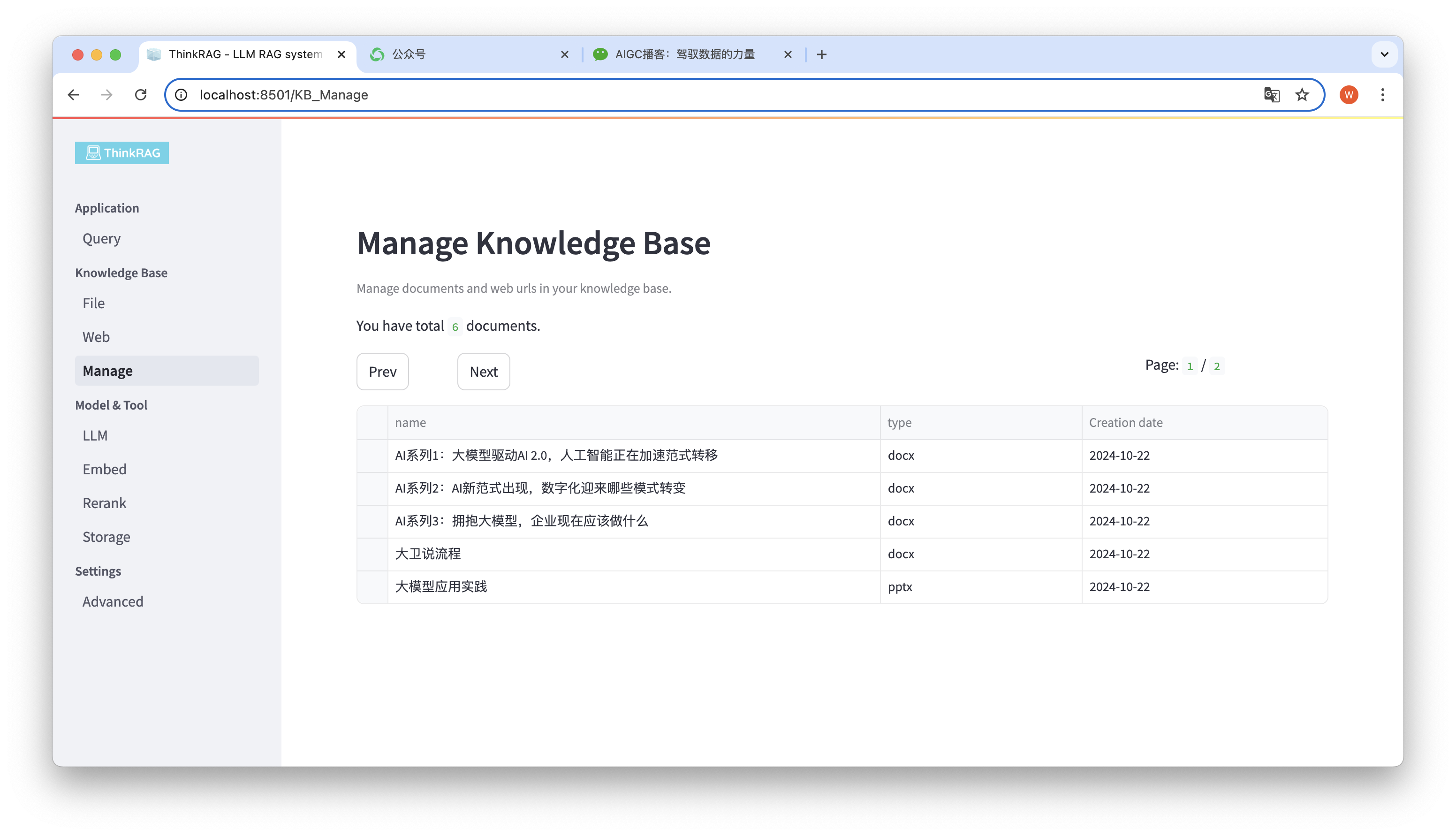
Conforme mostrado na figura acima, ThinkRAG pode listar todos os documentos da base de conhecimento em páginas.
Selecione os documentos a serem excluídos e o botão Excluir documentos selecionados aparecerá. Clique neste botão para excluir os documentos da base de conhecimento.
Na barra de navegação esquerda, clique em Consulta e a página inteligente de perguntas e respostas aparecerá.
Após inserir a pergunta, o sistema irá pesquisar a base de conhecimento e fornecer uma resposta. Durante esse processo, o sistema utilizará tecnologias como recuperação e reorganização híbrida para obter conteúdo preciso da base de conhecimento.
Por exemplo, carregamos um documento Word na base de conhecimento: "David Says Process.docx".
Agora insira a pergunta: “Quais são as três características de um processo?”
