lance
v0.20.0

Formato de dados colunares moderno para ML. Converta do Parquet em 2 linhas de código para acesso aleatório 100x mais rápido, um índice vetorial, controle de versão de dados e muito mais.
Compatível com pandas, DuckDB, Polars e pyarrow com mais integrações a caminho.
Documentação • Blog • Discord • Twitter
Lance é um formato de dados colunares moderno otimizado para fluxos de trabalho e conjuntos de dados de ML. Lance é perfeito para:
Os principais recursos do Lance incluem:
Acesso aleatório de alto desempenho: 100x mais rápido que o Parquet sem sacrificar o desempenho da digitalização.
Pesquisa vetorial: encontre os vizinhos mais próximos em milissegundos e combine consultas OLAP com pesquisa vetorial.
Controle de versão automático e sem cópia: gerencie versões de seus dados sem precisar de infraestrutura extra.
Integrações de ecossistemas: Apache Arrow, Pandas, Polars, DuckDB e muito mais a caminho.
Dica
Lance está em desenvolvimento ativo e agradecemos contribuições. Consulte nosso guia de contribuição para obter mais informações.
Instalação
pip install pylancePara instalar uma versão prévia:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceDica
As versões prévias são lançadas com mais frequência do que as versões completas e contêm os recursos e correções de bugs mais recentes. Eles recebem o mesmo nível de testes que as versões completas. Garantimos que permanecerão publicados e disponíveis para download por pelo menos 6 meses. Quando você quiser fixar em uma versão específica, prefira uma versão estável.
Convertendo para Lance
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )Lendo dados do Lance
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )Pandas
df = dataset . to_table (). to_pandas ()
dfPatoDB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()Pesquisa vetorial
Baixe o subconjunto sift1m
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzConverta-o para Lance
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )Construa o índice
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQPesquise o conjunto de dados
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| Diretório | Descrição |
|---|---|
| ferrugem | Implementação do Core Rust |
| píton | Ligações Python (pyo3) |
| documentos | Fonte de documentação |
Aqui destacaremos alguns aspectos do design de Lance. Para obter mais detalhes, consulte o documento completo de design do Lance.
Índice vetorial : índice vetorial para pesquisa de similaridade no espaço de incorporação. Suporta CPUs ( x86_64 e arm ) e GPU ( Nvidia (cuda) e Apple Silicon (mps) ).
Codificações : para obter varredura colunar rápida e consultas de pontos sublineares, Lance usa codificações e layouts personalizados.
Campos aninhados : o Lance armazena cada subcampo como uma coluna separada para suportar filtros eficientes como “encontrar imagens onde os objetos detectados incluem gatos”.
Controle de versão : um manifesto pode ser usado para registrar instantâneos. Atualmente oferecemos suporte à criação automática de novas versões por meio de acréscimos, substituições e criação de índices.
Atualizações rápidas (ROADMAP): As atualizações serão suportadas por meio de logs write-ahead.
Índices secundários ricos (ROADMAP):
Usamos o conjunto de dados SIFT para comparar nossos resultados com vetores 1M de 128D
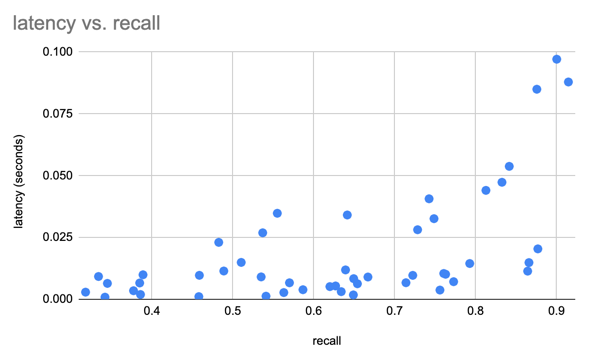
Criamos um conjunto de dados Lance usando o conjunto de dados Oxford Pet para fazer alguns testes preliminares de desempenho do Lance em comparação com Parquet e imagens/XMLs brutos. Para consultas analíticas, Lance é 50-100x melhor do que ler metadados brutos. Para acesso aleatório em lote, o Lance é 100x melhor que arquivos parquet e raw.

O ciclo de desenvolvimento de aprendizado de máquina envolve as etapas:
gráfico LR
A[Coleção] --> B[Exploração];
B --> C[Análise];
C --> D[Engenheiro de Recursos];
D --> E[Treinamento];
E --> F[Avaliação];
F --> C;
E --> G[Implantação];
G --> H[Monitoramento];
H --> UMA;
As pessoas usam diferentes representações de dados em estágios variados de desempenho ou limitadas pelas ferramentas disponíveis. A academia usa principalmente XML/JSON para anotações e dados compactados de imagens/sensores para aprendizado profundo, que é difícil de integrar à infraestrutura de dados e lento para treinar no armazenamento em nuvem. Embora a indústria utilize data lakes (técnicas baseadas em Parquet, ou seja, Delta Lake, Iceberg) ou data warehouses (AWS Redshift ou Google BigQuery) para coletar e analisar dados, eles precisam converter os dados em formatos fáceis de treinar, como Rikai/ Petastorm ou TFRecord. Múltiplas transformações de dados de propósito único, bem como a sincronização de cópias entre armazenamento em nuvem e instâncias de treinamento locais, tornaram-se uma prática comum.
Embora cada um dos formatos de dados existentes seja excelente na carga de trabalho para a qual foi originalmente projetado, precisamos de um novo formato de dados adaptado para ciclos de desenvolvimento de ML em vários estágios para reduzir os silos de dados.
Uma comparação de diferentes formatos de dados em cada estágio do ciclo de desenvolvimento de ML.
| Lança | Parquete e ORC | JSON e XML | Registro TF | Banco de dados | Armazém | |
|---|---|---|---|---|---|---|
| Análise | Rápido | Rápido | Lento | Lento | Decente | Rápido |
| Engenharia de recursos | Rápido | Rápido | Decente | Lento | Decente | Bom |
| Treinamento | Rápido | Decente | Lento | Rápido | N / D | N / D |
| Exploração | Rápido | Lento | Rápido | Lento | Rápido | Decente |
| Suporte de infra-estrutura | Rico | Rico | Decente | Limitado | Rico | Rico |
Lance é atualmente usado na produção por:


