RLAIF V
1.0.0

Alinhando MLLMs por meio de feedback de IA de código aberto para confiabilidade Super GPT-4V
中文 | Inglês
[2024.11.26] Apoiamos o treinamento LoRA agora!
[2024.05.28] Nosso artigo está acessível no arXiv agora!
[2024.05.20] Nosso conjunto de dados RLAIF-V é usado para treinar MiniCPM-Llama3-V 2.5, que representa o primeiro MLLM de nível GPT-4V final!
[2024.05.20] Abrimos o código, pesos (7B, 12B) e dados do RLAIF-V!
Apresentamos o RLAIF-V, uma nova estrutura que alinha MLLMs em um paradigma totalmente aberto para confiabilidade super GPT-4V. O RLAIF-V explora ao máximo o feedback de código aberto a partir de duas perspectivas principais, incluindo dados de feedback de alta qualidade e algoritmo de aprendizagem de feedback online. Os recursos notáveis do RLAIF-V incluem:
Confiabilidade do Super GPT-4V por meio de feedback de código aberto . Ao aprender com o feedback de IA de código aberto, o RLAIF-V 12B alcança a confiabilidade super GPT-4V em tarefas generativas e discriminativas.
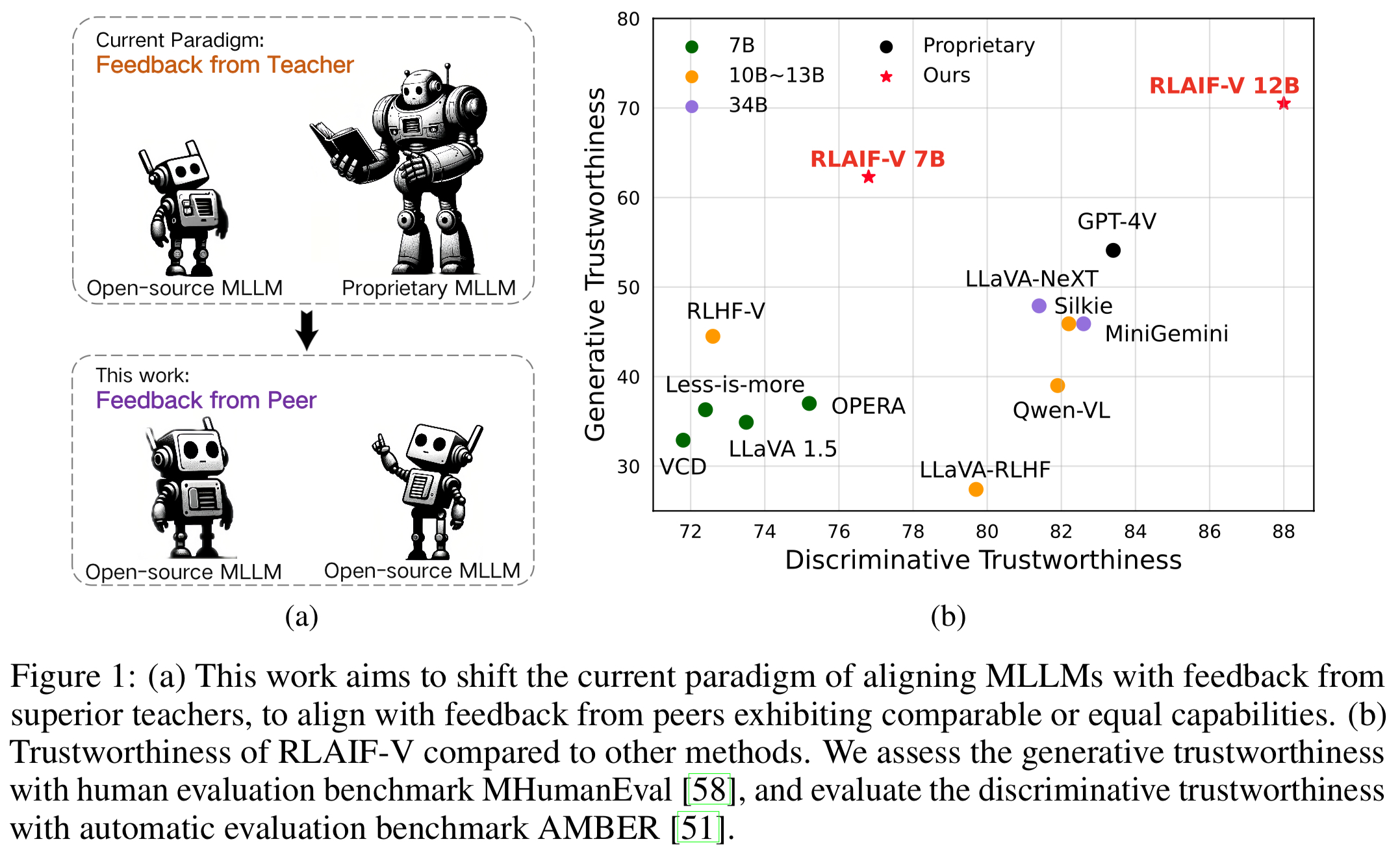
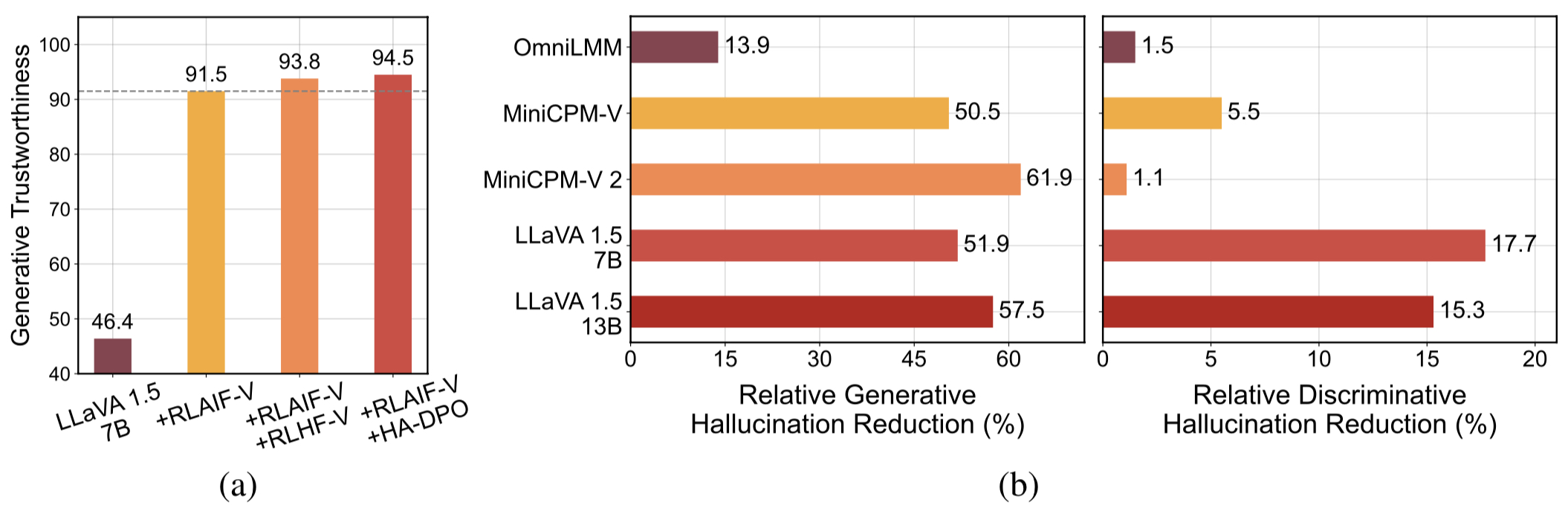
Dados de feedback generalizáveis de alta qualidade . Os dados de feedback usados pelo RLAIF-V reduzem efetivamente a alucinação de diferentes MLLMs .
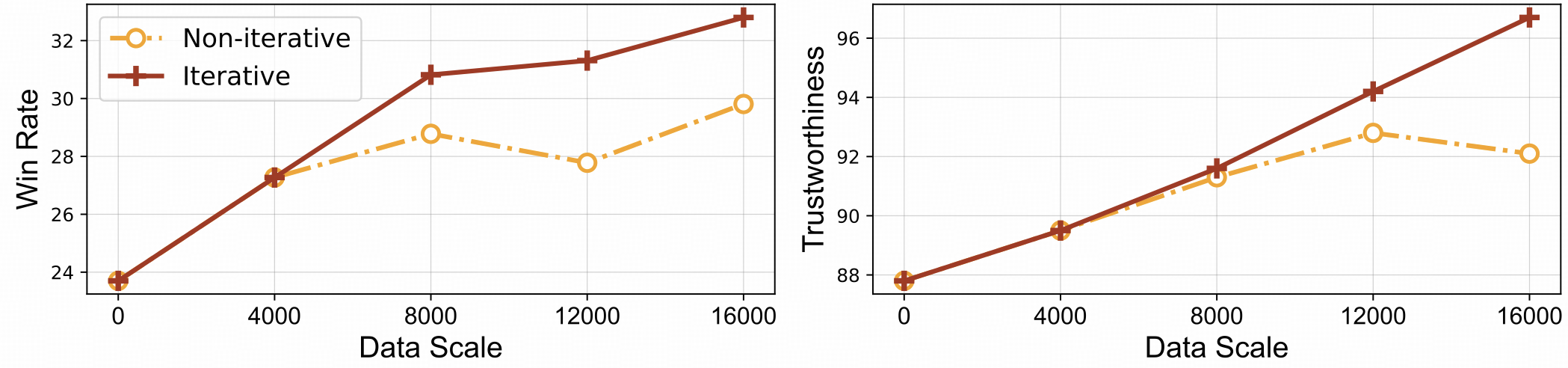
⚡️ Aprendizagem por feedback eficiente com alinhamento iterativo. O RLAIF-V apresenta melhor eficiência de aprendizagem e maior desempenho em comparação com a abordagem não iterativa.