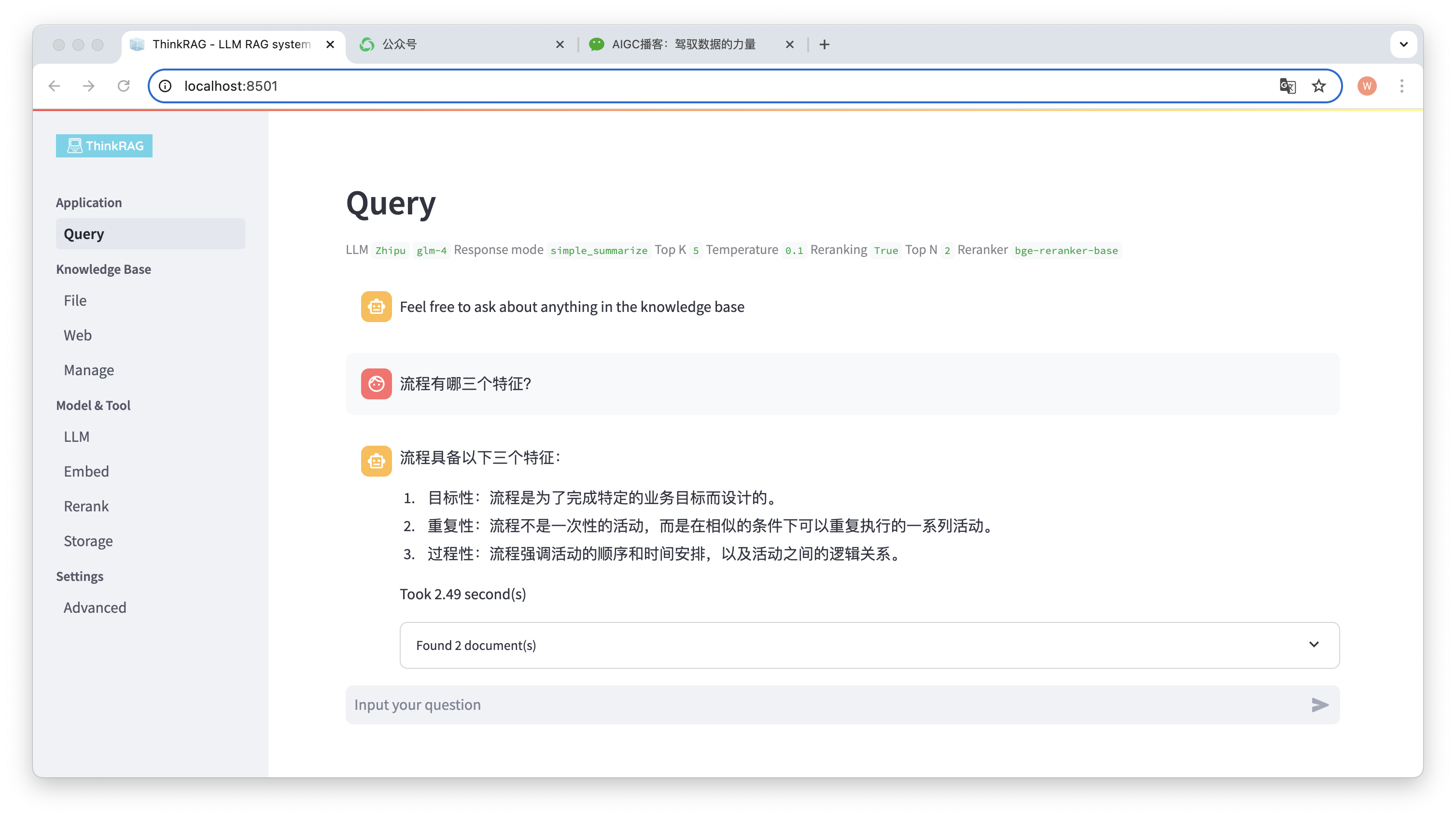
Conforme mostrado na figura, o sistema demorou 2,49 segundos para dar uma resposta precisa: o processo é direcionado, repetitivo e processual. Ao mesmo tempo, o sistema também fornece 2 documentos relacionados recuperados da base de conhecimento.
Pode-se observar que o ThinkRAG implementa de forma completa e eficaz a função de geração aprimorada de recuperação de grandes modelos com base na base de conhecimento local.
