ChatLM mini Chinese
1.0.0
Chinês | Inglês
Os grandes modelos de linguagem de hoje tendem a ter parâmetros maiores, e os computadores de consumo são mais lentos para realizar inferências simples, quanto mais para treinar um modelo do zero. O objetivo deste projeto é treinar um modelo de linguagem generativa do zero, incluindo limpeza de dados, treinamento de tokenizer, pré-treinamento de modelo, ajuste fino de instrução SFT, otimização RLHF, etc.
ChatLM-mini-Chinese é um pequeno modelo de diálogo chinês com apenas 0,2B de parâmetros de modelo (cerca de 210M incluindo pesos compartilhados). Ele pode ser pré-treinado em uma máquina com no mínimo 4 GB de memória de vídeo ( batch_size=1 , fp16 ou bf16 . ) e o carregamento e a inferência float16 requerem pelo menos 512 MB de memória de vídeo.
Huggingface PNL, incluindo transformers , accelerate , trl , peft , etc.trainer autoimplementado suporta pré-treinamento e ajuste fino de SFT em uma única máquina com um único cartão ou com vários cartões em uma única máquina. Suporta parar em qualquer posição durante o treinamento e continuar o treinamento em qualquer posição.Text-to-Text ponta a ponta e ao pré-treinamento de previsão sem mask .sentencepiece e huggingface tokenizers ;batch_size=1, max_len=320 , o pré-treinamento é suportado em uma máquina com pelo menos 16 GB de memória + 4 GB de memória de vídeo;trainer autoimplementado oferece suporte ao ajuste fino do comando imediato e a qualquer ponto de interrupção para continuar o treinamento;sequence to sequence do Huggingface trainer ;peft lora para otimização de preferências;Lora adapter pode ser mesclado no modelo original.Se você precisar fazer geração aprimorada de recuperação (RAG) com base em modelos pequenos, consulte meu outro projeto Phi2-mini-Chinese. Para o código, consulte rag_with_langchain.ipynb.
? Últimas atualizações
Todos os conjuntos de dados vêm de conjuntos de dados de conversas de rodada única publicados na Internet. Após a limpeza e formatação dos dados, eles são salvos como arquivos parquet. Para o processo de processamento de dados, consulte utils/raw_data_process.py . Os principais conjuntos de dados incluem:
Belle_open_source_1M , train_2M_CN e train_3.5M_CN que possuem respostas curtas, não contêm estruturas de tabela complexas e tarefas de tradução (sem lista de vocabulário em inglês), um total de 3,7 milhões de linhas e 3,38 milhões de linhas permanecem após a limpeza.N palavras da enciclopédia são as respostas. Os dados da enciclopédia de 202309 são usados, e 1,19 milhão de prompts e respostas de entrada permanecem após a limpeza. Download do Wiki: zhwiki, converta o arquivo bz2 baixado em referência wiki.txt: WikiExtractor. O número total de conjuntos de dados é de 10,23 milhões: conjunto de pré-treinamento Text-to-Text: 9,3 milhões, conjunto de avaliação: 25.000 (porque a decodificação é lenta, o conjunto de avaliação não é muito grande). Conjunto de teste: 900.000. Os conjuntos de dados de ajuste fino de SFT e otimização de DPO são mostrados abaixo.
Modelo T5 (Transformador de transferência de texto para texto), para obter detalhes, consulte o artigo: Explorando os limites da aprendizagem por transferência com um transformador de texto para texto unificado.
O código-fonte do modelo vem de huggingface, consulte: T5ForConditionalGeneration.
Consulte model_config.json para configuração do modelo. A T5-base oficial: encoder layer e decoder layer têm 12 camadas. Neste projeto, esses dois parâmetros são modificados para 10 camadas.
Parâmetros do modelo: 0,2B. Tamanho da lista de palavras: 29.298, incluindo apenas chinês e uma pequena quantidade de inglês.
hardware:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 Treinamento do tokenizer : A biblioteca de treinamento tokenizer existente tem um problema de OOM ao encontrar um corpus grande. Portanto, o corpus completo é mesclado e construído com base na frequência das palavras de acordo com um método semelhante ao BPE , que leva meio dia para ser executado.
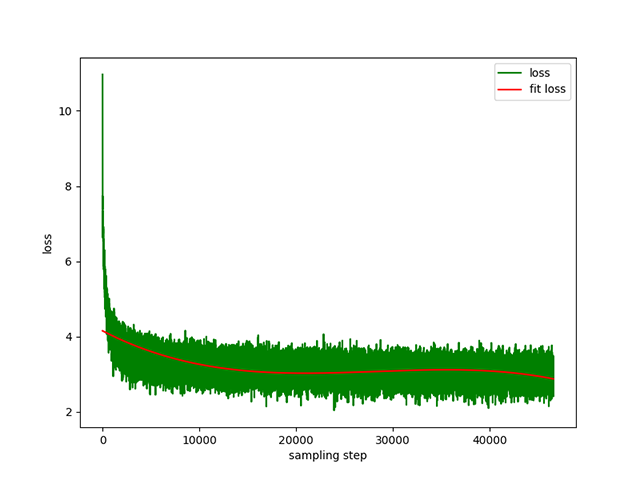
Pré-treinamento Text-to-Text : uma taxa de aprendizagem dinâmica de 1e-4 a 5e-3 e um tempo de pré-treinamento de 8 dias. Perda de treinamento:
belle (os comprimentos de instrução e resposta estão abaixo de 512), a taxa de aprendizado é uma taxa de aprendizado dinâmica de 1e-7 a 5e-5 e o tempo de ajuste fino são 2 dias. Perda de ajuste fino: 
chosen . Na etapa 2 , o lote do modelo SFT generate os prompts no conjunto de dados e obtém o texto rejected . para otimizar a preferência completa do dpo e aprender, a taxa é le-5 , meia precisão fp16 , um total de 2 epoch e leva 3 horas. perda de dpo: 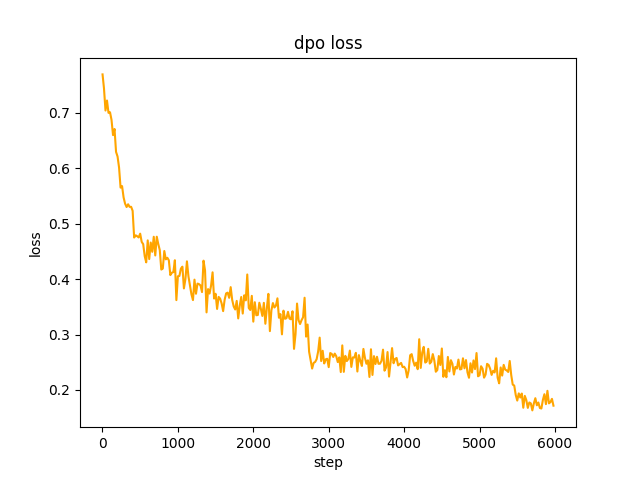
Por padrão, TextIteratorStreamer dos huggingface transformers é usado para implementar o diálogo de streaming, que suporta apenas greedy search . Se você precisar de outros métodos de geração, como beam sample , altere o parâmetro stream_chat de cli_demo.py para False . 

Existem problemas: o conjunto de dados de pré-treinamento tem apenas mais de 9 milhões e os parâmetros do modelo são de apenas 0,2B. Ele não pode cobrir todos os aspectos e haverá situações em que a resposta estará errada e o gerador será um disparate.
Se o huggingface não puder ser conectado, use modelscope.snapshot_download para baixar o arquivo de modelo do modelscope.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Cuidado
O modelo deste projeto é um modelo TextToText No prompt , response e outros campos nas fases de pré-treinamento, SFT e RLFH, certifique-se de adicionar a marca final da sequência [EOS] .
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese É recomendado usar python 3.10 para este projeto. Versões mais antigas do python podem não ser compatíveis com as bibliotecas de terceiros das quais depende.
instalação do pip:
pip install -r ./requirements.txtSe pip instalou a versão CPU do pytorch, você pode instalar a versão CUDA do pytorch com o seguinte comando:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118instalação conda:
conda install --yes --file ./requirements.txt Use o comando git para baixar os pesos do modelo e os arquivos de configuração do Hugging Face Hub . Você precisa primeiro instalar o Git LFS e depois executar:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save Você também pode baixá-lo manualmente diretamente do armazém ChatLM-Chinese-0.2B Hugging Face Hub e mover o arquivo baixado para o diretório model_save .
Os requisitos do corpus devem ser tão completos quanto possível. Recomenda-se adicionar múltiplos corpora, como enciclopédias, códigos, artigos, blogs, conversas, etc.
Este projeto é baseado principalmente na enciclopédia chinesa wiki. Como obter o corpus wiki chinês: Endereço de download do Wiki chinês: zhwiki, baixe o arquivo zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 , cerca de 2,7 GB, converta o arquivo bz2 baixado em referência wiki.txt: WikiExtractor, Em seguida, use a biblioteca OpenCC do python para convertê-lo para chinês simplificado e, finalmente, coloque o wiki.simple.txt obtido no diretório data do diretório raiz do projeto. Por favor, mescle vários corpora em um arquivo txt .
Como o tokenizador de treinamento consome muita memória, se o seu corpus for muito grande (o arquivo txt mesclado excede 2G), é recomendável amostrar o corpus de acordo com categorias e proporções para reduzir o tempo de treinamento e o consumo de memória. Treinar um arquivo txt de 1,7 GB requer cerca de 48 GB de memória (estimado, só tenho 32 GB, a troca é acionada com frequência, o computador fica travado por muito tempo T_T) e a CPU de 13600k leva cerca de 1 hora.
A diferença entre char level e byte level é a seguinte (procure informações por conta própria para diferenças específicas de uso). O tokenizer treina char level por padrão. Se byte level for necessário, basta definir token_type='byte' em train_tokenizer.py .
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']Comece a treinar:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab ou caderno jupyter:
Veja o arquivo train.ipynb . É recomendado usar jupyter-lab para evitar considerar a situação em que o processo do terminal é encerrado após a desconexão do servidor.
Console:
O treinamento do console precisa considerar que o processo será encerrado após a desconexão da conexão. Recomenda-se usar a ferramenta Supervisor ou screen do daemon de processo para estabelecer uma sessão de conexão.
Primeiro, você precisa configurar accelerate , executar o seguinte comando e selecionar de acordo com os accelerate.yaml . Nota: DeepSpeed é mais problemático para instalar no Windows .
accelerate config Comece o treinamento. Se você deseja usar a configuração fornecida pelo projeto, adicione o parâmetro --config_file ./accelerate.yaml após o seguinte comando accelerate launch . Esta configuração é baseada na configuração 2xGPU de máquina única.
Existem dois scripts para pré-treinamento. O treinador implementado neste projeto corresponde a train.py e o treinador implementado por huggingface corresponde a pre_train.py . O treinador implementado neste projeto exibe informações de treinamento mais bonitas e facilita a modificação dos detalhes do treinamento (como funções de perda, registros de log, etc.). Todos os pontos de interrupção de suporte para continuar o treinamento. ponto de interrupção em qualquer posição. Pressione ctrl+c para salvar as informações do ponto de interrupção ao sair do script.
Máquina única e cartão único:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py Máquina única com vários cartões: 2 é o número de placas gráficas, modifique-o de acordo com sua situação real.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyContinue treinando a partir do ponto de interrupção:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyTodo o conjunto de dados SFT vem da contribuição do chefe BELLE, obrigado. Os conjuntos de dados SFT são: generate_chat_0.4M, train_0.5M_CN e train_2M_CN, com aproximadamente 1,37 milhão de linhas restantes após a limpeza. Exemplo de ajuste fino do conjunto de dados com o comando sft:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} Crie seu próprio conjunto de dados consultando o arquivo parquet de amostra no diretório data . O formato do conjunto de dados é: parquet é dividido em duas colunas, uma coluna de texto prompt , que representa o prompt, e uma coluna de texto de response , que representa a saída esperada do modelo. Para obter detalhes de ajuste fino, consulte o método train em model/trainer.py . Quando is_finetune estiver definido como True , o ajuste fino será executado para congelar a camada de incorporação e a camada do codificador por padrão e treinar apenas o decodificador. camada. Se você precisar congelar outros parâmetros, ajuste você mesmo o código.
Execute o ajuste fino do SFT:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyAqui estão dois métodos preferenciais comuns: PPO e DPO. Pesquise artigos e blogs para implementações específicas.
Método PPO (otimização de preferência aproximada, otimização de política proximal)
Etapa 1: Use o conjunto de dados de ajuste fino para fazer o ajuste fino supervisionado (SFT, Supervised Finetuning).
Etapa 2: Use o conjunto de dados de preferência (um prompt contém pelo menos 2 respostas, uma resposta desejada e uma resposta indesejada. Múltiplas respostas podem ser classificadas por pontuação, e a mais procurada tem a pontuação mais alta) para treinar o modelo de recompensa (RM , Modelo de recompensa). Você pode usar a biblioteca peft para construir rapidamente o modelo de recompensa Lora.
Etapa 3: Use RM para realizar treinamento PPO supervisionado no modelo SFT para que o modelo atenda às preferências.
Use o ajuste fino DPO (Direct Preference Optimization) ( este projeto usa o método de ajuste fino DPO, que economiza memória de vídeo ). Com base na obtenção do modelo SFT, não há necessidade de treinar o modelo de recompensa para obter respostas positivas (). escolhido) e respostas negativas (rejeitado) para iniciar o ajuste fino. O texto chosen com ajuste fino vem do conjunto de dados original alpaca-gpt4-data-zh, e o texto rejected vem da saída do modelo após o ajuste fino do SFT para 1 época. Os outros dois conjuntos de dados: huozi_rlhf_data_json e rlhf-reward-. single-round-trans_chinese, após a fusão Um total de 80.000 dados dpo.
Para o processo de processamento do conjunto de dados dpo, consulte utils/dpo_data_process.py .
Exemplo de conjunto de dados de otimização de preferência DPO:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}Execute a otimização de preferência:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py Certifique-se de que haja os seguintes arquivos no diretório model_save . Esses arquivos podem ser encontrados no armazém Hugging Face Hub ChatLM-Chinese-0.2B:
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
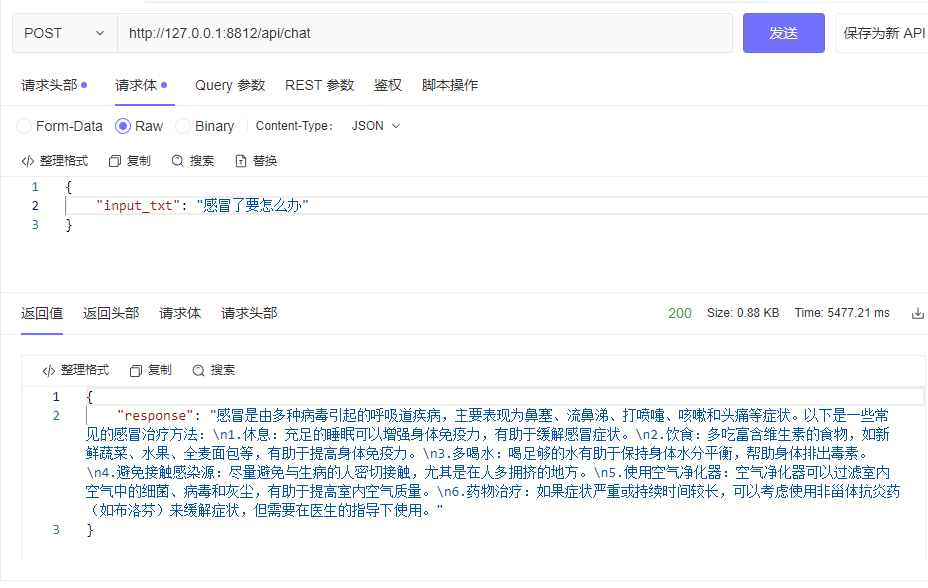
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyExemplo de chamada de API:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
Aqui tomamos as informações do trio no texto como um exemplo para fazer o ajuste fino posterior. Para o método tradicional de extração de aprendizagem profunda para esta tarefa, consulte o warehouse pytorch_IE_model. Extraia todos os triplos em um trecho de texto, como a frase 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, extraia os triplos (写生随笔,作者,张来亮) e (写生随笔,出版社,冶金工业) .
O conjunto de dados original é: conjunto de dados de extração tripla do Baidu. Exemplo do formato do conjunto de dados processado e ajustado:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} Você pode usar diretamente o script sft_train.py para ajuste fino. O script finetune_IE_task.ipynb contém o processo de decodificação detalhado. O conjunto de dados de treinamento possui cerca de 17000 itens, a taxa de aprendizado 5e-5 e a época de treinamento 5 . As capacidades de diálogo de outras tarefas não desapareceram após o ajuste fino.

Efeito de ajuste fino: use o conjunto de dados dev publicado百度三元组抽取数据集como conjunto de teste para comparar com o método tradicional pytorch_IE_model.
| Modelo | Pontuação F1 | Precisão P | Lembre-se de R |
|---|---|---|---|
| Ajuste fino de ChatLM-Chinês-0.2B | 0,74 | 0,75 | 0,73 |
| ChatLM-Chinese-0.2B sem pré-treinamento | 0,51 | 0,53 | 0,49 |
| Métodos tradicionais de aprendizagem profunda | 0,80 | 0,79 | 80,1 |
Nota: ChatLM-Chinese-0.2B无预训练significa inicializar diretamente parâmetros aleatórios e iniciar o treinamento com uma taxa de aprendizado de 1e-4 . Outros parâmetros são consistentes com o ajuste fino.
O modelo em si não é treinado usando um conjunto de dados maior, nem é ajustado para as instruções para responder a questões de múltipla escolha. A pontuação C-Eval é basicamente um nível de referência e pode ser usada como referência, se necessário. Código de avaliação C-Eval, consulte: eval/c_eavl.ipynb
| categoria | correto | question_count | precisão |
|---|---|---|---|
| Humanidades | 63 | 257 | 24,51% |
| Outro | 89 | 384 | 23,18% |
| TRONCO | 89 | 430 | 20,70% |
| Ciências Sociais | 72 | 275 | 26,18% |
Se você acha que este projeto é útil para você, cite-o.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
Este projeto não assume os riscos e responsabilidades de segurança de dados e riscos de opinião pública causados por modelos e códigos de código aberto, ou os riscos e responsabilidades decorrentes de qualquer modelo ser enganado, abusado, disseminado ou explorado indevidamente.