Conjunto de dados
Instalar
Pesos do modelo
Inferência
Geração de dados
Trem
Avaliação
Objeto HalBench
Banco MMHal
RefoMB
Citação
Apresentamos o conjunto de dados RLAIF-V, que é um conjunto de dados de preferências gerado por IA que cobre uma ampla gama de tarefas e domínios. Esses conjuntos de dados de preferências multimodais de código aberto contêm 83.132 pares de comparação de alta qualidade . O conjunto de dados contém os pares de preferências gerados em cada iteração de treinamento de diferentes modelos, incluindo LLaVA 1.5 7B, OmniLMM 12B e MiniCPM-V.
Clone este repositório e navegue até a pasta RLAIF-V
clone git https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
Instalar pacote
conda criar -n rlaifv python=3.10 -y conda ativar rlaifv pip instalar -e.
Instale o modelo spaCy necessário
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip instalar en_core_web_trf-3.7.3.tar.gz
| Modelo | Descrição | Download |
|---|---|---|
| RLAIF-V 7B | A variante mais confiável do LLaVA 1.5 | ? |
| RLAIF-V 12B | Baseado no OmniLMM-12B, alcançando confiabilidade super GPT-4V. | ? |
Fornecemos um exemplo simples para mostrar como usar o RLAIF-V.
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # or 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "Descreva em detalhes as pessoas em a imagem."inputs = {"image": image_path, "question": msgs}answer = chat_model.chat(entradas)print(resposta)Você também pode executar este exemplo executando o seguinte script:
python chat.py

Pergunta:
Por que o carro da foto parou?
Resultados esperados:
Na imagem, um carro parou na estrada devido à presença de uma ovelha na pista. O carro provavelmente parou para permitir que as ovelhas saíssem do caminho com segurança ou para evitar possíveis acidentes com o animal. Esta situação realça a importância de ser cauteloso e atento ao conduzir, especialmente em áreas onde os animais podem circular perto das estradas.
Configuração do ambiente
Fornecemos o modelo OmniLMM 12B e o modelo MiniCPM-Llama3-V 2.5 para geração de feedback. Se você deseja usar o MiniCPM-Llama3-V 2.5 para fornecer feedback, configure seu ambiente de inferência de acordo com as instruções no repositório MiniCPM-V GitHub.
Baixe nossos modelos Llama3 8B ajustados: modelo dividido e modelo de transformação de perguntas e armazene-os na pasta ./models/llama3_split e na pasta ./models/llama3_changeq respectivamente.
Feedback do modelo OmniLMM 12B
O script a seguir demonstra o uso do modelo LLaVA-v1.5-7b para gerar respostas de candidatos e o modelo OmniLMM 12B para fornecer feedback.
mkdir ./resultados bash./script/data_gen/run_data_pipeline_llava15_omni.sh
Feedback do modelo MiniCPM-Llama3-V 2.5
O script a seguir demonstra o uso do modelo LLaVA-v1.5-7b para gerar respostas de candidatos e o modelo MiniCPM-Llama3-V 2.5 para fornecer feedback. Primeiro, substitua minicpmv_python em ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh pelo caminho Python do ambiente MiniCPM-V que você criou.
mkdir ./resultados bash./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
Preparar dados (opcional)
Se você puder acessar o conjunto de dados huggingface, poderá pular esta etapa, faremos o download automaticamente do conjunto de dados RLAIF-V.
Se você já baixou o conjunto de dados, você pode substituir 'openbmb/RLAIF-V-Dataset' pelo caminho do seu conjunto de dados aqui na Linha 38.
Treinamento
Aqui, fornecemos um script de treinamento para treinar o modelo em 1 iteração . O parâmetro max_step deve ser ajustado de acordo com a quantidade de seus dados.
Totalmente ajuste fino
Execute o seguinte comando para iniciar o ajuste completo.
bash ./script/train/llava15_train.sh
LoRA
Execute o seguinte comando para iniciar o treinamento do Lora.
pip instalar peft bash ./script/train/llava15_train_lora.sh
Alinhamento iterativo
Para reproduzir o processo de treinamento iterativo no papel, você precisa executar as seguintes etapas 4 vezes:
S1. Geração de dados.
Siga as instruções na geração de dados para gerar pares de preferências para o modelo base. Converta o arquivo jsonl gerado em parquet huggingface.
S2. Alterar configuração de treinamento.
No código do conjunto de dados, substitua 'openbmb/RLAIF-V-Dataset' aqui pelo seu caminho de dados.
No script de treinamento, substitua --data_dir por um novo diretório, substitua --model_name_or_path pelo caminho do modelo base, defina --max_step como o número de etapas para 4 épocas, defina --save_steps como o número de etapas para 1/4 época .
S3. Faça treinamento DPO.
Execute o script de treinamento para treinar o modelo base.
S4. Escolha o modelo base para a próxima iteração.
Avalie cada ponto de verificação no Object HalBench e MMHal Bench, escolha o ponto de verificação com melhor desempenho como modelo base na próxima iteração.
Preparar anotações COCO2014
A avaliação do Object HalBench depende das anotações de legenda e segmentação do conjunto de dados COCO2014. Primeiro baixe o conjunto de dados COCO2014 do site oficial do conjunto de dados COCO.
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip descompacte annotations_trainval2014.zip
Inferência, avaliação e resumo
Substitua {YOUR_OPENAI_API_KEY} por uma chave de API OpenAI válida.
Nota: A avaliação é baseada em gpt-3.5-turbo-0613 .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}Preparar dados MMHal
Faça download dos dados de avaliação do MMHal aqui e salve o arquivo em eval/data .
Execute o seguinte script para gerar para o MMHal Bench:
Nota: A avaliação é baseada em gpt-4-1106-preview .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}Preparação
Para usar a avaliação GPT-4, primeiro execute pip install openai==0.28 para instalar o pacote openai. Em seguida, altere openai.base e openai.api_key em eval/gpt4.py para sua própria configuração.
Os dados de avaliação do conjunto de desenvolvimento podem ser encontrados em eval/data/RefoMB_dev.jsonl . Você precisa baixar cada imagem da chave image_url em cada linha.
Avaliação para pontuação geral
Salve a resposta do seu modelo na chave answer do arquivo de dados de entrada eval/data/RefoMB_dev.jsonl , por exemplo:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}Execute o seguinte script para avaliar o resultado do seu modelo:
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
Avaliação para pontuação de alucinação
Após avaliar a pontuação geral, um arquivo de resultado da avaliação será criado com o nome A-GPT-4V_B-${model_name}.json . Usando este arquivo de resultados de avaliação para calcular a pontuação de alucinação da seguinte forma:
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_resultNota: Para melhor estabilidade, recomendamos avaliar mais de 3 vezes e usar a pontuação média como pontuação final do modelo.
Avisos de uso e licença : Os dados, o código e o ponto de verificação destinam-se e são licenciados apenas para uso em pesquisa. Eles também estão restritos a usos que seguem o contrato de licença de LLaMA, Vicuna e Chat GPT. O conjunto de dados é CC BY NC 4.0 (permitindo apenas uso não comercial) e os modelos treinados com o conjunto de dados não devem ser usados fora para fins de pesquisa.
RLHF-V: A base de código na qual construímos.
LLaVA: O modelo de instrução e modelo de rotulador de RLAIF-V-7B.
MiniCPM-V: O modelo de instrução e modelo de rotulador do RLAIF-V-12B.
Se você achar nosso modelo/código/dados/artigo útil, considere citar nossos artigos e marcar-nos com uma estrela ️!
@artigo{yu2023rlhf, title={Rlhf-v: Rumo a mllms confiáveis por meio do alinhamento de comportamento a partir de feedback humano correcional refinado}, autor={Yu, Tianyu e Yao, Yuan e Zhang, Haoye e He, Taiwen e Han, Yifeng e Cui, Ganqu e Hu, Jinyi e Liu, Zhiyuan e Zheng, Hai-Tao e Sun, Maosong e outros}, diário = {arXiv pré-impressão arXiv:2312.00849}, ano={2023}}@article{yu2024rlaifv, title={RLAIF-V: Alinhando MLLMs por meio de feedback de IA de código aberto para confiabilidade do Super GPT-4V}, autor={Yu, Tianyu e Zhang, Haoye e Yao, Yuan e Dang, Yunkai e Chen, Da e Lu, Xiaoman e Cui, Ganqu e He, Taiwen e Liu, Zhiyuan e Chua, Tat-Seng e Sun, Maosong}, diário={pré-impressão arXiv arXiv:2405.17220}, ano={2024},
} 