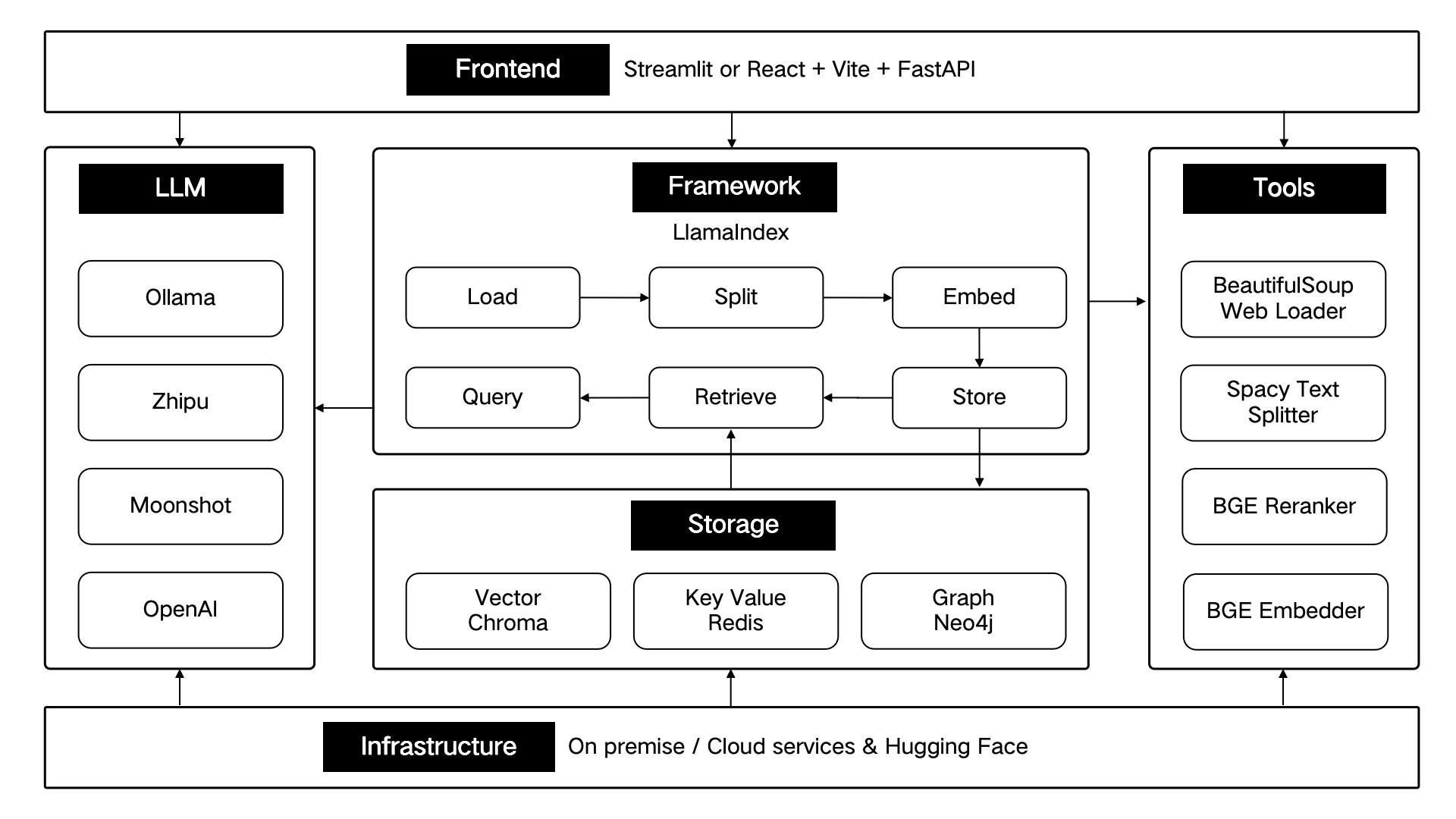
ThinkRAG é desenvolvido usando a estrutura de dados LlamaIndex e usa Streamlit para o front-end. O modo de desenvolvimento e o modo de produção do sistema utilizam componentes técnicos diferentes respectivamente, conforme mostrado na tabela a seguir:
| modo de desenvolvimento | modo de produção | |
|---|---|---|
| Estrutura RAG | LhamaIndex | LhamaIndex |
| estrutura de front-end | Streamlit | Streamlit |
| modelo incorporado | BAAI/bge-small-zh-v1.5 | BAAI/bge-grande-zh-v1.5 |
| reorganizar modelo | BAAI/bge-reclassificador-base | BAAI/bge-reclassificador-grande |
| divisor de texto | SentençaSplitter | SpacyTextSplitter |
| Armazenamento de conversas | SimpleChatStore | Redis |
| Armazenamento de documentos | SimpleDocumentStore | Redis |
| Armazenamento de índice | SimpleIndexStore | Redis |
| armazenamento de vetores | SimpleVectorStore | LanceDB |
Esses componentes técnicos são projetados arquitetonicamente de acordo com seis partes: front-end, estrutura, modelo grande, ferramentas, armazenamento e infraestrutura.
Conforme mostrado abaixo:
ThinkRAG continuará a otimizar as funções principais e a melhorar a eficiência e a precisão da recuperação, incluindo principalmente:
Ao mesmo tempo, melhoraremos ainda mais a arquitetura do aplicativo e aprimoraremos a experiência do usuário, incluindo principalmente:
Você está convidado a participar do projeto de código aberto ThinkRAG e trabalhar em conjunto para criar produtos de IA que os usuários adoram!
ThinkRAG usa a licença do MIT.


